Ax: RuntimeError: cholesky_cpu: U(63,63) is zero, singular U.
This is very similar to #99 but with newer versions of everything. Again, trying to tune the hyperparameters of a neural net, and got this runtime error.
ax=0.1.11
botorch=0.2.0
gpytorch=1.1.1
torch=1.5.0
python=3.8.1
os=Ubuntu 18.04
I have a lot of data that might be enough to reproduce the failure with some effort, but am likely missing a few key things. When I turn it back on I'll make sure I capture the random seed, and turn up the auto-save frequency.
Here's the parameter definition I was using:
ax_range = [
{
"name": "dropout",
"type": "range",
"bounds": [0.0, 1.0],
"value_type": "float",
"log_scale": False,
},
{
"name": "num_layers",
"type": "range",
"bounds": [1, 6],
"value_type": "int",
"log_scale": False,
},
{
"name": "fc_dim",
"type": "range",
"bounds": [10, 1000],
"value_type": "int",
"log_scale": True,
},
{
"name": "lr",
"type": "range",
"bounds": [1e-5, 0.1],
"value_type": "float",
"log_scale": True,
},
]
I recorded most of the configurations & objectives here:
singular-cholesky.csv.log, but lost the last few because they didn't auto-save before the crash. The final few objectives (rounded) were:
run=5 trial=104 score=2.57 best_score=1.69
run=5 trial=105 score=1.78 best_score=1.69
run=5 trial=106 score=2.35 best_score=1.69
run=5 trial=107 score=1.82 best_score=1.69
run=5 trial=108 score=3.96 best_score=1.69
run=5 trial=109 score=2.61 best_score=1.69
run=5 trial=110 score=2.14 best_score=1.69
run=5 trial=111 score=1.71 best_score=1.69
run=5 trial=112 score=2.39 best_score=1.69
run=5 trial=113 score=2.00 best_score=1.69
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-9-df78cf250713> in <module>
...
full stack trace:
~/anaconda3/envs/cvnlp/lib/python3.8/site-packages/ax/service/ax_client.py in get_next_trial(self)
289 Tuple of trial parameterization, trial index
290 """
--> 291 trial = self.experiment.new_trial(generator_run=self._gen_new_generator_run())
292 logger.info(
293 f"Generated new trial {trial.index} with parameters "
~/anaconda3/envs/cvnlp/lib/python3.8/site-packages/ax/service/ax_client.py in _gen_new_generator_run(self, n)
928 # Filter out GPYTorch warnings to avoid confusing users.
929 warnings.simplefilter("ignore")
--> 930 return not_none(self.generation_strategy).gen(
931 experiment=self.experiment,
932 n=n,
~/anaconda3/envs/cvnlp/lib/python3.8/site-packages/ax/modelbridge/generation_strategy.py in gen(self, experiment, data, n, **kwargs)
339 )
340 model = not_none(self.model)
--> 341 generator_run = model.gen(
342 n=n,
343 **consolidate_kwargs(
~/anaconda3/envs/cvnlp/lib/python3.8/site-packages/ax/modelbridge/base.py in gen(self, n, search_space, optimization_config, pending_observations, fixed_features, model_gen_options)
608
609 # Apply terminal transform and gen
--> 610 observation_features, weights, best_obsf, gen_metadata = self._gen(
611 n=n,
612 search_space=search_space,
~/anaconda3/envs/cvnlp/lib/python3.8/site-packages/ax/modelbridge/array.py in _gen(self, n, search_space, pending_observations, fixed_features, model_gen_options, optimization_config)
200 )
201 # Generate the candidates
--> 202 X, w, gen_metadata = self._model_gen(
203 n=n,
204 bounds=bounds,
~/anaconda3/envs/cvnlp/lib/python3.8/site-packages/ax/modelbridge/torch.py in _model_gen(self, n, bounds, objective_weights, outcome_constraints, linear_constraints, fixed_features, pending_observations, model_gen_options, rounding_func, target_fidelities)
202 tensor_rounding_func = self._array_callable_to_tensor_callable(rounding_func)
203 # pyre-fixme[16]: `Optional` has no attribute `gen`.
