Bert: Wiki Data Formation Problem, Need Sentence Split
I'm checking and converting the wiki data for pre-trainning, just like below:

When the process finished, I've got 12792 files, one of these files shows like below:

One line means represents one paragraph, but what we need is one line for one sentence, so am I wrong, or the script is not complete ? Do you have the complete script to do the whole job ?
 zheolong
zheolong
All 32 comments
@zheolong
i used below script to split sentences to new-lines of sentences.
 dsindex
on 9 Jan 2019
dsindex
on 9 Jan 2019
@dsindex That's what I want. Can u show me an command example to run this script?
zheolong
on 9 Jan 2019
@zheolong
https://github.com/dsindex/bert
you can copy 'create_pretraining_data.bash' for that purpose :)
download wiki data
extract text
$ cd data
$ git clone https://github.com/attardi/wikiextractor
$ cd wikiextractor
$ python WikiExtractor.py -o ../output < ../enwiki-latest-pages-articles.xml
- create pretraining data
$ ./create_pretraining_data.bash
@dsindex create_pretraining_data.py treats one wiki web page as one paragraph in the final txt, is that right.
zheolong
on 9 Jan 2019
it read output/AA/wiki_00.txt(for example) and convert to tf record file.
and wiki_xx.txt is made from several wiki pages.
(because there are many doc ids in it).
since create_pretraining_data.py can’t handle very large text file due to out of memory,
we should spilt input text file.
so, we can feed output/*/*.tfrecord to run_pretraining script.
dsindex
on 9 Jan 2019
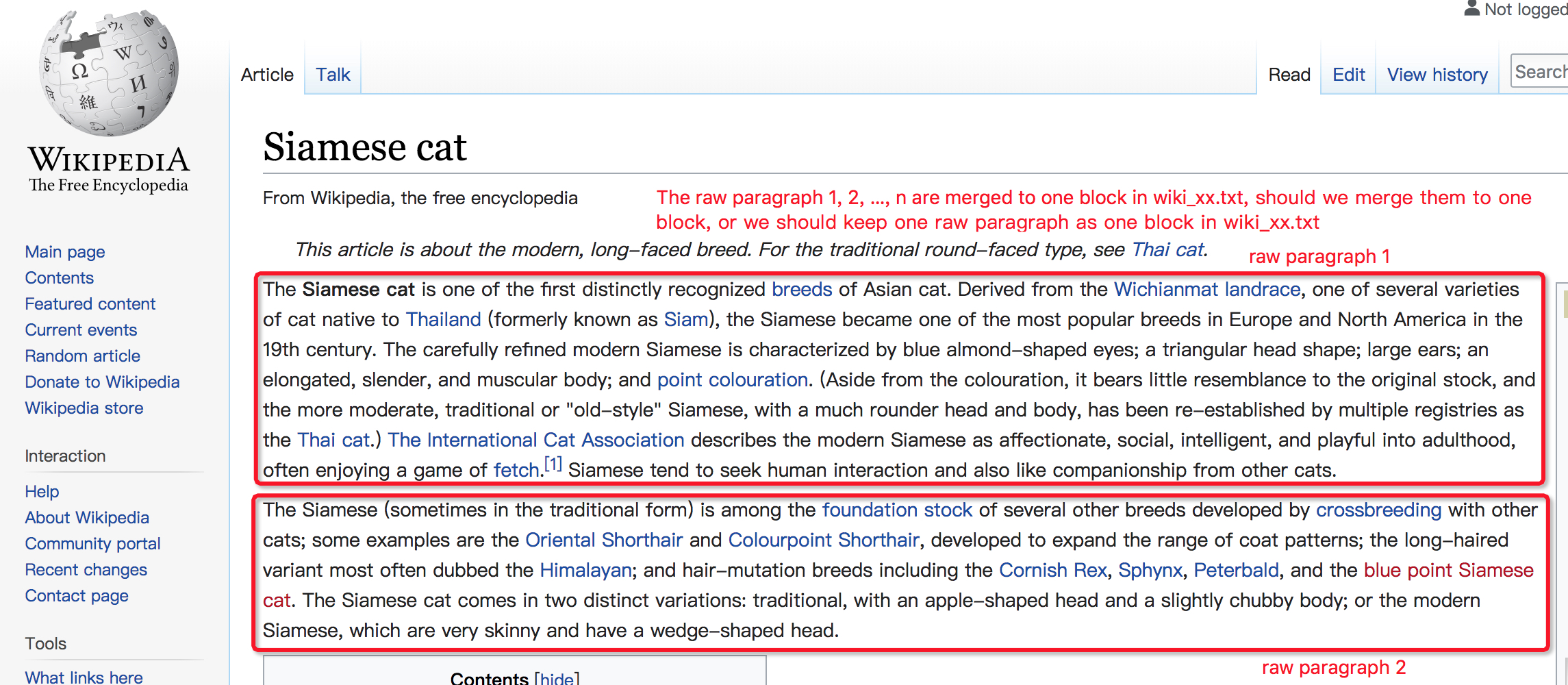
@dsindex wiki_xx.txt is made from several wiki pages, ok, I've figured that.
