Borg: Borg may restore corrupt files without noticing
Please close this report if I am wrong in the following assumption: after restoring some file Borg doesn't compute checksum (say, SHA256) over the whole file to validate its integrity, instead such integrity is _derived_ from individual chunk integrity and the integrity of Borg internal data structures.
I assume so because otherwise first read() operation of any byte via BorgFS would require restoring whole file and computing its SHA. I also grepped the code and had an impression that my assumption is correct.
If so then suppose we backup some file whose chunk representation is C1 C2 C3. We compute Key1 = MAC(C1), Key2 = MAC(C2), Key2 = MAC(C3). Key2 is found in cache, because there was some _other_ chunk C42 that happens to have MAC(C42) == Key2, so on restore we'll get C1 C42 C3 (such restoration won't trigger IntegrityError, nor would the problem be found with check operation). Also note than once there, such corruption may penetrate any number of time slices and any number of files with affected C2 chunk.
Yes, we all know that while theoretical collisions are _guaranteed_, the probability of such a collision to actually happen is _extremely low_. However here are some popular but wrong assumptions:
- it won't happen in foreseeable future
- there are billions of people on Earth, it won't happen to me
- "You were right, it happened yesterday to George! So the _next_ collision is far in the future!"
Here are some correct assuptions:
- it can happen tomorrow
- it can happen to me
- _it could have happen to me already, I just didn't notice it yet_ (there are much more backup operations then there are restore operations, and users trust Borg and do not verify integrity by external means)
Unless Borg truly follows Horton Principle and authenticates/verifies file as a whole, someone out there may end up restoring executable with a random code injection, or simply loosing their precious selfies.
My humble estimation is that data integrity is way more important than performance of BorgFS, so SHA must be validated on restored files. Until such verification is implemented please update the docs to clearly warn users of potential risks.
 kroki
kroki
All 11 comments
Borg does not handle hash collisions. We use 256bit cryptographic hashes / MACs (they are also the address/key to store data into the key-value store).
Most users can live with that as the probability of such an event is so low they can ignore it.
If you can't, you can't use borg.
There is already another ticket #170 about how low the probability is, so I won't discuss this again in here.
 ThomasWaldmann
on 17 Dec 2019
ThomasWaldmann
on 17 Dec 2019
We also do not compute / store a full-file hash when creating an archive as that would slow down borg significantly. Currently it is just 1 thread and everything is rather sequential.
Maybe we could implement that after multithreading is implemented and we have more cores to make use of. There is already another ticket about multithreading.
ThomasWaldmann
on 17 Dec 2019
As the hash collision topic pops up now and then, maybe somebody should dig out the probability info from that other ticket and write a FAQ entry with it (if we do not already have that).
ThomasWaldmann
on 17 Dec 2019
There is already another ticket #170 about how low the probability is, so I won't discuss this again in here.
Thanks for the pointer I read through that.
I guess you'll have a lot of other problems _before_ that happens, right?
Sorry, I don't see any understanding of probabilities in statements like this. Plus the real question is not whether it happens, but what you will do when it happens.
_... as that would slow down borg significantly._
One could suggest yet another optimization: do not store _all_ the data that user backups, as this would require too much space. Just estimate the probability that the user will ever restore a particular file she backups ;).
Hope the above will be taken lightly. I see your point, every project has its own assumptions about the Universe and design decisions that follow from that.
kroki
on 18 Dec 2019
I'll summarize here what I learned from #170:
Both proponents and opponents of collision awareness in Borg agree that the probability of the event is extremely low. No matter how precisely it is calculated for proponents it is high enough (non-zero thus potentially realizable), while for opponents it is too small to bother (though some misinterpretations lead some of them to think that it "won't happen soon").
Borg developers entirely(?) belong to opponents camp, while proponents are divided into two camps: _strong_ collision awareness and _weak_ collision awareness.
