Bert: I'm getting key error '2' when i run run_classifier.py
I got key error 2 when I ran run_classifier.py on my train.tsv file. I'm unable to figure out what could possibly be the reason for this error ? Could someone please help me fix this.
The error that i encountered is exactly :
INFO:tensorflow:_TPUContext: eval_on_tpu True
WARNING:tensorflow:eval_on_tpu ignored because use_tpu is False.
INFO:tensorflow:Writing example 0 of 13
INFO:tensorflow:* Example *
INFO:tensorflow:guid: train-0
INFO:tensorflow:tokens: [CLS] a [SEP]
INFO:tensorflow:input_ids: 101 1037 102 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
INFO:tensorflow:input_mask: 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
INFO:tensorflow:segment_ids: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
INFO:tensorflow:label: 1 (id = 1)
Traceback (most recent call last):
File "bert/run_classifier.py", line 981, in
tf.app.run()
File "/home/sneha/anaconda3/lib/python3.6/site-packages/tensorflow/python/platform/app.py", line 125, in run
_sys.exit(main(argv))
File "bert/run_classifier.py", line 870, in main
train_examples, label_list, FLAGS.max_seq_length, tokenizer, train_file)
File "bert/run_classifier.py", line 490, in file_based_convert_examples_to_features
max_seq_length, tokenizer)
File "bert/run_classifier.py", line 459, in convert_single_example
label_id = label_map[example.label]
KeyError: '2'
Thanks in advance !!
 sneharaogr
sneharaogr
All 11 comments
You are getting this error because the format of your train.tsv is incompatible with the task_name argument you specified for task classifier. Make sure the format of your train.tsv is compatible with the data processor associated with whatever task_name you specified.
 hsm207
on 28 Mar 2019
hsm207
on 28 Mar 2019
@hsm207 @Sneha-Rao-GR
I had a similar issue once. I feel that the issue is not necessarily because of the data format.
In my case I had training data in the format of:
<ID> <LABEL> <THROW_AWAY> <SENTENCE>
0 1 a 'Some random sentence'
Yet, I had this issue. After bit of digging, I realized that the run_classifier file is configured by default to work with binary classification, so when the classifier comes across any label beyong 0 or 1 it throws an error for obvious reasons, because of the way it's get_label function is coded.
So, go to -> BERT BASE FOLDER - > run_classifier.py - > get_label function and change it from:
def get_labels(self):
"""See base class."""
return ["0", "1"]
to
def get_labels(self):
"""See base class."""
return ["0", "1", "2", "3", "4", "5", "6", "7"] # How many ever distinct labels you have in your data set
I Hope it helps.
 amithadiraju1694
on 19 Jun 2019
amithadiraju1694
on 19 Jun 2019
@amit8121 - Your comment solved the problem for me. Thanks a million!
 p4rk3r
on 1 Dec 2019
p4rk3r
on 1 Dec 2019
@amit8121 - Your comment solved the problem for me. Thanks a million!
Glad I could help.
amithadiraju1694
on 2 Dec 2019
@amit8121 - how would you solve the same in bert pretrained model?
 JainAnvitha
on 7 Dec 2019
JainAnvitha
on 7 Dec 2019
I am using tfhub module similar to the one in BERT repo example but I have used similar code snippet of train_features for generating test_features also because I have text_b content which is not none in my case. But I am getting a key error 0. I don't know where am i going wrong.
Thanks in advance
test = pd.read_csv('/content/drive/My Drive/Datasets/Test_set US_SUP.csv')
test.fillna('No text',inplace=True)
DATA_COLUMN_TEST_A = 'content_A_test'
DATA_COLUMN_TEST_B = 'content_B_test'
LABEL_COLUMN = 'Labels_test'
label_list_test = [x for x in np.unique(test.Labels_test)]
print(label_list_test)
test_InputExamples = test.apply(lambda x: bert.run_classifier.InputExample(guid=None,
text_a = x[DATA_COLUMN_TEST_A],
text_b = x[DATA_COLUMN_TEST_B],
label = 0), axis = 1)
test_features = bert.run_classifier.convert_examples_to_features(test_InputExamples, label_list, MAX_SEQ_LENGTH, tokenizer)
Error:
INFO:tensorflow:Writing example 0 of 15
INFO:tensorflow:Writing example 0 of 15
KeyError Traceback (most recent call last)
----> 1 test_features = bert.run_classifier.convert_examples_to_features(test_InputExamples, label_list, MAX_SEQ_LENGTH, tokenizer)
1 frames
/usr/local/lib/python3.6/dist-packages/bert/run_classifier.py in convert_single_example(ex_index, example, label_list, max_seq_length, tokenizer)
457 assert len(segment_ids) == max_seq_length
458
--> 459 label_id = label_map[example.label]
460 if ex_index < 5:
461 tf.logging.info("* Example *")
KeyError: 0
 ShrikanthSingh
on 28 Dec 2019
ShrikanthSingh
on 28 Dec 2019
Hello @ShrikanthSingh, I'm stuck with the same error, were you able to resolve that error?
