Description
I have the case that my consumers receives protobuf encoded messages, so I need to pass Buffers as job's data. I saw at #1198 that bull uses JSON.stringify/parse, and have ioredis as dependency. ioredis supports passing/receiving buffers to/from Redis, so is there any particular reason to not support buffers as data?
Bull version
3.10.0
 vflopes
vflopes
All 9 comments
Hi! It's always better to keep input/output data of background jobs small, generally for performance and stability reasons. If this is not true for your binary data, encode it into base64 string; it will add just 33% of overhead. Another good reason to go this way is that you can always add additional job parameters in future.
But large chunks should be stored in persistent storages — filesystem, database, cloud, etc, and use URL or any other identifier so that job can download data before processing.
 stansv
on 4 Aug 2019
stansv
on 4 Aug 2019
Hi @stansv , I understand, but actually, protobuf encoded messages are smaller than JSON strings, and for performance, protobuf.js encodes/decodes faster than JSON.stringify/parse.
And this statement:
It's always better to keep input/output data of background jobs small
Contradicts this solution:
encode it into base64 string; it will add just 33% of overhead.
But I understand this is a great change on Bull, I'll use a solution based on Redis Streams that already do what Bull does but with other data structures! Thank you!
vflopes
on 4 Aug 2019
@vflopes I think @stansv meant that if you really need to use binary you can use base64, but it is better to avoid it if you can.
Regarding protobuf, they are not really faster than JSON parse/encode, not in javascript at least: https://github.com/sqfasd/node-serialization-benchmark
I did some benchmarks myself not only with protobuf but other formats too, see if it was possible to beat json so that bull could be event faster, however nothing was that fast, I guess json is super optimized since it is such a fundamental data format in javascript.
However, being able to store data in other formats is a nice addition and we will probably add it to bull 4.x.
 manast
on 4 Aug 2019
manast
on 4 Aug 2019
Well, we must always be careful with benchmarks (I agree that not always protobuf encoding/decoding will be faster), but lets see some results:
1 - I downloaded the repository that you mentioned, it's very outdated, protobuf.js is at v6.8.8 and the project refers to v^4.1.3, so I updated to the latest stable version.
2 - The payload is too small and doesn't have nested data structures, to be close to my case, I changed the payload and the proto to the following content:
syntax = "proto3";
message Test {
string string = 1;
uint32 uint32 = 2;
Inner inner = 3;
float float = 4; // make sure to set something that's fair to JSON
message Inner {
int32 int32 = 1;
InnerInner innerInner = 2;
Outer outer = 3;
message InnerInner {
int64 long = 1;
Enum enum = 2;
sint32 sint32 = 3;
}
}
enum Enum {
ONE = 0;
TWO = 1;
THREE = 2;
FOUR = 3;
FIVE = 4;
}
}
message Outer {
repeated bool bool = 1;
double double = 2; // make sure to set something that's fair to JSON
}
{
"string" : "Lorem ipsum dolor sit amet.",
"uint32" : 9000,
"inner" : {
"int32" : 20161110,
"innerInner" : {
"long" : {
"low": 1051,
"high": 151234,
"unsigned": false
},
"enum" : 1,
"sint32": -42
},
"outer" : {
"bool" : [ true, false, false, true, false, false, true ],
"double": 204.8
}
},
"float": 0.25
}
3 - Here are the results for 100000 iterations:
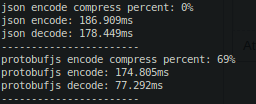
4 - Think about networking latency, from faster to slower resource the list would be: CPU > Memory > Network, a payload 69% smaller can really make the difference on performance, even if there's a trade-off on CPU encoding/decoding algorithms.
As I said, I know there're optimizations triggered on V8's JSON serialization engine for small payloads, but thinking about the context of sending payloads through network we're just looking at the most optimized part of the flow :smile:
vflopes
on 4 Aug 2019
thanks for taking the time to make a new test. With these results I will prioritise custom serialisers in bull 4 so that we can take advantage of different serialisers when it make sense.
manast
on 4 Aug 2019
@manast If you need help, let me know! I don't know if there're plans to use Redis Streams too, but if you need to work with them, I can help :+1:
vflopes
on 4 Aug 2019
we use redis streams for events in bull 4, works really well: https://github.com/taskforcesh/bullmq/pull/1
manast
on 4 Aug 2019
@vflopes, sorry for confusion! 🤕 I meant that if your binary data is _small_ enough, you can safely serialize into base64..
I like the idea of custom serializers too
stansv
on 5 Aug 2019
@stansv no worries man! I'm working on my project HFXBus. It's a different approach from Bull, only using Redis Streams to send jobs and simple keys to store data (:
vflopes
on 5 Aug 2019
Related issues
 pintocarlos
·
3Comments
pintocarlos
·
3Comments
 JSRossiter
·
3Comments
JSRossiter
·
3Comments
 sibelius
·
3Comments
sibelius
·
3Comments
 inn0vative1
·
4Comments
inn0vative1
·
4Comments
 pigaov10
·
3Comments
pigaov10
·
3Comments
Most helpful comment
thanks for taking the time to make a new test. With these results I will prioritise custom serialisers in bull 4 so that we can take advantage of different serialisers when it make sense.