Awx: In the Workflow Result Viewer, real-time events of WFs in WFs are out of order
ISSUE TYPE
- Bug Report
COMPONENT NAME
- UI
SUMMARY
In the Workflow Result Viewer, real-time events of WFs in WFs are out of order. In the simplest case, the
ENVIRONMENT
- AWX version: 3.4.0
- AWX install method: openshift, minishift, docker on linux, docker for mac, boot2docker
- Ansible version: X.Y.Z
- Operating System:
- Web Browser:
STEPS TO REPRODUCE
The simplest case:
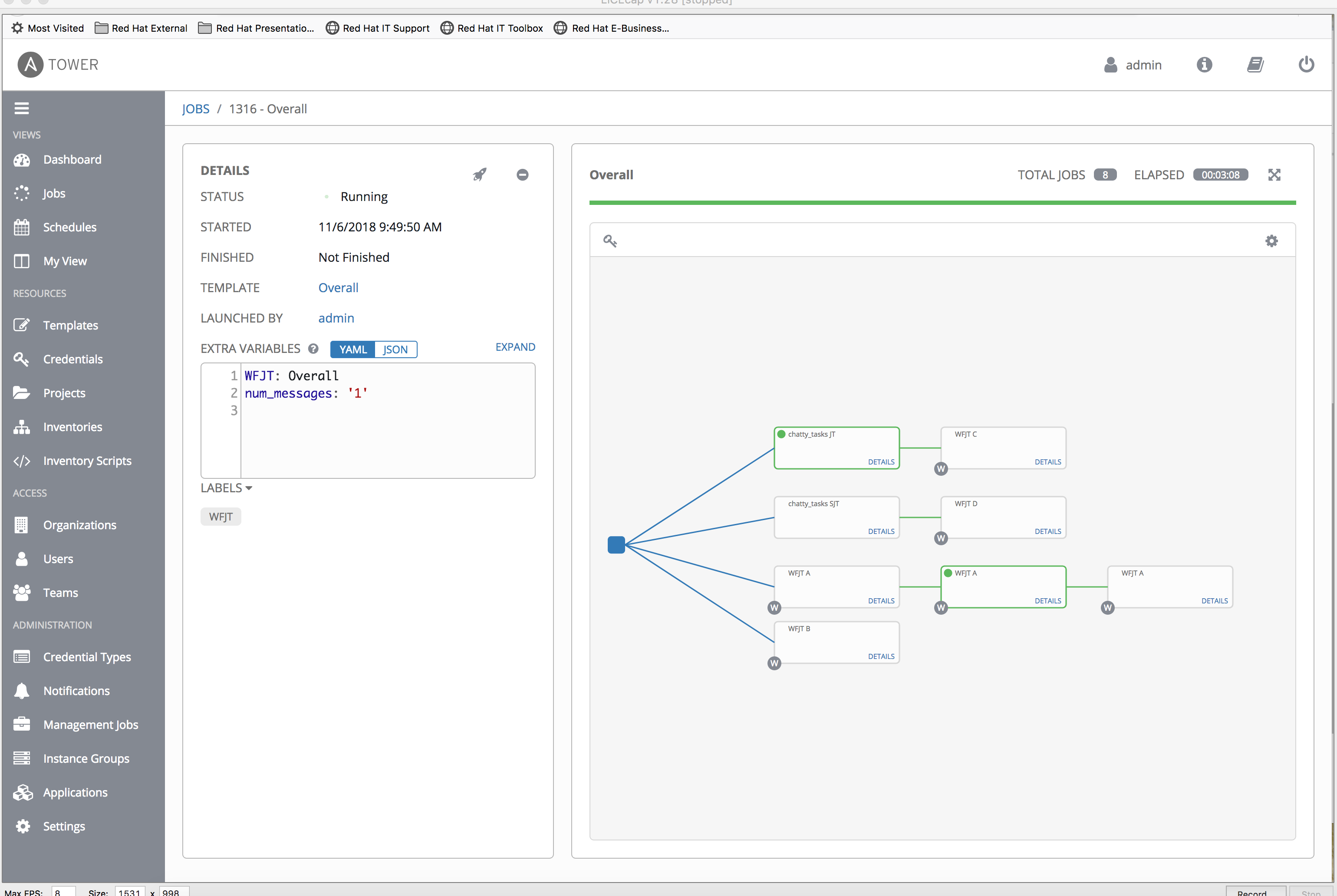
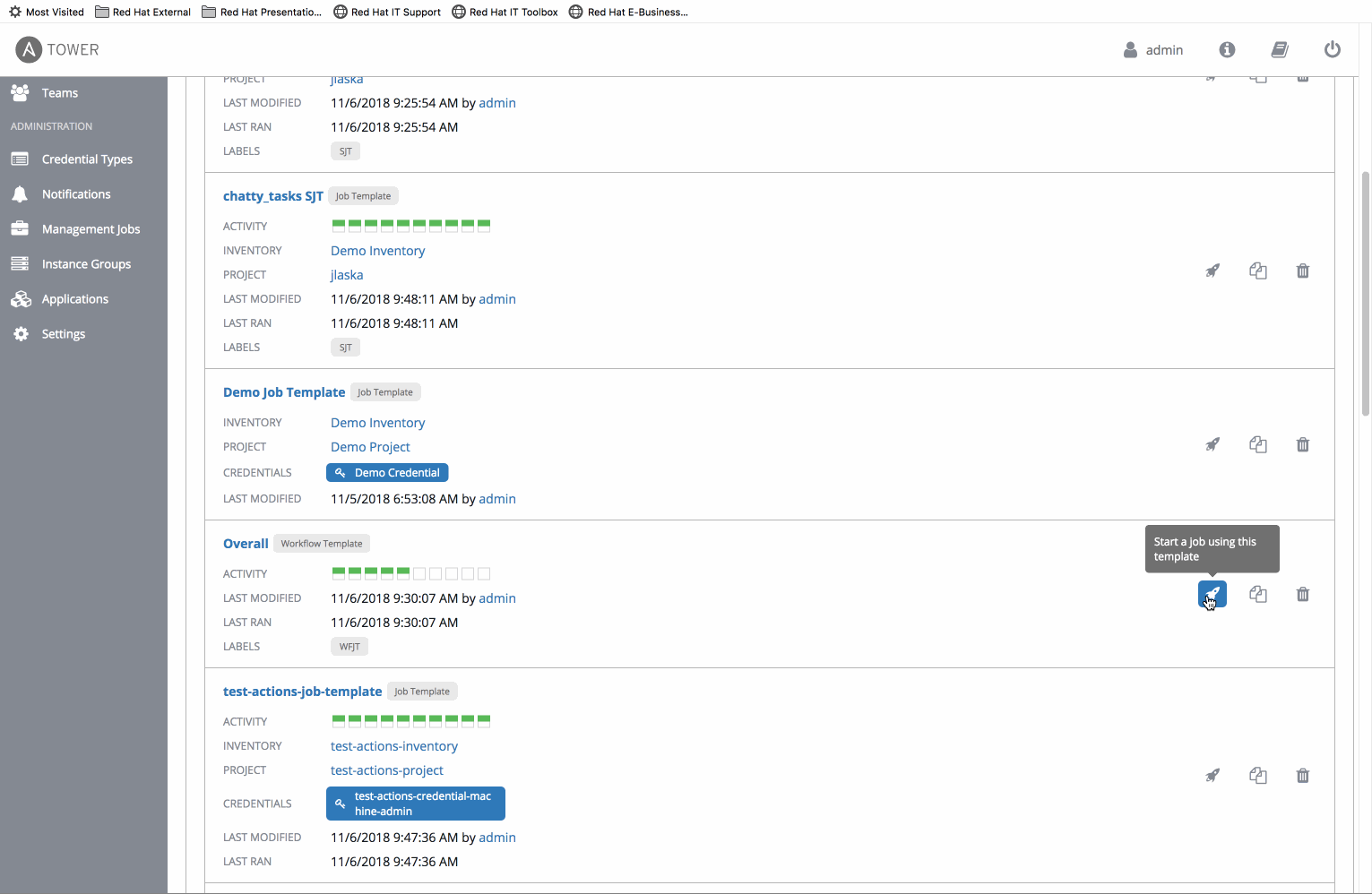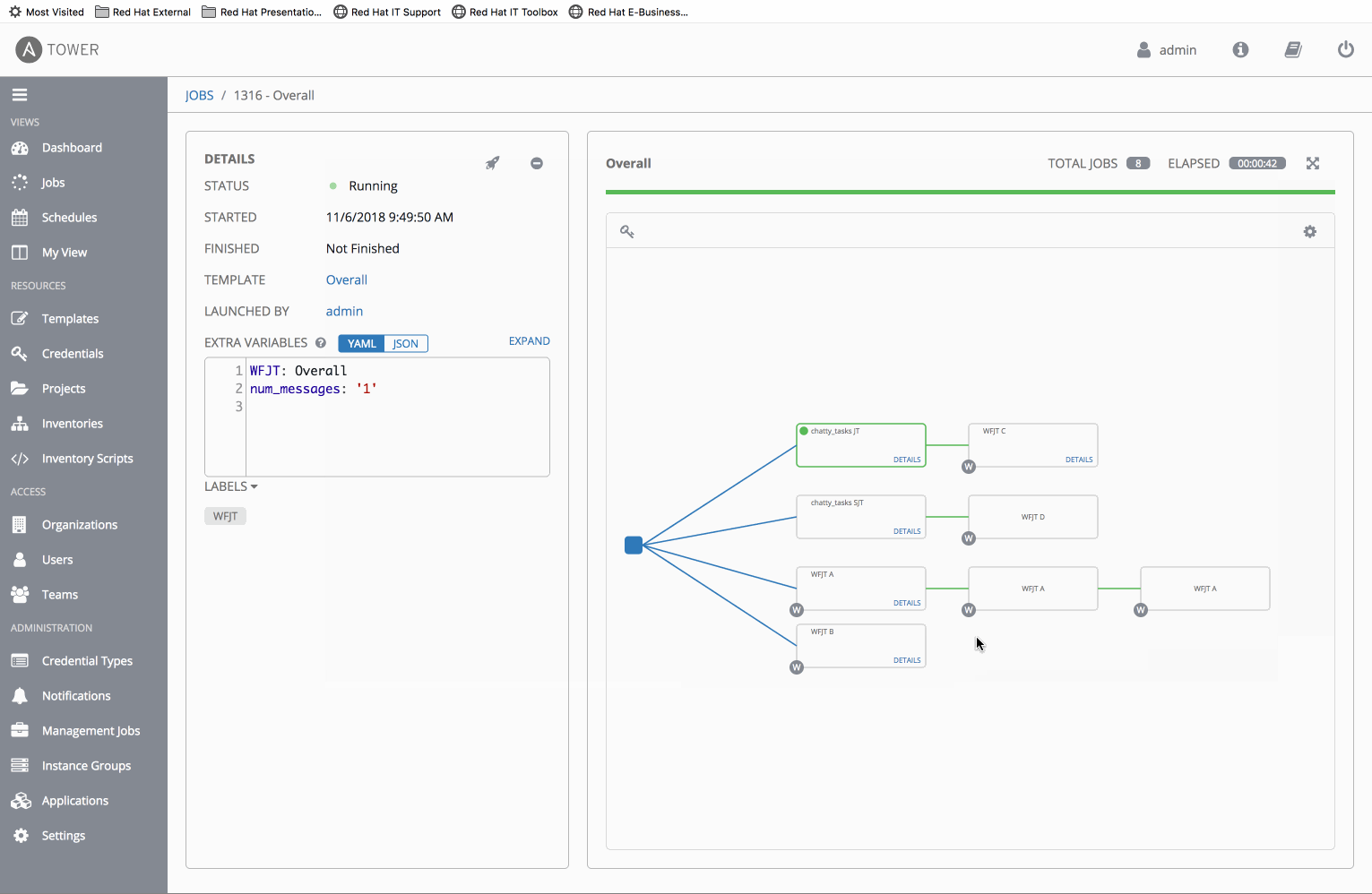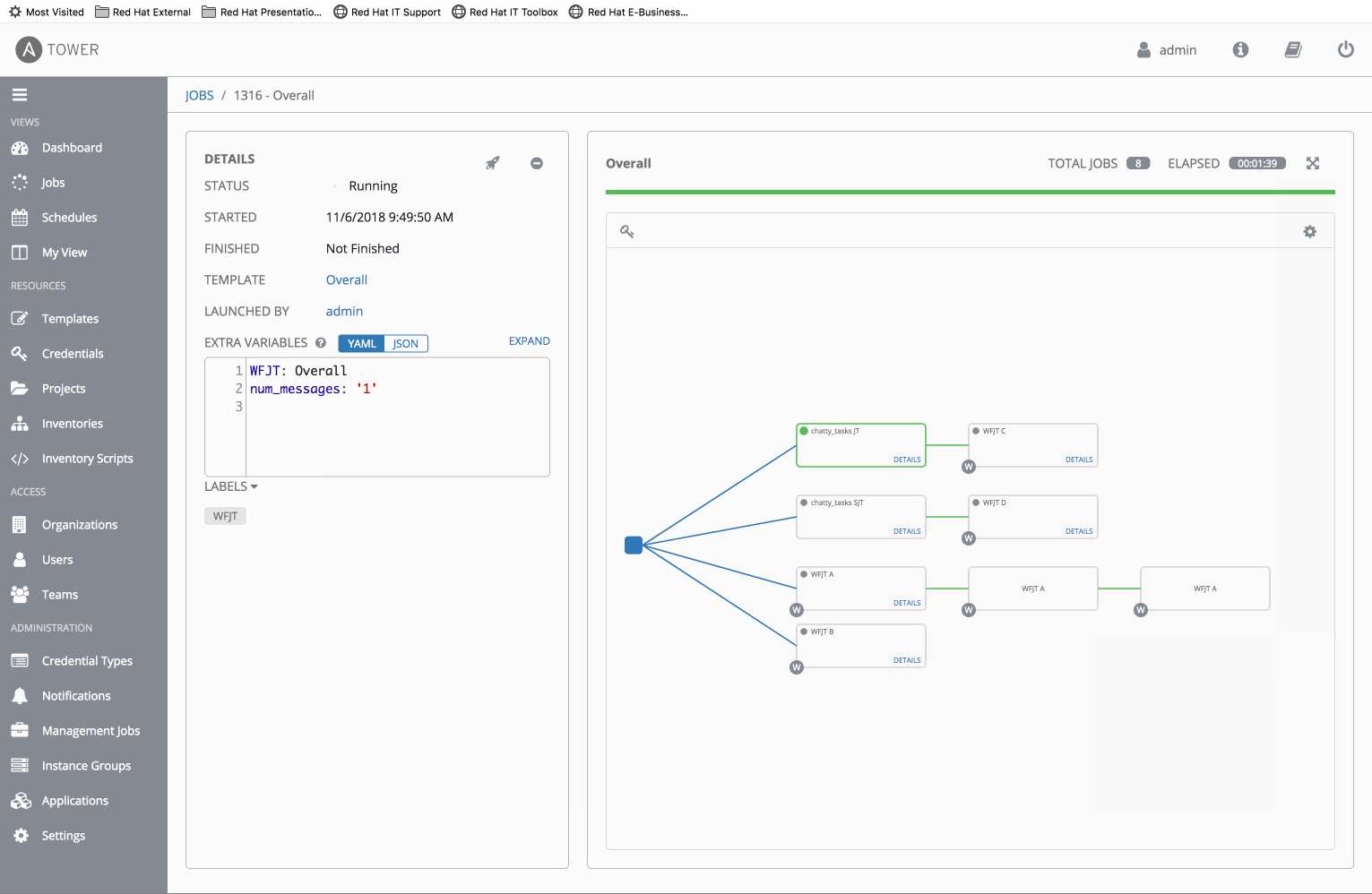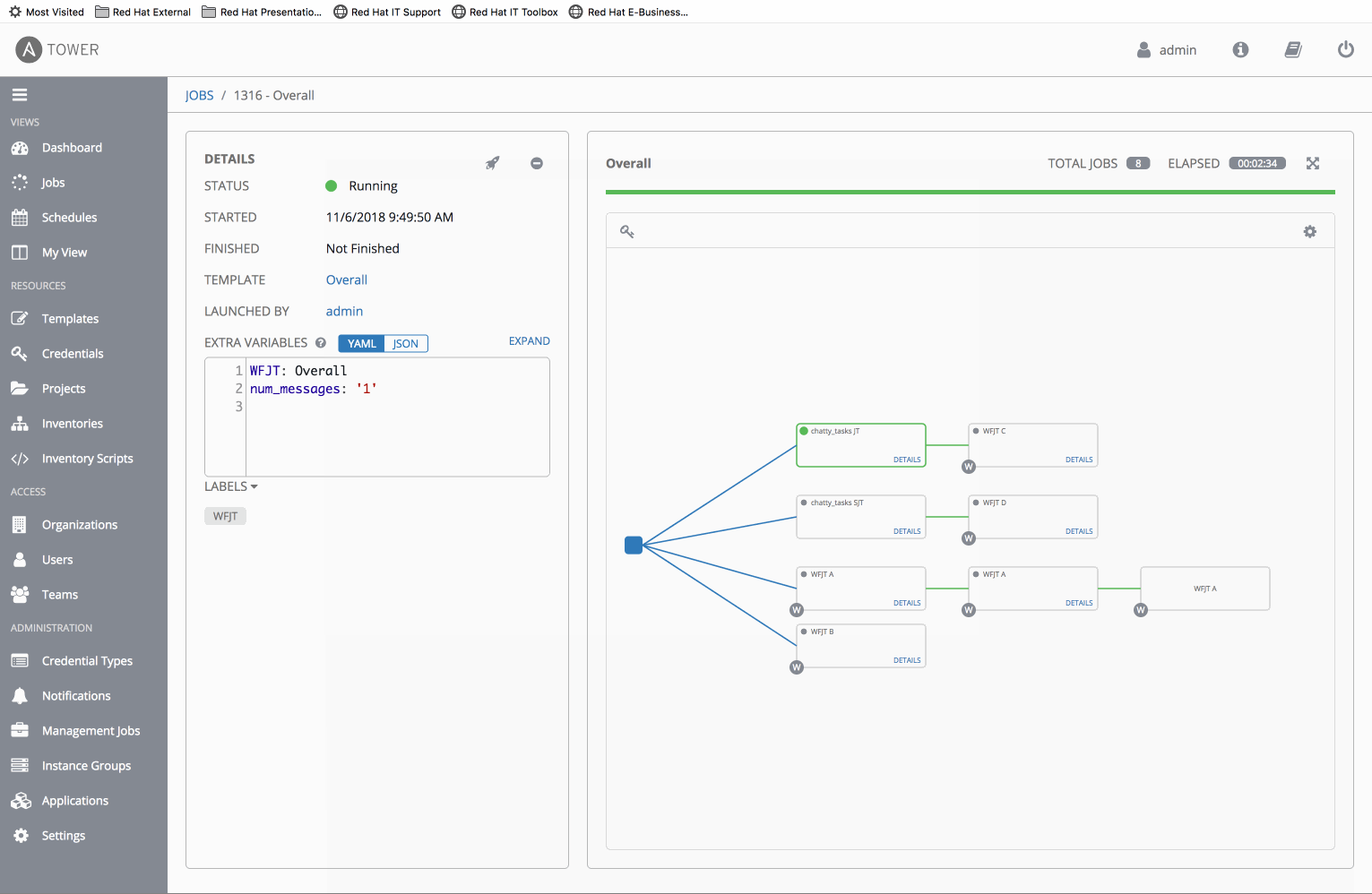
- Create a WF-in-WF scenario with chatty_tasks
⋅⋅1.WFJT Awhich contains chatty_tasks JT
⋅⋅1.WFJT Bwhich contains 3 chainedWFJT Ajobs - Run
WFJT Band note that WF job events return out of order. i.e. The secondWFJT Acan appear to complete before the first.
EXPECTED RESULTS
WFJT results to come back in the order they are executed and finished
ACTUAL RESULTS
WFJT B "finishes" before WFJT A chained A -> B
ADDITIONAL INFORMATION
 unlikelyzero
unlikelyzero
All 8 comments
I had a chance to look at the data, and I wish I could say that something jumps out at me regarding the timings.
some notes:
overall workflow
started
7:51:34am
finished
5:55:59am
from job in leaf workflow:
https://{url}/api/v2/jobs/855/job_events/?order_by=-created
"created": "2018-11-06T12:55:16.075114Z",
project update event from inside root node
"created": "2018-11-06T12:51:54.604999Z",
job event from inside root node
"created": "2018-11-06T12:51:55.455108Z",
The job events aren't coming in at some crazy late time. We can't account for this behavior by a pileup of events in the callback receiver.