So, what I want to say, is like below
zheolong
on 10 Jan 2019
@zheolong
i got it. well, i think you’d better modify the wikiExtractor to achieve what you want.
(edit) i just get an idea to spilit the paragraphs. let me think....
dsindex
on 10 Jan 2019
@dsindex I've checked the google public small sample, and your program is doing the right thing. Multiple paragraph can be merged to one block.
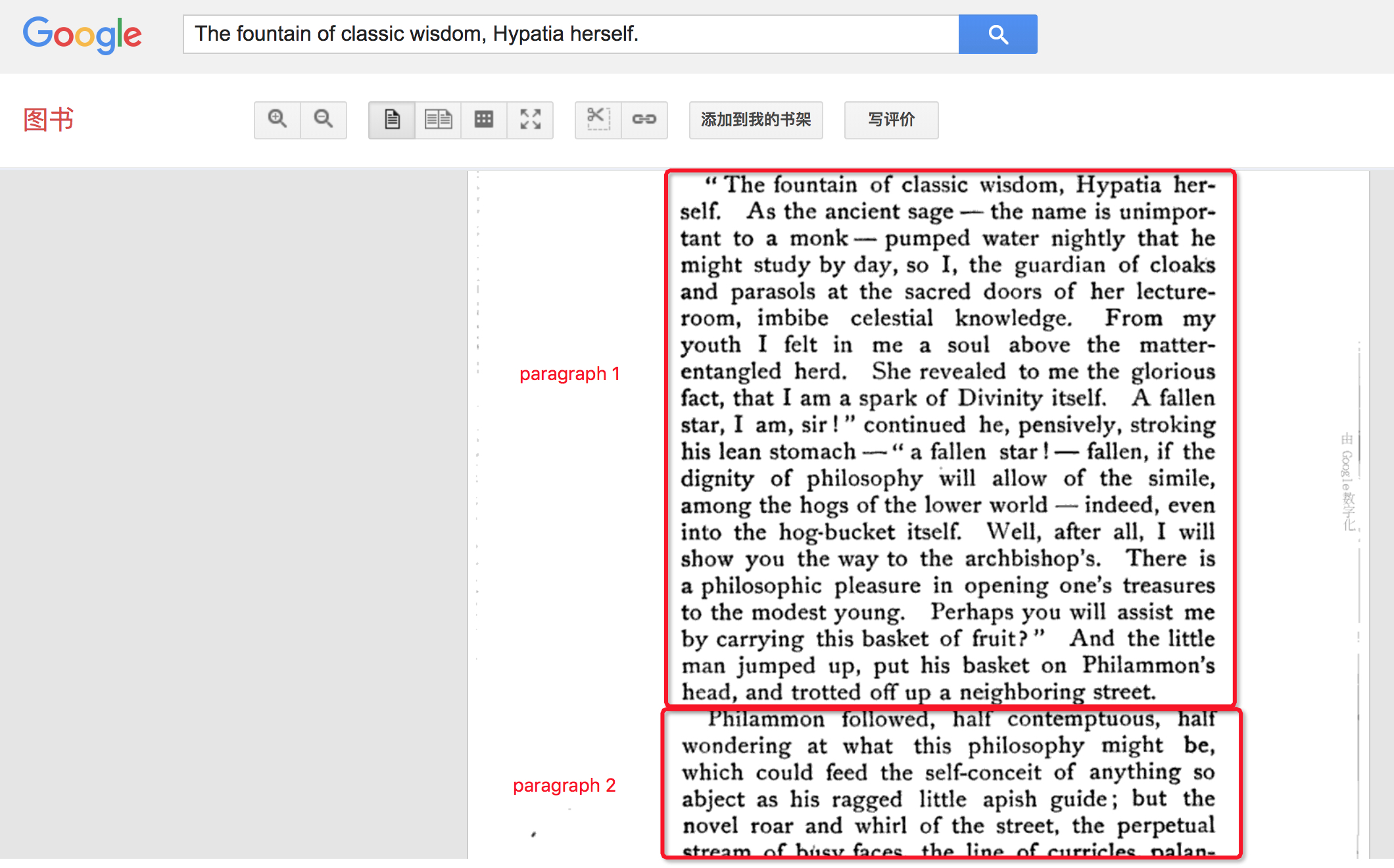
The google public small sample, like below
This text is included to make sure Unicode is handled properly: 力加勝北区ᴵᴺᵀᵃছজটডণত
Text should be one-sentence-per-line, with empty lines between documents.
