Azure-docs: What will happen if the number of properties exceed the limit?
Hi,
I have a question regarding the topic of the property limit. Is it only a limit of the warm storage? If there are more than 1000 properties in the ingestion pipeline, are they persisted to the cold storage still? If yes, can they be queried from the explorer via the cold storage query?
The scenario here is that there are many (more than 1000) properties in the ingestion pipeline, all of them will be used for the big data analysis by the data scientist via downloading the generated parquet file in the cold storage. Meanwhile, only a few of them will be used, e.g. by an operator, in an ad hoc fashion. I cannot judge whether it is a common scenario or not in the industry, but I would love to have a way to tell Azure TSI, which properties should be stored in the warm storage and the rest not. Is it something in your mind already?
Best regards,
Xiaoyang Chen
Document Details
⚠ Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue linking.
- ID: 28603a8a-7f20-bc2c-ee79-cb1a60c6fbe2
- Version Independent ID: 5f3c797b-0e3a-34fb-edf3-d915d07347e8
- Content: Plan your Gen2 environment - Azure Time Series Insights
- Content Source: articles/time-series-insights/how-to-plan-your-environment.md
- Service: time-series-insights
- GitHub Login: @deepakpalled
- Microsoft Alias: dpalled
 xiaoyang-connyun
xiaoyang-connyun
All 9 comments
Hello @xiaoyang-connyun , thank you for the great question! I am checking with the team if this is planned or\and can be added in this doc. In the meantime did you check for any similar request on Azure Time Series Insights feedback forum?
Thanks!
 asergaz
on 23 Oct 2020
asergaz
on 23 Oct 2020
Thanks @asergaz .
Yes, but at least I did not find anything related.
xiaoyang-connyun
on 23 Oct 2020
Hi @xiaoyang-connyun,
Great question, and it looks like our storage docs page should be updated to answer this. First I will answer the immediate question, but then I want to take a step back and discuss your JSON payload and see if you'd benefit from re-shaping.
There is no limit on schema width for cold storage--those 1000+ properties will be indexed and available via cold store queries. Tell me more about your schema--why are there so many properties? Is it the case that the tag or sensor ID is a JSON key rather than a value? What are you using as your TS ID? In the first JSON sample below the tag/sensor/signal identifiers are keys, but the second sample shows a pivoted JSON where they are property values.
{
"CLGSTG1CMD": 0,
"CLGSTG2CMD": 1,
"CLGSTG3CMD": 1,
"SFSPEED": 70.67834,
"SAT": 64.11172,
"iot-hub-connection-deviceId": "800500054755",
"timestamp": "2020-03-23T14:39:22.0505305+01:00"
}
{
"timestamp": "2020-03-23T14:39:22.0505305+01:00",
"iot-hub-connection-deviceId": "800500054755",
"values": [{
"tagId": "CLGSTG1CMD",
"value": 0
},
{
"tagId": "CLGSTG2CMD",
"value": 1
},
{
"tagId": "CLGSTG3CMD",
"value": 1
},
{
"tagId": "SFSPEED",
"value": 70.67834
},
{
"tagId": "SAT",
"value": 64.11172
}
]
}
There are pros and cons to each:
Narrow pros:
- Having a fixed schema might make things easier and faster for ML users who consume this as training data (in conjunction with the TSM for context). From a databricks/pyspark perspective, loading multiple parquet files into a data frame via UNION will be simpler with consistent schema across all the files.
- Depending on the query patterns, there might be better partitioning.
- Depending on your model, you might be able to better organize your tags using TSM and hierarchies.
- Data is always query-able from warm store.
Narrow cons:
- Many more rows will be generated, instead of 1 event shown in the first example there will be 5 as shown in the second example. Thus, more API calls are required and your users might hit our API limits sooner.
- The query concurrency limit will also be hit sooner as users are making more API calls.
In general, wide is beneficial up until about 100 columns around when going narrow might be best--but this decision should always be driven based on the query patterns.
 lyrana
on 26 Oct 2020
lyrana
on 26 Oct 2020
Hi @lyrana ,
Thanks for your comprehensive explanation, and it is quite inspiring to me.