 AlanCoding
on 6 Nov 2018
AlanCoding
on 6 Nov 2018
My best guess is that the messages just aren't getting routed to their nodes somehow.
Examples:
group_name: "jobs"
status: "successful"
unified_job_id: 1002
workflow_job_id: 998
workflow_node_id: 591
group_name: "jobs"
status: "successful"
unified_job_id: 998
workflow_job_id: 912
workflow_node_id: 539
This is difficult to read, but the content appears correct. Workflow job 998 is running inside of workflow job 912.
You can see that the successful status of the workflow job is returned, and it follows right after a job inside of that workflow (predictable).
AlanCoding
on 6 Nov 2018
@jakemcdermott any thoughts here?
unlikelyzero
on 6 Nov 2018
The UI is not receiving successful updates for some nodes via web sockets. Reproduced it in the following scenario.
_chatty_tasks SJT_ is workflow_node_id: 1095
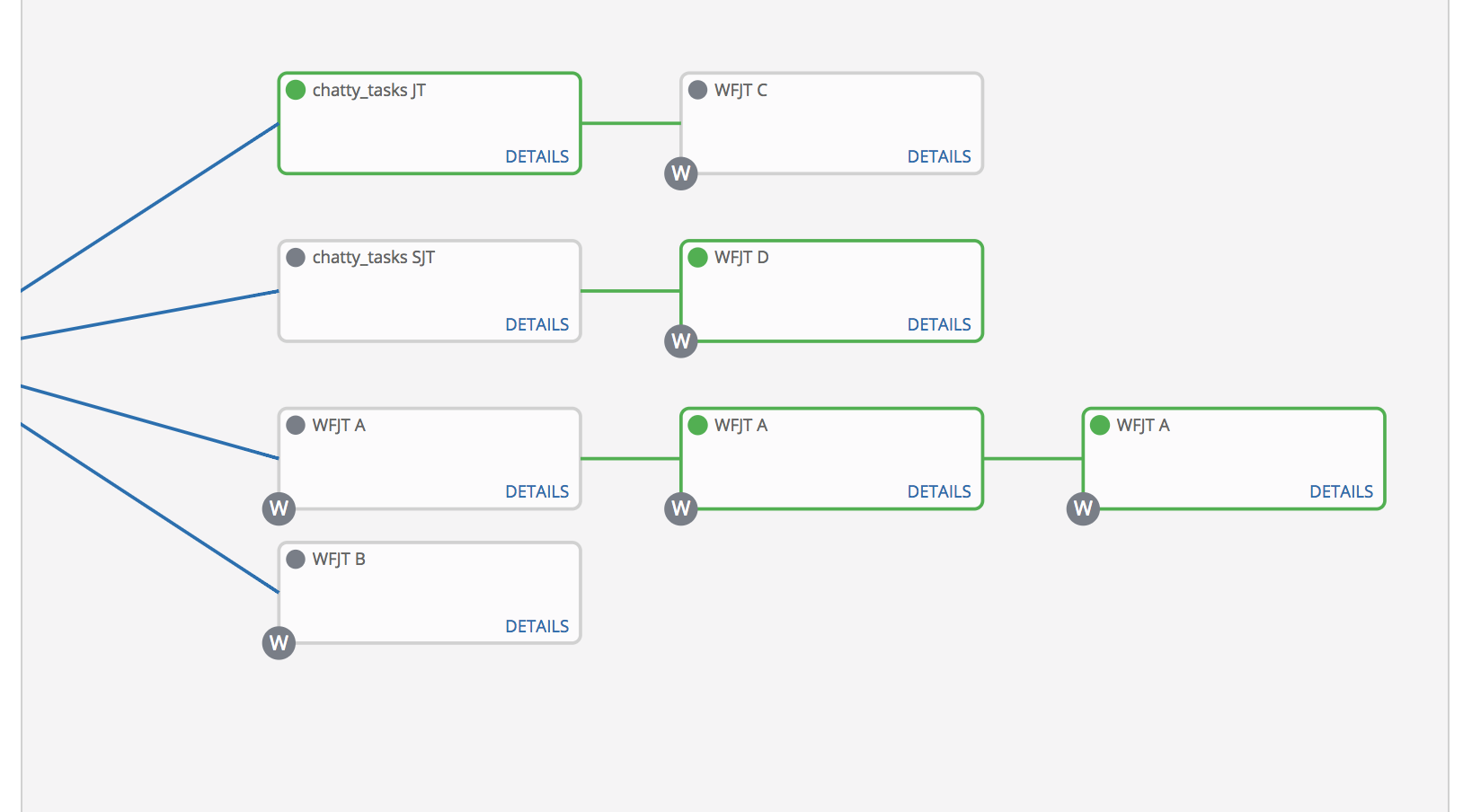
After the entire workflow job finished successfully, I filtered the websocket requests and we never received a status: successful for workflow_node_id: 1095

 marshmalien
on 6 Nov 2018
marshmalien
on 6 Nov 2018
Thanks for finding that information, I'm digging in right now.
