Azure-functions-durable-extension: Singleton orchestrator starts multiple times
We're trying to create a simple demo app for the following scenario:
- an external event source sends data to an API (http triggered function)
- the data is saved to azure storage
- a singleton function aggregates the data and produces an output / sends a notification.
We want the aggregator function to be a singleton in order to group all the data available while it's running into a single process unit.
This scenario should match the Event Batching Pattern.
Based on the example from the docs, we created a simple client / starter that uses a specific instanceId for starting the orchestrator:
const string OrchestratorFunctionId = "1234567";
[FunctionName("Starter")]
public static async Task<HttpResponseMessage> Starter(
[HttpTrigger(AuthorizationLevel.Anonymous, methods: "get", Route = null)] HttpRequestMessage req,
[OrchestrationClient] DurableOrchestrationClient starter,
ILogger log)
{
// Check if an instance with the specified ID already exists.
var existingInstance = await starter.GetStatusAsync(OrchestratorFunctionId);
if (existingInstance == null)
{
var id = await starter.StartNewAsync("Orchestrator", OrchestratorFunctionId, null);
log.LogWarning($"Started orchestration with ID = '{id}'.");
return starter.CreateCheckStatusResponse(req, OrchestratorFunctionId);
}
else
{
log.LogWarning($"Orchestration '{OrchestratorFunctionId}' already exists (status: {existingInstance.RuntimeStatus})!");
// An instance with the specified ID exists, don't create one.
return req.CreateErrorResponse(
HttpStatusCode.Conflict,
$"An instance with ID '{OrchestratorFunctionId}' already exists.");
}
}
Expected behavior
As described in the note about the race condition:
There is a potential race condition in this sample. If two instances of HttpStartSingle execute concurrently, both function calls will report success, but only one orchestration instance will actually start.
In our scenario, it's fine if two http triggered functions gets invoked at the same time and both function calls report success, since this operation would be a fire-and-forget "try start" the orchestrator, if it's not running.
If the starter would get invoked two times (concurrently) we expected to see the following logs:
- Started orchestration with ID = '1234567'
- Started orchestration with ID = '1234567' <-- from the second invocation of the started
- Orchestrator started with id 1234567 <-- only one orchestration instance starts
- Calling API (id: 1234567) <-- activity is called once, by the single orchestrator
- API called (id: 1234567)
- Orchestrator 1234567 completed
Actual behavior
When the starter gets invoked concurrently, many instances of the orchestrator function get executed,
therefore not behaving like a singleton function.
Here you can find the full test.
Invoke the Test function that will execute two calls to the starter and recreate the unexpected behavior.
These are the logs when the Test function is executed for the first time (the orchestrator function has never been called / doesn't exists):
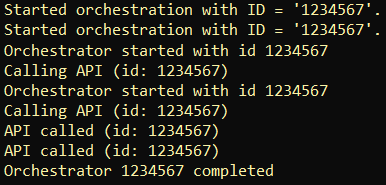
If the Test function gets invoked after the instances of the orchestrator function complete, these are the logs (works as expected):

Durable functions state
This is the state of the entries in the table storage associated with the test:
DurableFunctionsHubInstances
| PartitionKey | RowKey | Timestamp | CreatedTime | ExecutionId | Input | LastUpdatedTime | Name | RuntimeStatus | Version
| --- | --- | --- | --- | --- | --- | --- | --- | --- | ---
| 1234567 | | 2019-02-19T15:39:23.782Z | 2019-02-19T15:39:15.787Z | 1bb80d78995a46078d653314a599b398 | null | 2019-02-19T15:39:23.576Z | Orchestrator | Completed |
DurableFunctionsHubHistory
| PartitionKey | RowKey | Timestamp | EventId | EventType | ExecutionId | IsPlayed | _Timestamp | Input | Name | OrchestrationInstance | Version | TaskScheduledId | OrchestrationStatus
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | ---
