Awx: unscheduleable jobs sent to container group are never cleaned up and jobs fail with timeout
ISSUE TYPE
- Bug Report
SUMMARY
If a job is sent to a container group, and there is no ResourceQuota specified, pods will be enqueued but potentially run into being Unschedulable and get stuck in "Pending" on the cluster.
Then jobs either fail with timeout on tower side, or if we attempt to cancel the job, the job gets canceled on tower but never taken out of queue on the container group cluster.
STEPS TO REPRODUCE
Create a working container group
It is easier to control the available resources if you create your own node pool @unlikelyzero can help with that. Create a node that only has 2 CPUs available.
Modify the pod_spec to look like this (but with the right namespace for your setup)
apiVersion: v1
kind: Pod
metadata:
namespace: YOURNAMESPACE
spec:
containers:
- image: ansible/ansible-runner
resources:
requests:
cpu: “2”
tty: true
stdin: true
imagePullPolicy: Always
args:
- sleep
- infinity
nodeSelector:
YOURSELECTORFORYOURNODEPOOL
Create a JT that sleeps for 30 seconds, enable simultaneous and assign the container group
Create a WFJT that has 10 nodes that should run simultaneously this JT, enable simultaneous
Launch the WFJT several times
Cancel some of the later launches after the pods appear as pending in the kubernetes cluster.
EXPECTED RESULTS
Slowly work through each job as resources are available.
ACTUAL RESULTS
Some jobs fail with timeout, canceled jobs never clean up their pods.
ADDITIONAL INFORMATION
@one-t and @unlikelyzero and I found this while trying to investigate a related potential problem:
WITH a container group in a cluster with no ResourceQuota defined
WHEN a JT has regular tower instance groups + container group assigned (with preference for tower instance groups)
WHEN all tower instance groups capacity is consumed
THEN....all subsequent jobs will get funneled to the container group, even if this exceeds its resource capacity and jobs will sit in pending for a long time even after regular tower instance groups have gotten capacity freed up.
I think ^ is a real scenario, potentially more root cause of this bug itself...potentially we could check the pods that are in pending and see if they are Unschedulable and then un-assign them from the container group and re-dispatch them to other instance groups if available.
This is what a pod that is stuck in this Unschedulable state looks like:
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: "2019-10-09T20:37:42Z"
name: job-181
namespace: default
resourceVersion: "65442511"
selfLink: /api/v1/namespaces/default/pods/job-181
uid: a47a0397-ead4-11e9-894a-42010a8e00ca
spec:
containers:
- args:
- sleep
- infinity
image: ansible/ansible-runner
imagePullPolicy: Always
name: job-181
resources:
requests:
cpu: 2k
stdin: true
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
tty: true
volumeMounts:
- mountPath: /var/run/secrets/kubernetes.io/serviceaccount
name: default-token-dtdds
readOnly: true
dnsPolicy: ClusterFirst
nodeSelector:
cloud.google.com/gke-nodepool: pre-emptible-pool
priority: 0
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
serviceAccount: default
serviceAccountName: default
terminationGracePeriodSeconds: 30
tolerations:
- effect: NoExecute
key: node.kubernetes.io/not-ready
operator: Exists
tolerationSeconds: 300
- effect: NoExecute
key: node.kubernetes.io/unreachable
operator: Exists
tolerationSeconds: 300
volumes:
- name: default-token-dtdds
secret:
defaultMode: 420
secretName: default-token-dtdds
status:
conditions:
- lastProbeTime: "2019-10-09T20:44:30Z"
lastTransitionTime: "2019-10-09T20:37:42Z"
message: '0/5 nodes are available: 2 node(s) didn''t match node selector, 5 Insufficient
cpu.'
reason: Unschedulable
status: "False"
type: PodScheduled
phase: Pending
qosClass: Burstable
 kdelee
kdelee
All 11 comments
I think this is going to have to be handled as part of a more general pod reaper re: https://github.com/ansible/awx/issues/4911
 ryanpetrello
on 9 Oct 2019
ryanpetrello
on 9 Oct 2019
@ryanpetrello to give a bit more info:
recreated this again with the code from this PR just want to point out that UnSchedulable pods are Pending with the "problem" of being UnSchedulable so you have to look at more info than the "phase"
kdelee
on 11 Oct 2019
@kdelee I think this problem will be alleviated by https://github.com/ansible/tower/pull/3852 (jobs will still get marked as failed in Tower, but orphaned k8s pods won't be left behind)
ryanpetrello
on 17 Oct 2019
fixes for https://github.com/ansible/awx/issues/4911 and https://github.com/ansible/awx/issues/4909 appear to have fixed this, going to poke a bit more
kdelee
on 21 Oct 2019
@kdelee says maybe his isn't fixed, so I'm going to take another look
ryanpetrello
on 21 Oct 2019
yeah, I was wrong...still same problem. stuck in waiting....