So, why are there so many properties? It is because first of all, we are using the "wide" approach as your first example demonstrated, and secondly, machines are not standardized so that every machine is sending different data points.
I also once thought about the "narrow" approach. However, independent from the query scenario, I did not understand how that would work with Azure TSI Explorer. With Azure TSI Explorer, it is pretty straightforward to work with the semantic like SELECT <data point>, but how to make it work with the semantic like SELECT <data point value> WHERE <data point name> = <data point>? I might have missed something, could you please explain me a bit as well?
Besides, I guess it is a valid requirement that not all properties need to be stored in the warm storage, and with TSM it is straightforward to define which properties are needed. What do you think?
Best regards,
Xiaoyang
xiaoyang-connyun
on 27 Oct 2020
Hi @xiaoyang-connyun
Thanks for your patience. First, I will mention that once you weigh the pros and cons, if you do decide to go "narrow" you can use either Azure Stream Analytics or even an Azure function (depending on your throughput needs and architecture, etc.) egressing to an Event Hub in front of TSI in order to do your schema standardization. But, this will incur additional costs and may or may not be needed.
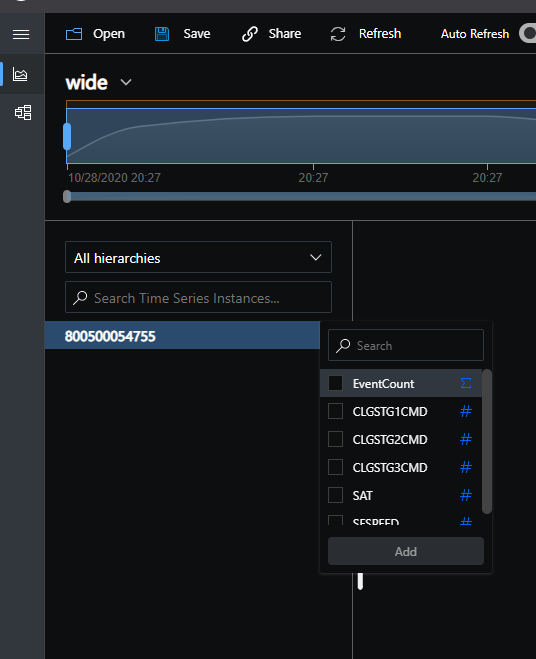
I think I understand your question, and I assume you're using TSI Gen2, correct? In the first example, iot-hub-connection-deviceId was set at the TS ID, and the schema went wide.
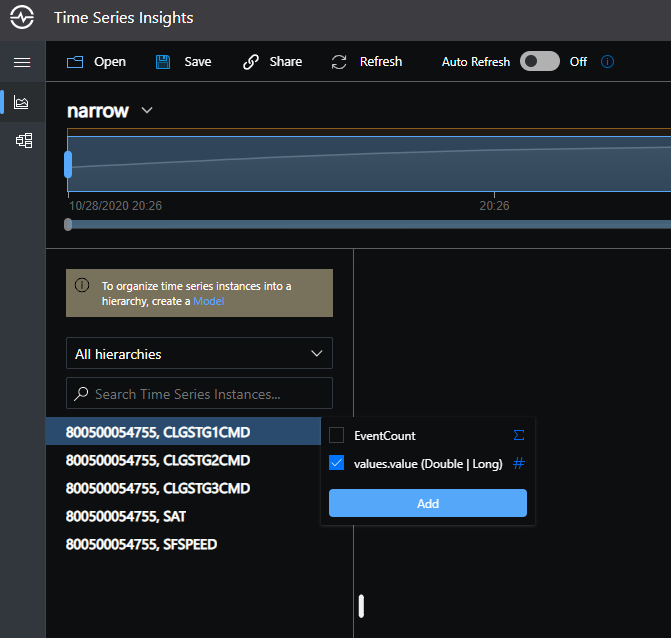
In the second narrow example, the TS ID property should be assigned as values.tagId, _or_ a composite key consisting of values.tagId and iot-hub-connection-deviceId if the hub device is needed as part of the unique identifier.