--> 204 X, w, gen_metadata = self.model.gen(
205 n=n,
206 bounds=bounds,
~/anaconda3/envs/cvnlp/lib/python3.8/site-packages/ax/models/torch/botorch.py in gen(self, n, bounds, objective_weights, outcome_constraints, linear_constraints, fixed_features, pending_observations, model_gen_options, rounding_func, target_fidelities)
355 inequality_constraints = None
356
--> 357 acquisition_function = self.acqf_constructor( # pyre-ignore: [28]
358 model=model,
359 objective_weights=objective_weights,
~/anaconda3/envs/cvnlp/lib/python3.8/site-packages/ax/models/torch/botorch_defaults.py in get_NEI(model, objective_weights, outcome_constraints, X_observed, X_pending, **kwargs)
200 objective=obj_tf, constraints=con_tfs or [], infeasible_cost=inf_cost
201 )
--> 202 return get_acquisition_function(
203 acquisition_function_name="qNEI",
204 model=model,
~/anaconda3/envs/cvnlp/lib/python3.8/site-packages/botorch/acquisition/utils.py in get_acquisition_function(acquisition_function_name, model, objective, X_observed, X_pending, mc_samples, qmc, seed, **kwargs)
86 )
87 elif acquisition_function_name == "qNEI":
---> 88 return monte_carlo.qNoisyExpectedImprovement(
89 model=model,
90 X_baseline=X_observed,
~/anaconda3/envs/cvnlp/lib/python3.8/site-packages/botorch/acquisition/monte_carlo.py in __init__(self, model, X_baseline, sampler, objective, X_pending, prune_baseline)
216 )
217 if prune_baseline:
--> 218 X_baseline = prune_inferior_points(
219 model=model, X=X_baseline, objective=objective
220 )
~/anaconda3/envs/cvnlp/lib/python3.8/site-packages/botorch/acquisition/utils.py in prune_inferior_points(model, X, objective, num_samples, max_frac)
214 sampler = SobolQMCNormalSampler(num_samples=num_samples)
215 with torch.no_grad():
--> 216 posterior = model.posterior(X=X)
217 samples = sampler(posterior)
218 if objective is None:
~/anaconda3/envs/cvnlp/lib/python3.8/site-packages/botorch/models/gpytorch.py in posterior(self, X, output_indices, observation_noise, **kwargs)
300 X=X, original_batch_shape=self._input_batch_shape
301 )
--> 302 mvn = self(X)
303 if observation_noise is not False:
304 if torch.is_tensor(observation_noise):
~/anaconda3/envs/cvnlp/lib/python3.8/site-packages/gpytorch/models/exact_gp.py in __call__(self, *args, **kwargs)
326 # Make the prediction
327 with settings._use_eval_tolerance():
--> 328 predictive_mean, predictive_covar = self.prediction_strategy.exact_prediction(full_mean, full_covar)
329
330 # Reshape predictive mean to match the appropriate event shape
~/anaconda3/envs/cvnlp/lib/python3.8/site-packages/gpytorch/models/exact_prediction_strategies.py in exact_prediction(self, joint_mean, joint_covar)
300
301 return (
--> 302 self.exact_predictive_mean(test_mean, test_train_covar),
303 self.exact_predictive_covar(test_test_covar, test_train_covar),
304 )
~/anaconda3/envs/cvnlp/lib/python3.8/site-packages/gpytorch/models/exact_prediction_strategies.py in exact_predictive_mean(self, test_mean, test_train_covar)
318 # You **cannot* use addmv here, because test_train_covar may not actually be a non lazy tensor even for an exact
319 # GP, and using addmv requires you to delazify test_train_covar, which is obviously a huge no-no!