kdelee
on 21 Oct 2019
@one-t @kdelee @shanemcd I'm not sure I really understand why the current behavior is wrong, per-se, because as I understand the example you've cited, the pod is never actually entering the Running phase (and AWX just retries in a loop over and over, right?)
https://github.com/ansible/awx/pull/4922/files#r334029409
If the pod is in Pending with reason: Unschedulable, doesn't that suggest that at some point in the near future it _could_ become schedulable? If that's the case, I'm a little torn about whether or not finding an Unschedulable condition means we should insta-fail.
In a scenario like this (when we discover a condition at pod launch w/ reason: Unschedulable), are you suggesting that the correct behavior is to fail the job immediately?
If that is what you're suggesting, what do you think about a diff like this?
diff --git a/awx/main/scheduler/kubernetes.py b/awx/main/scheduler/kubernetes.py
index 68a95e2fc2..b0a5822ac4 100644
--- a/awx/main/scheduler/kubernetes.py
+++ b/awx/main/scheduler/kubernetes.py
@@ -35,6 +35,9 @@ class PodManager(object):
break
else:
logger.debug(f"Pod {self.pod_name} is Pending.")
+ for condition in pod.status.conditions:
+ if condition.reason == 'Unschedulable':
+ raise RuntimeError('Could not schedule pod: {}'.format(condition.message)
time.sleep(settings.AWX_CONTAINER_GROUP_POD_LAUNCH_RETRY_DELAY)
continue
An alternative might be to make it so that a failure to enter Running phase _after N retries_ raises a loud explicit exception:
diff --git a/awx/main/scheduler/kubernetes.py b/awx/main/scheduler/kubernetes.py
index 68a95e2fc2..a50622a2a8 100644
--- a/awx/main/scheduler/kubernetes.py
+++ b/awx/main/scheduler/kubernetes.py
@@ -42,7 +42,7 @@ class PodManager(object):
logger.debug(f"Pod {self.pod_name} is online.")
return pod
else:
- logger.warn(f"Pod {self.pod_name} did not start. Status is {pod.status.phase}.")
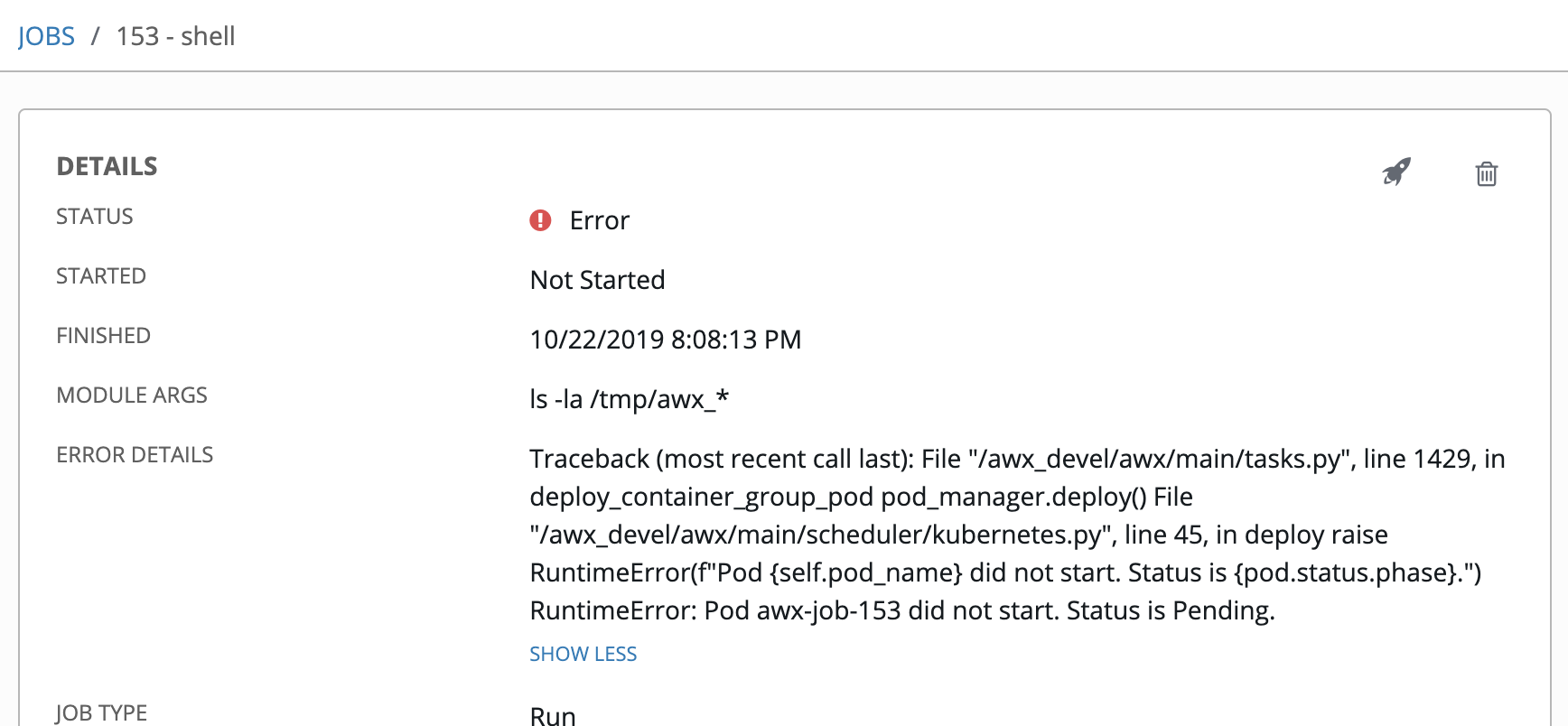
+ raise RuntimeError(f"Pod {self.pod_name} did not start. Status is {pod.status.phase}.")
@classmethod
def list_active_jobs(self, instance_group):
ryanpetrello
on 23 Oct 2019
@shanemcd
I think we might also consider lowering this default to something more reasonable:
awx/settings/defaults.py