In the first, TSI will create instances per IoT Hub device, and the explorer will look like this:
In the second, the tag names will become the instances, and appear like this with an un-curated model
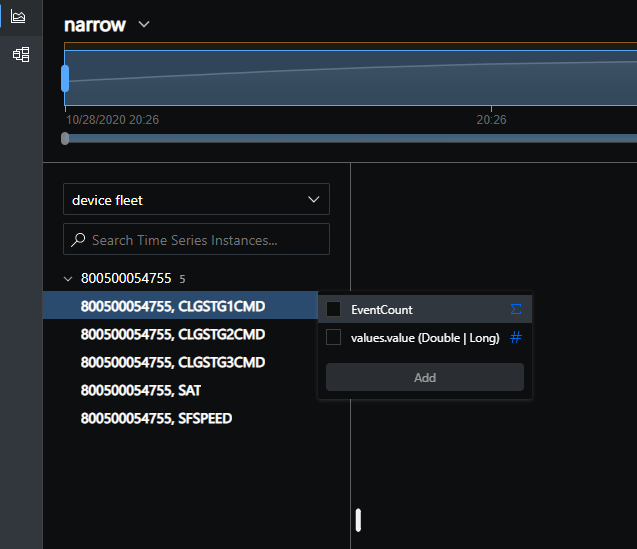
But then could be organized via hierarchies like this:
Exposing JSON properties is done via Type variables, you might want to check out this lab that goes through model curation on step 5:
aka.ms/tsilab
But curating a model when your machines aren't standardized might be difficult. Some users script this at the edge via the TSM APIs , but you'd have to write and maintain that script.
Please let me know if you have further questions, happy to help
lyrana
on 29 Oct 2020
Hi @lyrana ,
Thanks for the example, it was clear that I could use Function to transform the wide schema to the narrow one, but I was too shortsighted and did not realize that I could let the property name (tagId) be the instance id and group them together with the hierarchy.
I think the summary here will be, to choose the wide schema or the narrow schema, it depends on the query pattern and the hard limit of the warm storage. To use the narrow schema, other than adding a transformation component, the model has to be designed differently as well.
I would say my origin question is clearly answered, and I hope the documentation can be adjusted accordingly soon to close the issue.
However, I would be quite happy if you could answer my open question as well, do you see the need to have a way to control what properties should be stored in the warm storage? I could imagine that due to the query pattern, somebody could choose the wide schema approach. In order not to hit the limitation, save the storage cost and have a better performance, he would like to have a way to let only necessary properties to be stored in the warm storage. And in reality, properties that are often to be analyzed for example by the operator using the Explorer are usually a small set of all properties.
I am looking forward to hearing your opinions, nevertheless, it would also be fine if we stop here.
xiaoyang-connyun
on 29 Oct 2020
@xiaoyang-connyun it's been such a pleasure to assist you, and yes there is an opportunity to improve the docs to address this question. I don't have a timeline right now for when this particular doc update will go out--it's in our backlog though. I will keep this GitHub issue open and link it to the backlog item.
Currently no, there is no custom routing filter feature for what goes into warm storage, but, I'm taking note of your scenario and feature request. If you go wide you'll hit the limit, so one thing that you can do is to test the query performance for cold-only, without warm storage enabled--the cold query perf might meet the needs and expectations of your operators.
Do you have an idea of what the all-time upper limit of your schema width could be? I'm trying to understand if it's in the thousands, tens of thousands etc.
lyrana
on 30 Oct 2020
@lyrana So currently we have around 30 gateways, where each gateway sends data points from couple of hundreds to a thousand. Some of them are overlapping some are not. I think it is like that because it is still at the early stage, and the customer tries to get as much as data from the machine. The data scientist probably together with the domain expert will analyze the data to understand what data is helpful. Most likely, the later stage will not require as many data points.
xiaoyang-connyun
on 30 Oct 2020
@xiaoyang-connyun I see, thanks for this info.
lyrana
on 30 Oct 2020
Related issues
 ianpowell2017
·
3Comments
ianpowell2017
·
3Comments
 JeffLoo-ong
·
3Comments
JeffLoo-ong
·
3Comments
 Agazoth
·
3Comments
Agazoth
·
3Comments
 DeepPuddles
·
3Comments
DeepPuddles
·
3Comments
 jharbieh
·
3Comments
jharbieh
·
3Comments