| 1234567 | 0 | 2019-02-19T15:39:17.985Z | -1 | OrchestratorStarted | 1bb80d78995a46078d653314a599b398 | false | 2019-02-19T15:39:17.772Z | | | | | |
| 1234567 | 1 | 2019-02-19T15:39:17.985Z | -1 | ExecutionStarted | 1bb80d78995a46078d653314a599b398 | true | 2019-02-19T15:39:15.787Z | null | Orchestrator | {"InstanceId":"1234567","ExecutionId":"1bb80d78995a46078d653314a599b398"} | | |
| 1234567 | 2 | 2019-02-19T15:39:17.985Z | 0 | TaskScheduled | 1bb80d78995a46078d653314a599b398 | false | 2019-02-19T15:39:17.789Z | | CallAPI | | | |
| 1234567 | 3 | 2019-02-19T15:39:17.985Z | -1 | OrchestratorCompleted | 1bb80d78995a46078d653314a599b398 | false | 2019-02-19T15:39:17.789Z | | | | | |
| 1234567 | 4 | 2019-02-19T15:39:23.680Z | -1 | OrchestratorStarted | 1bb80d78995a46078d653314a599b398 | false | 2019-02-19T15:39:23.482Z | | | | | |
| 1234567 | 5 | 2019-02-19T15:39:23.680Z | -1 | TaskCompleted | 1bb80d78995a46078d653314a599b398 | true | 2019-02-19T15:39:23.129Z | | | | | 0 |
| 1234567 | 6 | 2019-02-19T15:39:23.680Z | 1 | ExecutionCompleted | 1bb80d78995a46078d653314a599b398 | false | 2019-02-19T15:39:23.572Z | | | | | | Completed
| 1234567 | 7 | 2019-02-19T15:39:23.680Z | -1 | OrchestratorCompleted | 1bb80d78995a46078d653314a599b398 | false | 2019-02-19T15:39:23.576Z | | | | | |
| 1234567 | sentinel | 2019-02-19T15:39:23.680Z | | | 1bb80d78995a46078d653314a599b398 | | | | | | | |
This could be solved with the behavior described in Add support for atomic StartNewAsync that would execute only if instance is not already running.
 tommasobertoni
tommasobertoni
All 3 comments
Yes, unfortunately this is a known issue and we're using the GitHub issue you linked to to track fixing it. I'll leave this issue open since it describes the symptom and will therefore be easier for folks to discover.
 cgillum
on 19 Feb 2019
cgillum
on 19 Feb 2019
EDIT: new implementation using table storage instead of queues, resulting in more efficient operations.
I put together a workaround for this situation: it's not the most elegant solution, but it may help until the bug is solved.
The solution uses the CloudTable.CreateIfNotExistsAsync method to ensure that only one instance of the function is being created, if it doesn't already exist.
The creation of the singleton orchestrator function follows these steps:
- if an instance with the given
instanceIdexists, stops the creation * - try to create a record in the support table: if the record already exists (i.e.
CloudTable.ExecuteAsync(TableOperation.Insert...returns http status code409 Conflict) stops the creation - create the orchestrator instance using the
DurableOrchestrationClient - wait for the orchestrator to run
- delete the previously created table record
If n functions try to create a single instance of an orchestrator (that doesn't exist yet), all will find that client.GetStatusAsync(instanceId) returns null like the test described in the issue, but only one will manage to create the record and the others will see that the entry already exists.
Here you can find the test with the workaround described.
The solution introduces two types: OrchestratorFactory and OrchestratorFunctionWatcher.
The first is the factory used to create the orchestrator instance and that executes the checks described, to ensure that only one instance is being created. The watcher is used to provide ad easy-to-use api to check the status of a function.
Aside from these changes, the test is the same as the one in the issue. Run the Test function to see it in action.
public async Task<bool> TryStartNewAsync(
DurableOrchestrationClient client,
string orchestratorFunctionName,
string instanceId,
object input,
bool startIfAlreadyCompleted = false)
{
// Check if an instance with the specified ID already exists.
var existingInstance = await client.GetStatusAsync(instanceId);
if (existingInstance != null)
{
bool restartFunction = startIfAlreadyCompleted && _completedStatuses.Contains(existingInstance.RuntimeStatus);
if (!restartFunction)
return false; // Function exists and should not be restarted.