_Strong_ collision awareness would require Borg to store colliding chunks in repo and restore them correctly. This, however, is impossible with Borg by design: given the same key Borg is unable to disambiguate colliding chunks, thus can't neither restore correctly nor even store them in repo without superseding one with the other. Users wishing strong collision awareness are advised to use other solutions with, for instance, _full/incremental_ backup scheme support (Duplicity?), where "full" backup is not deduplicated (even against itself), thus guaranteeing intact data at least at that point. The downside is a larger repo space requirement (at least two full backups must be stored at some point).
_Weak_ collision awareness just requires that Borg would notice if collision has happened to avoid potential subtle file corruption on restore (the file still be corrupt, but at least the user will know this). This may be provided in two ways:
- compute full file checksum during backup and store it in the repo for verification at any later moment. Sister Restic issue lists additional uses for such checksums. However to be fair even said sister bug doesn't mention collision as a possibility, and collision awareness opponents may object on the grounds that
H(H(chunk1)||...||H(chunkN))is _almost_ the same asH(chunk1||...||chunkN).
- during backup fetch corrsponding chunk from repo and perform bit-by-bit comparison before deciding that new chunk is indeed a duplicate, aborting if not (suggesting the user to claim her money prize for finding real-world HMAC collision). This will slow backup creation even more than with computing checksums, but won't require to store any additional information in the repo, and can be implemented as an _option_ and won't affect those who believe they do not need such check. Implementation will simply combine the functionality of backup and restore/BorgFS, hence shouldn't meet strong objections from Borg developers ones _proponents provide the patch_ to implement such an option (Borg developers do not have to implement a feature they don't have faith in).
In any case, documentation should be clear about integrity guarantees Borg provides.
kroki
on 21 Dec 2019
Both proponents and opponents of collision awareness in Borg agree that the probability of the event is extremely low.
True, but not quite correct - as I revealed in https://github.com/borgbackup/borg/issues/170#issuecomment-568156845 and my small PoC which is calculative as well as experimental, the chance of collision is directly proportional to the size of the chunk (and not only to the number of input chunks), so it grows significantly with the huge increase in amount of ALL chunks that are possible (which is directly depending on the size of a chunk, namely exponential).
And that is definitely not "k²/2N" (where even related to birthday paradox it is a huge order of magnitude larger, because it rather operates with number 2N/2 to ensure a hash match with even chance)... But that also means a generalized solution and its Poisson distribution of a binomial does not consider the size of the hashed chunk (which will be important if it grows).
But now we come to the quality of the dataset (chunks):
the SHA-functions belong practically to the same class as a simple summator (an adder modulo 2N) and the mixing of bits serves only the cryptographic purposes.
Thus during the compression of the large chunk a lot of bits is naturally lost. But the question of how substantially the type of chunk is affecting the significant bits (the loss during compression) is still there.
This effect (mostly negative regarding the collision's probability) is also proven by dozen of works and experiments.
Because the chunks are not random data (but plaintext, zip archives, whatever else with certain structure) it opens this other direction of hash quality injury. And neither HMAC nor other mixing algorithms can ever change that, so it can't prevent against this effect during compression process (it makes the hash just more "secure", so it only avoids a brute-force etc, but as already mentioned it's not interesting in our case - by the usage as an unique ID or as a lookup key in the table).
I'm done too :)
 sebres
on 21 Dec 2019
sebres
on 21 Dec 2019
@ThomasWaldmann
As the hash collision topic pops up now and then, maybe somebody should dig out the probability info from that other ticket and write a FAQ entry with it (if we do not already have that).
Do you mean this?
AFAIK, hash collisions start becoming a real problem if the number of hashes is about 2 ^ (N/2) with N being the bit length of the hash. So for sha256 that is 2 ^ 128 hashes. Each chunk is about 2^16 bytes (default, or likely bigger if you backup a lot of data and adapt --chunker-params). So this means that we talk about 2^144 Bytes of data in your backup. In decimal, that is a 1 followed by 43 zeros.
 fantasya-pbem
on 19 Apr 2020
fantasya-pbem
on 19 Apr 2020
That's at least outdated concerning the chunk size, which is now 2^20 bytes by default.
I'ld like this PR done by somebody who's actually good enough in math/crypto to verify this first.