--> 320 res = (test_train_covar @ self.mean_cache.unsqueeze(-1)).squeeze(-1)
321 res = res + test_mean
322
~/anaconda3/envs/cvnlp/lib/python3.8/site-packages/gpytorch/utils/memoize.py in g(self, *args, **kwargs)
32 cache_name = name if name is not None else method
33 if not is_in_cache(self, cache_name):
---> 34 add_to_cache(self, cache_name, method(self, *args, **kwargs))
35 return get_from_cache(self, cache_name)
36
~/anaconda3/envs/cvnlp/lib/python3.8/site-packages/gpytorch/models/exact_prediction_strategies.py in mean_cache(self)
267
268 train_labels_offset = (self.train_labels - train_mean).unsqueeze(-1)
--> 269 mean_cache = train_train_covar.inv_matmul(train_labels_offset).squeeze(-1)
270
271 if settings.detach_test_caches.on():
~/anaconda3/envs/cvnlp/lib/python3.8/site-packages/gpytorch/lazy/lazy_tensor.py in inv_matmul(self, right_tensor, left_tensor)
932 func = InvMatmul
933 if left_tensor is None:
--> 934 return func.apply(self.representation_tree(), False, right_tensor, *self.representation())
935 else:
936 return func.apply(self.representation_tree(), True, left_tensor, right_tensor, *self.representation())
~/anaconda3/envs/cvnlp/lib/python3.8/site-packages/gpytorch/functions/_inv_matmul.py in forward(ctx, representation_tree, has_left, *args)
45 res = left_tensor @ res
46 else:
---> 47 solves = _solve(lazy_tsr, right_tensor)
48 res = solves
49
~/anaconda3/envs/cvnlp/lib/python3.8/site-packages/gpytorch/functions/_inv_matmul.py in _solve(lazy_tsr, rhs)
9 def _solve(lazy_tsr, rhs):
10 if settings.fast_computations.solves.off() or lazy_tsr.size(-1) <= settings.max_cholesky_size.value():
---> 11 return lazy_tsr._cholesky()._cholesky_solve(rhs)
12 else:
13 with torch.no_grad():
~/anaconda3/envs/cvnlp/lib/python3.8/site-packages/gpytorch/utils/memoize.py in g(self, *args, **kwargs)
32 cache_name = name if name is not None else method
33 if not is_in_cache(self, cache_name):
---> 34 add_to_cache(self, cache_name, method(self, *args, **kwargs))
35 return get_from_cache(self, cache_name)
36
~/anaconda3/envs/cvnlp/lib/python3.8/site-packages/gpytorch/lazy/lazy_tensor.py in _cholesky(self)
412
413 # contiguous call is necessary here
--> 414 cholesky = psd_safe_cholesky(evaluated_mat).contiguous()
415 return NonLazyTensor(cholesky)
416
~/anaconda3/envs/cvnlp/lib/python3.8/site-packages/gpytorch/utils/cholesky.py in psd_safe_cholesky(A, upper, out, jitter)
46 except RuntimeError:
47 continue
---> 48 raise e
~/anaconda3/envs/cvnlp/lib/python3.8/site-packages/gpytorch/utils/cholesky.py in psd_safe_cholesky(A, upper, out, jitter)
23 """
24 try:
---> 25 L = torch.cholesky(A, upper=upper, out=out)
26 return L
27 except RuntimeError as e:
RuntimeError: cholesky_cpu: U(63,63) is zero, singular U.
 leopd
leopd
All 11 comments
Hi @leopd, this error occurs because the train-train covariance matrix of the underlying GP model is badly conditioned. This can happen e.g. when there are ton of points in the training data that are clustered very closely together or even repeated. That in turn can happen if the model becomes very certain that a particular point is the best point.
From your log it seems there are a lot of 1000s for the fc_dim parameter, which indicates the model is quite sure about that setting. So from a practical perspective ("how do train this thing?") I'd say either (i) increase the bound on that and see if the model finds something better, or (ii) if you can't, fix fc_dim=1000 and run the tuning without this parameter.
From a software robustness perspective, the answer is a little less satisfying - essentially we can add more jitter to the psd_safe_cholesky call in GPyTorch. Unfortunately that's currently not straightforward to do this from the Ax interface, so we'll have to make some internal changes to adaptively increase the jitter (or solve the linear system a different way). Thanks for your example log though, I will ingest that and see what the model looks like.