}
// Create a temporary table record to track the creation of the current function.
var recordCreated = await TryCreateRecordAsync(orchestratorFunctionName, instanceId);
if (!recordCreated)
{
_log?.LogWarning($"Record already exists, possible concurrent start of the orchestrator {orchestratorFunctionName} with id {instanceId}.");
return false;
}
if (existingInstance != null)
await TryClearFunctionHistoryAsync(client, instanceId);
// Since the record didn't exist, we can *safely* create the singleton orchestrator
var functionId = await client.StartNewAsync(orchestratorFunctionName, instanceId, input);
// Await the function to start
var watcher = new OrchestratorFunctionWatcher(client);
var functionIsActive = await watcher.FunctionHasActiveStatusAsync(functionId);
await TryDeleteRecordAsync(orchestratorFunctionName, instanceId);
return true;
}
These are the resulting logs:
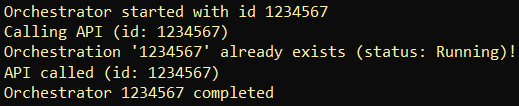
and when the orchestrator is running, the singleton behaves as expected:

*NOTE: the TryStartNewAsync method in the factory supports the restart of a completed function,
where completed means that its status is Completed, Failed, Terminated or Canceled.
This can be useful if the orchestrator function will complete, but you still want only one executing at each time.
tommasobertoni
on 20 Feb 2019
Singleton attribute is working in Azure Functions, with specific consideration around billing: https://github.com/Azure/azure-functions-host/issues/912#issuecomment-419608830
We use that as a workaround where we start the orchestrator for now, we accept being double billed for it. I updated the linked issue to reflect that as well so that people understand what to do to prevent bugs like this in the meantime.
 SimonLuckenuik
on 18 Apr 2019
SimonLuckenuik
on 18 Apr 2019
Related issues
 pacodelacruz
·
3Comments
pacodelacruz
·
3Comments
 shibayan
·
3Comments
shibayan
·
3Comments
 mpaul31
·
3Comments
mpaul31
·
3Comments
 mark-szabo
·
3Comments
mark-szabo
·
3Comments
 cvanama
·
3Comments
cvanama
·
3Comments
Most helpful comment
EDIT: new implementation using table storage instead of queues, resulting in more efficient operations.
I put together a workaround for this situation: it's not the most elegant solution, but it may help until the bug is solved.
The solution uses the
CloudTable.CreateIfNotExistsAsyncmethod to ensure that only one instance of the function is being created, if it doesn't already exist.The creation of the singleton orchestrator function follows these steps:
instanceIdexists, stops the creation *CloudTable.ExecuteAsync(TableOperation.Insert...returns http status code409 Conflict) stops the creationDurableOrchestrationClientIf n functions try to create a single instance of an orchestrator (that doesn't exist yet), all will find that
client.GetStatusAsync(instanceId)returns null like the test described in the issue, but only one will manage to create the record and the others will see that the entry already exists.Here you can find the test with the workaround described.
The solution introduces two types:
OrchestratorFactoryandOrchestratorFunctionWatcher.The first is the factory used to create the orchestrator instance and that executes the checks described, to ensure that only one instance is being created. The watcher is used to provide ad easy-to-use api to check the status of a function.
Aside from these changes, the test is the same as the one in the issue. Run the
Testfunction to see it in action.These are the resulting logs:
and when the orchestrator is running, the singleton behaves as expected:
*NOTE: the
TryStartNewAsyncmethod in the factory supports the restart of a completed function,where completed means that its status is Completed, Failed, Terminated or Canceled.
This can be useful if the orchestrator function will complete, but you still want only one executing at each time.