One thing that is clear is that I was _only_ able to reproduce with split JTs were also in the picture. When they are used, some workflow job success messages are lost, but some SJT success messages are lost. Interestingly, some success messages for other WFJs are duplicated. This would likely hint at the root cause.
AlanCoding
on 6 Nov 2018
This diff seems to resolve the problem
diff --git a/awx/main/scheduler/task_manager.py b/awx/main/scheduler/task_manager.py
index 0d7c528566..5ef2ed462d 100644
--- a/awx/main/scheduler/task_manager.py
+++ b/awx/main/scheduler/task_manager.py
@@ -152,7 +152,8 @@ class TaskManager():
if not can_start:
job.status = 'failed'
job.save(update_fields=['status', 'job_explanation'])
- connection.on_commit(lambda: job.websocket_emit_status('failed'))
+ job.websocket_emit_status('failed')
+ # connection.on_commit(lambda: job.websocket_emit_status('failed'))
# TODO: should we emit a status on the socket here similar to tasks.py awx_periodic_scheduler() ?
#emit_websocket_notification('/socket.io/jobs', '', dict(id=))
@@ -169,7 +170,8 @@ class TaskManager():
workflow_job.status = 'canceled'
workflow_job.start_args = '' # blank field to remove encrypted passwords
workflow_job.save(update_fields=['status', 'start_args'])
- connection.on_commit(lambda: workflow_job.websocket_emit_status(workflow_job.status))
+ workflow_job.websocket_emit_status(workflow_job.status)
+ # connection.on_commit(lambda: workflow_job.websocket_emit_status(workflow_job.status))
else:
is_done, has_failed = dag.is_workflow_done()
if not is_done:
@@ -181,7 +183,8 @@ class TaskManager():
workflow_job.status = new_status
workflow_job.start_args = '' # blank field to remove encrypted passwords
workflow_job.save(update_fields=['status', 'start_args'])
- connection.on_commit(lambda: workflow_job.websocket_emit_status(workflow_job.status))
+ workflow_job.websocket_emit_status(workflow_job.status)
+ # connection.on_commit(lambda: workflow_job.websocket_emit_status(workflow_job.status))
return result
def get_dependent_jobs_for_inv_and_proj_update(self, job_obj):
@@ -247,7 +250,6 @@ class TaskManager():
self.consume_capacity(task, rampart_group.name)
def post_commit():
- task.websocket_emit_status(task.status)
if task.status != 'failed' and type(task) is not WorkflowJob:
task_cls = task._get_task_class()
task_cls.apply_async(
@@ -266,6 +268,7 @@ class TaskManager():
}],
)
+ task.websocket_emit_status(task.status) # adds to on_commit
connection.on_commit(post_commit)
def process_running_tasks(self, running_tasks):
My local testing replicated the issue, and then confirmed that it was fixed by:
464720495c2b11feb5f8db4a6adaa8eae2b21622
AlanCoding
on 6 Nov 2018
Tested this and verified with example scenario, looks correct to me.
 dsesami
on 7 Nov 2018
dsesami
on 7 Nov 2018
Related issues
 darkaxl
·
3Comments
marshmalien
·
3Comments
darkaxl
·
3Comments
marshmalien
·
3Comments
 icsm2017
·
4Comments
icsm2017
·
4Comments
 grahamn-gr
·
3Comments
grahamn-gr
·
3Comments
 shortsteps
·
3Comments
shortsteps
·
3Comments
Most helpful comment
This diff seems to resolve the problem