This sample text is public domain and was randomly selected from Project Guttenberg.
The rain had only ceased with the gray streaks of morning at Blazing Star, and the settlement awoke to a moral sense of cleanliness, and the finding of forgotten knives, tin cups, and smaller camp utensils, where the heavy showers had washed away the debris and dust heaps before the cabin doors.
Indeed, it was recorded in Blazing Star that a fortunate early riser had once picked up on the highway a solid chunk of gold quartz which the rain had freed from its incumbering soil, and washed into immediate and glittering popularity.
Possibly this may have been the reason why early risers in that locality, during the rainy season, adopted a thoughtful habit of body, and seldom lifted their eyes to the rifted or india-ink washed skies above them.
"Cass" Beard had risen early that morning, but not with a view to discovery.
A leak in his cabin roof,--quite consistent with his careless, improvident habits,--had roused him at 4 A. M., with a flooded "bunk" and wet blankets.
The chips from his wood pile refused to kindle a fire to dry his bed-clothes, and he had recourse to a more provident neighbor's to supply the deficiency.
This was nearly opposite.
Mr. Cassius crossed the highway, and stopped suddenly.
Something glittered in the nearest red pool before him.
Gold, surely!
But, wonderful to relate, not an irregular, shapeless fragment of crude ore, fresh from Nature's crucible, but a bit of jeweler's handicraft in the form of a plain gold ring.
Looking at it more attentively, he saw that it bore the inscription, "May to Cass."
Like most of his fellow gold-seekers, Cass was superstitious.
The fountain of classic wisdom, Hypatia herself.
As the ancient sage--the name is unimportant to a monk--pumped water nightly that he might study by day, so I, the guardian of cloaks and parasols, at the sacred doors of her lecture-room, imbibe celestial knowledge.
From my youth I felt in me a soul above the matter-entangled herd.
She revealed to me the glorious fact, that I am a spark of Divinity itself.
A fallen star, I am, sir!' continued he, pensively, stroking his lean stomach--'a fallen star!--fallen, if the dignity of philosophy will allow of the simile, among the hogs of the lower world--indeed, even into the hog-bucket itself. Well, after all, I will show you the way to the Archbishop's.
There is a philosophic pleasure in opening one's treasures to the modest young.
Perhaps you will assist me by carrying this basket of fruit?' And the little man jumped up, put his basket on Philammon's head, and trotted off up a neighbouring street.
Philammon followed, half contemptuous, half wondering at what this philosophy might be, which could feed the self-conceit of anything so abject as his ragged little apish guide;
but the novel roar and whirl of the street, the perpetual stream of busy faces, the line of curricles, palanquins, laden asses, camels, elephants, which met and passed him, and squeezed him up steps and into doorways, as they threaded their way through the great Moon-gate into the ample street beyond, drove everything from his mind but wondering curiosity, and a vague, helpless dread of that great living wilderness, more terrible than any dead wilderness of sand which he had left behind.
Already he longed for the repose, the silence of the Laura--for faces which knew him and smiled upon him; but it was too late to turn back now.