Thank you
 AbhilashG97
on 19 Feb 2020
AbhilashG97
on 19 Feb 2020
Hello @ShrikanthSingh, I'm stuck with the same error, were you able to resolve that error?
Thank you
Hi @AbhilashG97 I partially remember about resolving this error. Hence I think I figured it out by changing the labels from [1, 2, 3, 4, 5] to [0, 1, 2, 3, 4] because the enumeration for the labels in the run classifier starts from 0 and not from 1. But I am not sure of this solution, because it was long time back.
ShrikanthSingh
on 19 Feb 2020
Hello @ShrikanthSingh, thank you so much, I was able to fix the error.
I did something quite stupid, I forgot to write the code to map my labels to integer numbers. I mapped my labels to integer numbers starting from 0 and it works fine now. :sparkles:
AbhilashG97
on 20 Feb 2020
Hi, I got key error 4 when I ran run_classifier.py on the train.tsv file. Does anyone happen to know how to resolve this?
INFO:tensorflow:Writing example 0 of 145342
I0726 12:31:53.243687 13768 run_classifier.py:487] Writing example 0 of 145342
Traceback (most recent call last):
File "run_classifier.py", line 981, in
tf.app.run()
File "C:\Users\ll\anaconda3\lib\site-packages\tensorflow_core\python\platform\app.py", line 40, in run
_run(main=main, argv=argv, flags_parser=_parse_flags_tolerate_undef)
File "C:\Users\ll\anaconda3\lib\site-packages\absl\app.py", line 299, in run
_run_main(main, args)
File "C:\Users\ll\anaconda3\lib\site-packages\absl\app.py", line 250, in _run_main
sys.exit(main(argv))
File "run_classifier.py", line 870, in main
train_examples, label_list, FLAGS.max_seq_length, tokenizer, train_file)
File "run_classifier.py", line 490, in file_based_convert_examples_to_features
max_seq_length, tokenizer)
File "run_classifier.py", line 459, in convert_single_example
label_id = label_map[example.label]
KeyError: '4'
Thanks in advance!
 Lailiwen
on 26 Jul 2020
Lailiwen
on 26 Jul 2020
Hello @ShrikanthSingh, thank you so much, I was able to fix the error.
I did something quite stupid, I forgot to write the code to map my labels to integer numbers. I mapped my labels to integer numbers starting from 0 and it works fine now. ✨
@AbhilashG97 I encountered the same issue as @ShrikanthSingh and I even changed the the labels to integer starting from 0
df_v2.category = pd.Categorical(pd.factorize(df_v2.category)[0])
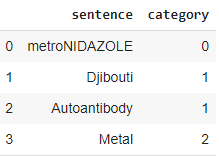
Can you please tell me how do I overcome the same KeyError?
 kanishk-verma-dotcom
on 4 Nov 2020
kanishk-verma-dotcom
on 4 Nov 2020
Related issues
 whqwill
·
4Comments
whqwill
·
4Comments
 quincyliang
·
4Comments
quincyliang
·
4Comments
 dangal95
·
3Comments
dangal95
·
3Comments
 okgrammer
·
4Comments
okgrammer
·
4Comments
 miyamonz
·
3Comments
miyamonz
·
3Comments
Most helpful comment
@hsm207 @Sneha-Rao-GR
I had a similar issue once. I feel that the issue is not necessarily because of the data format.
In my case I had training data in the format of:
<ID> <LABEL> <THROW_AWAY> <SENTENCE>0 1 a 'Some random sentence'Yet, I had this issue. After bit of digging, I realized that the run_classifier file is configured by default to work with binary classification, so when the classifier comes across any label beyong 0 or 1 it throws an error for obvious reasons, because of the way it's
get_labelfunction is coded.So, go to -> BERT BASE FOLDER - > run_classifier.py - > get_label function and change it from:
def get_labels(self): """See base class.""" return ["0", "1"]to
def get_labels(self): """See base class.""" return ["0", "1", "2", "3", "4", "5", "6", "7"] # How many ever distinct labels you have in your data setI Hope it helps.