ThomasWaldmann
on 19 Apr 2020
As many times mentioned above 2N/2 is a generalized solution of birthday paradox for occurring a collision with even chance.
Let us drop the matter of distribution quality etc, and remain by a chance. So 50% is not necessarily a minimum chance where one could say it is acceptable and the backup is safe. I'd try to explain it with the illustration (where you can also surely recognize the common picture of BP):
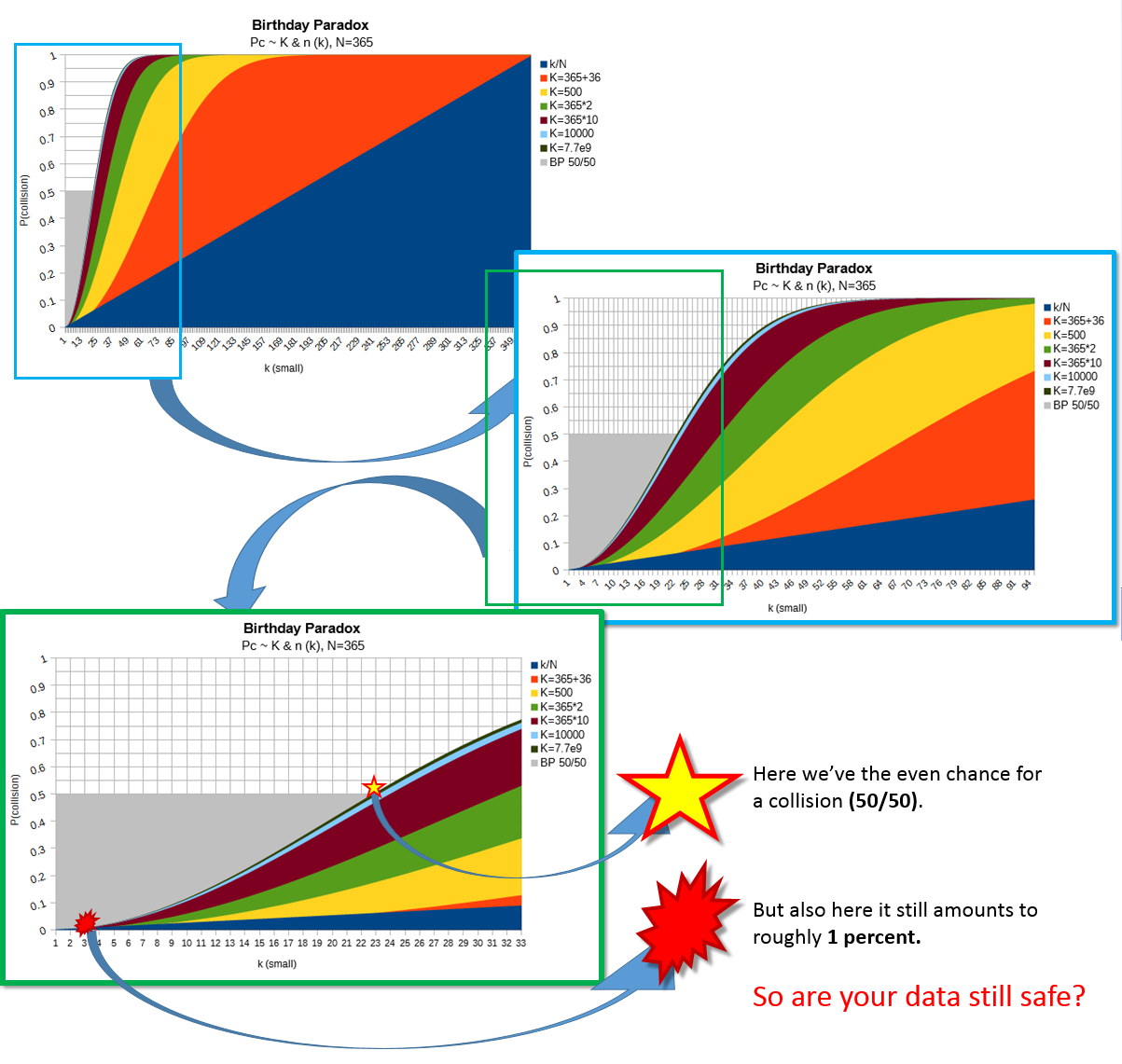
So looking at the last zoom and the red point on the curve (by P = 1%) can you say how small should be the probability to be still acceptable for the backup consistency, and then estimate how large the resulting N should be to avoid this (even minimal chance) completely?