His guide held on for more than a mile up the great main street, crossed in the centre of the city, at right angles, by one equally magnificent, at each end of which, miles away, appeared, dim and distant over the heads of the living stream of passengers, the yellow sand-hills of the desert;
while at the end of the vista in front of them gleamed the blue harbour, through a network of countless masts.
At last they reached the quay at the opposite end of the street;
and there burst on Philammon's astonished eyes a vast semicircle of blue sea, ringed with palaces and towers.
He stopped involuntarily; and his little guide stopped also, and looked askance at the young monk, to watch the effect which that grand panorama should produce on him.
And the raw paragraphs of the 3th block are like below
But the sample is so short, I don't know if we should otherwise treat one raw chapter as one block in wiki_xx.txt
If the block in wiki_xx.txt contains multiple continuous contextual sentences, so what is one 'context' in raw wiki web page ?
zheolong
on 10 Jan 2019
@zheolong
there are two options we can choose.
allow next sentence in a doc(a wiki page)
lines = tokenize.sent_tokenize(line) for l in lines: print(l)- empty newline b/w docs and no newline in a doc
- i think this is reasonable because even though the paragraphs are different, the topic is similar in that context.
allow next sentence in a paragraph only
- we can modify 'preprocess.py'
lines = tokenize.sent_tokenize(line) for l in lines: print(l) print('')- empty newline b/w docs and b/w paragraphs
- i think this is also reasonable.
i used the first method to create pretraining data.
but i did't compare which is better.
dsindex
on 10 Jan 2019
@dsindex ok, got it
zheolong
on 10 Jan 2019
@dsindex Your repository contains one vocabulary file named vocab.txt.uncased, where it is from?
zheolong
on 10 Jan 2019
@zheolong
vocab.txt.uncased cames from ‘glove.6B.’ official releases.
and vocab.txt.cased are from ‘glove.840B.’.
note that these are for building word-based bert model.
and i also modified ‘tokenization.py’ for not using word-piece tokenizer. i only want to use basic tokenizer for my task.
you could download original vocab.txt from the official bert releases.
dsindex
on 10 Jan 2019
@dsindex Do we need to set dupe_factor>1 for this big data set?
zheolong
on 16 Jan 2019
@zheolong
well, i don't know exactly.
however, since the loss is calculated only for the masked tokens, the tf record data for training would be smaller than we expected if we set 'dupe_factor=1'.
dsindex
on 16 Jan 2019
@dsindex what's ur machine and gpu configuration for pre-trainning, how long will it take to run 1000,000 steps
zheolong
on 17 Jan 2019
@dsindex
i used this script for pre-training(BERT base, uncased).
https://github.com/dsindex/bert/blob/master/run_pretraining.bash
on Tesla V100(1 GPU, 8 CPU, 32 GB)
it takes 3 days long for 1M steps.
however, in case we are using word-piece tokenizer, the vocabulary should be different from mine(from glove.6B). so, the training time might be different(longer?).
dsindex
on 17 Jan 2019
@dsindex With Wiki data? 3 days is really short. Google use four days on 4 to 16 Cloud TPUs
zheolong
on 17 Jan 2019
@zheolong
yes, but i used word-based vocab and 1M steps and i don’t know what is the final steps they used for training.
i guess that word-piece vocab takes long time or they used huge training steps.
in addition, google says that they combine the Wiki and Book data for pre-training.
dsindex
on 17 Jan 2019
@dsindex Do u get any distributed BERT code and try run it on multiple machines ?
zheolong
on 22 Jan 2019
@zheolong
no i don’t.
but, there is a pytorch version which can use multiple gpus for training.
https://github.com/dhlee347/pytorchic-bert
what about using TPU cloud?
dsindex
on 22 Jan 2019
@dsindex We have our own gpu cluster, so we prefer to use gpu
zheolong
on 22 Jan 2019
@dsindex I've trained the model for 5.5 days, with (wiki + bookCorpus) dataset, my vocab is google public uncased vocab in uncased_L-12_H-768_A-12, the vocab size is 30522. The loss and accuracy are as below.