 Balandat
on 4 May 2020
Balandat
on 4 May 2020
That makes a lot of sense. Thanks for the explanation.
leopd
on 5 May 2020
I'm of the opinion that numeric stability by itself isn't worth a huge effort to fix when the underlying issue really comes down to operator error -- or put another way, that moving forwards appropriately really requires operator attention. I think the most appropriate fix here might be a better error message saying something like "Perhaps one or more parameters has converged?" Automated diagnosis of this would be nice, but again seems like more effort than it's worth. This github issue will help certainly help document it for future users, but a bit more of an explicit message would be a sufficient fix IMHO.
leopd
on 5 May 2020
Agreed, cc @lena-kashtelyan , whom I was just discussing this with!
 ldworkin
on 5 May 2020
ldworkin
on 5 May 2020
@leopd, are you passing 0.0 (noiseless) or np.nan as the sem back to the client in your optimization?
FWIW, I was digging into your logs and was trying hard to make the optimization to fail by repeating some arm with fc_dim=1000 100+ times, but I didn't get it to fail. Good news I guess?That makes me think that maybe this is just some very rare event driven by getting really unlucky in the randomized initialization heuristic. Maybe it is as straightforward as just re-trying the generation upon failure, possibly after refitting the model to make sure this is not caused by some wonky hyperparameters.
Balandat
on 5 May 2020
To be clear, that retrying should be handled internally by Ax and doesn't need to be visible to the user.
Balandat
on 5 May 2020
I'm not passing either for SEM - just passing a float:
self.ax_client.complete_trial(trial_index=self.trial_index, raw_data=float(objective_val))
so whatever the default is. My understanding from the docs is that this should cause the noise to be treated as a free parameter to optimize for. This problem should not be treated as noiseless.
leopd
on 5 May 2020
Yes, that will use the default behavior of inferring the noise level.
Balandat
on 5 May 2020
So to summarize, I believe the takeaways here are:
1) Adding retrying internally in Ax (and have it increase jitter on each retry)
2) Surfacing a better error message in the case of this failure
ldworkin
on 14 May 2020
So one other thing to worry about here is outliers in the data. See a histogram of the test_error from @leopd's log below:
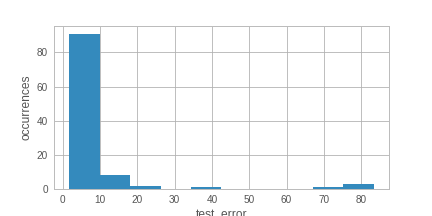
The outlier values around 80, while not completely crazy, can really throw off the hyperparameter estimation of the GP model. If that happens the model is essentially bogus and numerical issues are to be expected.
This can be mitigated by applying transformations to the data, common ones are winsorizing the data or applying a (often Gaussian) copula transform to the data.
While Ax by default does normalize the inputs and standardize the outputs for modeling, we do not winsorize or copula-transform at this point. However, we plan to make these transformations readily available in Ax going forward.
In the meantime, a practical question for @leopd is whether a test_error of ~80 makes sense in this context. If you really only care about the best setting and not so much how good your model fits in bad areas, you can just clamp that to some smaller value that still signals that the outcome is "really bad" (maybe that's something like 25 in this setting, looking at the histogram?). I believe that that should already help quite a bit with the numerical issues.
Balandat
on 14 May 2020
Moving discussion on this to #228, since the two issues appear to be duplicates.
 lena-kashtelyan
on 28 Aug 2020
lena-kashtelyan
on 28 Aug 2020
Related issues
 Pzmijewski
·
3Comments
Pzmijewski
·
3Comments
 richarddwang
·
4Comments
Pzmijewski
·
3Comments
richarddwang
·
4Comments
Pzmijewski
·
3Comments
 showgood163
·
3Comments
showgood163
·
3Comments
 dkatz23238
·
5Comments
dkatz23238
·
5Comments
Most helpful comment
I'm of the opinion that numeric stability by itself isn't worth a huge effort to fix when the underlying issue really comes down to operator error -- or put another way, that moving forwards appropriately really requires operator attention. I think the most appropriate fix here might be a better error message saying something like "Perhaps one or more parameters has converged?" Automated diagnosis of this would be nice, but again seems like more effort than it's worth. This github issue will help certainly help document it for future users, but a bit more of an explicit message would be a sufficient fix IMHO.