sebres
on 20 Apr 2020
According to Birthday attack on Wikipedia, assuming evenly distribution, for SHA256 there is a chance of 10-18 if more than 4.8 · 1029 hashes are used. For a chunk size of 220 Bytes, this is 5 · 1035 Bytes of chunk size total or more than 4 · 1023 Terabytes.
fantasya-pbem
on 20 Apr 2020
Maybe (just birthday attack targeting a bit different purposes)...
but don't forget that also this is valid for ideal case - good distributed hash function (this is extremely dataset related value) and almost random data (which normally backup-data is not).
For instance (artificial case) if I use as a hash-function something like H(v) = v % 2**256,
I'll get a collision by a dataset with 2 values 1 and 1+2**256 represented as 2 integers stored in 32-bytes.
Again 2 chunks each 32 bytes long.
And changing of the function does not really matter (if a result is used for identifying purposes) as long as the size of this function remains the same.
So 4e23 TB is "good" estimation... in some ideal case... as well as that this would "contain" many data that neither be stored ever (nor hashed) in the practice, what does not mean hashing function would work over this abstract data and doesn't exclude at all a collision chance for real data in this dataset...
So to consider that value in case of some abstract data is at least strange.
Anyway related to this table, we'd catch a collision by 2.6*1010 random values in case of 128-bits hash function with this microscopic probability: P=10-18...
The case is - I got it already several times (as well as many others testing or estimating distribution quality of a hash functions on some real data sets).
For example my latest test estimating a distribution quality for 128-bit hash function over file names (paths) in a database containing indexed documents (used to hold image data of file spider) found a collision by few millions documents (in spite of this microscopic chance).
I'll just say - if some estimated collision resistance is good enough to use that for example as an uncorrectable error rate (e. g. like a checksum etc) or as a cryptographic key or signature, this still does not mean it is good enough to use that as an unique identifier.
The purposes of use (as well as the effects after occurrence) are totally different.
sebres
on 20 Apr 2020
Related issues
 rugk
·
5Comments
rugk
·
3Comments
rugk
·
4Comments
rugk
·
5Comments
rugk
·
3Comments
rugk
·
4Comments
 anarcat
·
4Comments
anarcat
·
4Comments
 auanasgheps
·
5Comments
auanasgheps
·
5Comments
Most helpful comment
I'll summarize here what I learned from #170:
Both proponents and opponents of collision awareness in Borg agree that the probability of the event is extremely low. No matter how precisely it is calculated for proponents it is high enough (non-zero thus potentially realizable), while for opponents it is too small to bother (though some misinterpretations lead some of them to think that it "won't happen soon").
Borg developers entirely(?) belong to opponents camp, while proponents are divided into two camps: _strong_ collision awareness and _weak_ collision awareness.
_Strong_ collision awareness would require Borg to store colliding chunks in repo and restore them correctly. This, however, is impossible with Borg by design: given the same key Borg is unable to disambiguate colliding chunks, thus can't neither restore correctly nor even store them in repo without superseding one with the other. Users wishing strong collision awareness are advised to use other solutions with, for instance, _full/incremental_ backup scheme support (Duplicity?), where "full" backup is not deduplicated (even against itself), thus guaranteeing intact data at least at that point. The downside is a larger repo space requirement (at least two full backups must be stored at some point).
_Weak_ collision awareness just requires that Borg would notice if collision has happened to avoid potential subtle file corruption on restore (the file still be corrupt, but at least the user will know this). This may be provided in two ways:
H(H(chunk1)||...||H(chunkN))is _almost_ the same asH(chunk1||...||chunkN).In any case, documentation should be clear about integrity guarantees Borg provides.