INFO:tensorflow:***** Eval results *****
INFO:tensorflow: global_step = 1000000
INFO:tensorflow: loss = 1.7235886
INFO:tensorflow: masked_lm_accuracy = 0.6630389
INFO:tensorflow: masked_lm_loss = 1.6173733
INFO:tensorflow: next_sentence_accuracy = 0.955
INFO:tensorflow: next_sentence_loss = 0.1037216
The machine is with 2 Tesla P100 gpu, 16GB memory with each. Is the result normal?
zheolong
on 25 Jan 2019
@zheolong
yes~ that is normal result.
but for getting a good model, you need to run more steps.
the ‘loss’ below 1.0 is good enough.
dsindex
on 25 Jan 2019
@zheolong that's really fast. did you use max-seq-length = 128 or 512? did you train from scratch, or initialized the model with the pre-trained weights?
 eric-haibin-lin
on 18 Feb 2019
eric-haibin-lin
on 18 Feb 2019
@eric-haibin-lin max-seq-length = 128, from scratch
zheolong
on 19 Feb 2019
Thanks for sharing @zheolong
eric-haibin-lin
on 19 Feb 2019
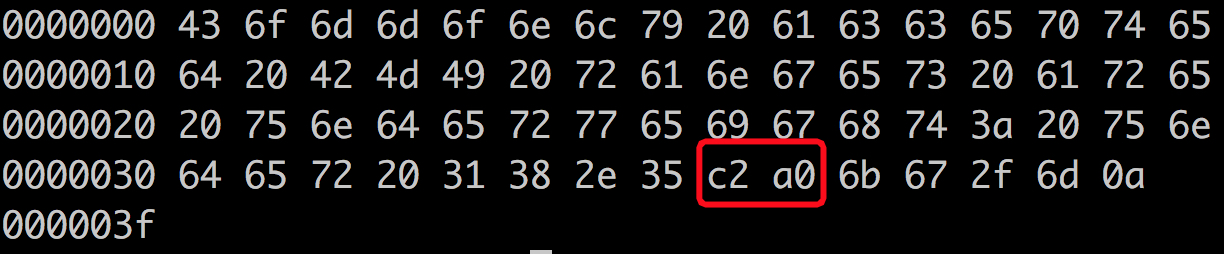
@dsindex
I've found special commas in wiki dataset, its hex is '0xC2 0xA0', just like below. Is there any need to change them to normal '0x20'?
- The original text

- The hex

zheolong
on 21 Feb 2019
Another problem is with bookcorpus dataset, I've found chinese comma like below, is that normal?

zheolong
on 21 Feb 2019
@zheolong
just my thought.
it will be a little bit better.
but, since we have a large corpus, the small change will not be considerable.
dsindex
on 21 Feb 2019
@dsindex Do you plan to create a PR adding sentence split?
 micmelesse
on 7 Mar 2019
micmelesse
on 7 Mar 2019
@micmelesse no, i don't ^^;
dsindex
on 7 Mar 2019
@dsindex I've trained the model for 5.5 days, with (wiki + bookCorpus) dataset, my vocab is google public uncased vocab in
uncased_L-12_H-768_A-12, the vocab size is30522. The loss and accuracy are as below.INFO:tensorflow:***** Eval results ***** INFO:tensorflow: global_step = 1000000 INFO:tensorflow: loss = 1.7235886 INFO:tensorflow: masked_lm_accuracy = 0.6630389 INFO:tensorflow: masked_lm_loss = 1.6173733 INFO:tensorflow: next_sentence_accuracy = 0.955 INFO:tensorflow: next_sentence_loss = 0.1037216The machine is with 2 Tesla P100 gpu, 16GB memory with each. Is the result normal?
@zheolong, we also tried max sequence length as 128, it's very fast. Have you tried max sequence length to 512? in my experiemnts, it's really slow, as the batch size can only be 8 on a signle p100. We need lots of GPU to scale the batch.
Any one else tried shared memory of multiple GPU to suport larger batch size?
 Frank1993
on 20 Jun 2019
Frank1993
on 20 Jun 2019
Related issues
 HAWLYQ
·
3Comments
HAWLYQ
·
3Comments
 alter-bug-tracer
·
3Comments
alter-bug-tracer
·
3Comments
 santhoshkolloju
·
3Comments
santhoshkolloju
·
3Comments
 allenzhang010
·
3Comments
allenzhang010
·
3Comments
 miyamonz
·
3Comments
miyamonz
·
3Comments
Most helpful comment
@zheolong
https://github.com/dsindex/bert
you can copy 'create_pretraining_data.bash' for that purpose :)
download wiki data
extract text