71:AWX_CONTAINER_GROUP_POD_LAUNCH_RETRIES = 100
5s * 100 retries is a _long_ time (over 8 minutes). Maybe 12 retries would be better as a default (give k8s one minute, then move on?)
ryanpetrello
on 23 Oct 2019
@ryanpetrello
When I filed this I was basically thinking of this scenario:
Tower is saturated with jobs, all normal instances are currently at capacity
At this moment, the container group becomes a funnel for jobs, all pending jobs get directed to Tower
Then, capacity becomes available on normal instance groups, but all jobs are currently scheduled on container group and sitting around waiting for capacity on container group.
My example of the excessive resource request is extreme, and to provoke the scenario where it gets UnScheduleable.
My idea is if it stays stuck in Pending with UnScheduleable until
So really, perhaps there are two scenarios: the one where container group becomes funnel for jobs in "saturated" tower, and the other where the pod spec is screwed up and no job is ever going to get scheduled on the k8s cluster due to excessive resource request.
kdelee
on 23 Oct 2019
Yea, at this point in time, I think it's too risky to introduce a change where we'd identify a saturated container group and move a job to a different instance group. For that sort of change, we probably need to brainstorm on some task manager changes (and that is a bit to risky for me). For it to be successful, it would also likely need to be driven by some sort of functionality where we could track container group availability (similar to our capacity measurement for normal instance groups).
My example of the excessive resource request is extreme, and to provoke the scenario where it gets UnScheduleable.
If this is the major sticking point for this issue (and the things we've addressed w/ the introduction of the pod reaper are good enough), I think I'd prefer to try to solve this problem later.
ryanpetrello
on 23 Oct 2019
closing in favor of the RFE #5083
kdelee
on 23 Oct 2019
Related issues
 beenje
·
3Comments
beenje
·
3Comments
 darkaxl
·
3Comments
darkaxl
·
3Comments
 astraios
·
3Comments
astraios
·
3Comments
 Gui13
·
3Comments
Gui13
·
3Comments
 agaffney
·
3Comments
agaffney
·
3Comments