Awx: Workflow Template shows incorrect Success state
ISSUE TYPE
- Feature Request
COMPONENT NAME
- UI
SUMMARY
Workflow Template shows Successful, when a part of the workflow failed.
Is this expected? I would see it as a false positive, saying the Workflow went to the end as a "success"
ENVIRONMENT
- AWX version: ece93c45c9c932cfbfba2b44e217e99a6bb6a752
- Ansible version: 2.4.0.0
- Operating System: Proxmox Ubuntu 16.04 server
- Web Browser: Chrome
 naisanza
naisanza
All 12 comments
Indeed see: http://docs.ansible.com/ansible-tower/latest/html/userguide/workflows.html#workflow-states
I need more details on your workflow... did you have a "failed" path that was executed appropriately? IIRC we will only treat it as a problem if we encounter an unintended path.
 matburt
on 23 Sep 2017
matburt
on 23 Sep 2017
@matburt I actually made it wrong by mistake, but it still feels like a false positive. The Workflow Template goes as:
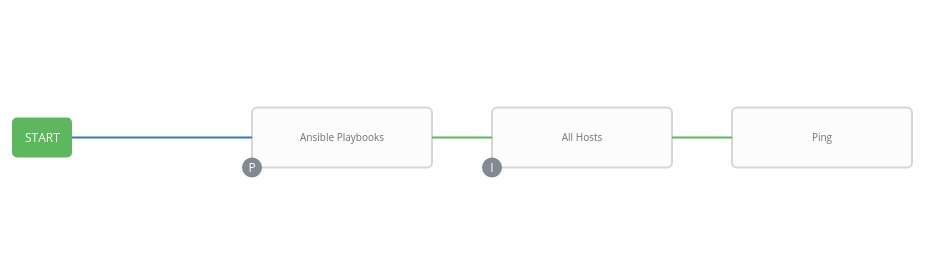
(1) Ansible Playbooks is a git project that gets updated successfully
(2) All Hosts is actually an Inventory Source tied to a git project called Ansible Hosts (not Ansible Playbooks)
So the (2) was failing, because I had a bad commit, and since Ansible Hosts wasn't being updated at (1), this causes All Hosts to continue failing when run against the same bad commit
The correct workflow should be:
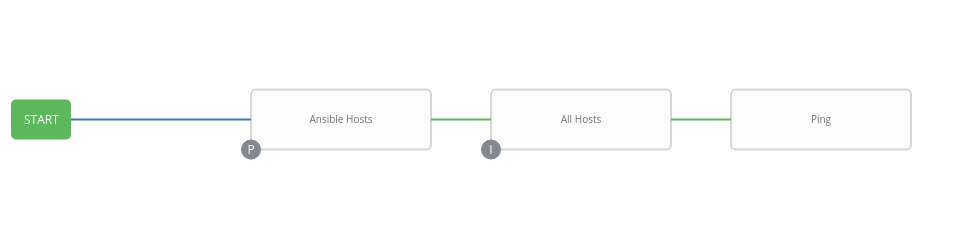
So this means even though (1) passes, (2) fails, the Workflow Template still stays it was successful, even though there was a failure in the Workflow. Also there is no "failed" path
What makes sense to me is:
[START] --> [PASS] --> (if success) --> [FAIL] <== this should be a Failed Run, but says is successful
Even if it were on a "failed" path it should still be the same:
[START] --> [PASS] --> (if failed) --> [FAIL] <== this should be a Failed Run, as well
naisanza
on 23 Sep 2017
Interesting, we'll investigate this.
matburt
on 23 Sep 2017
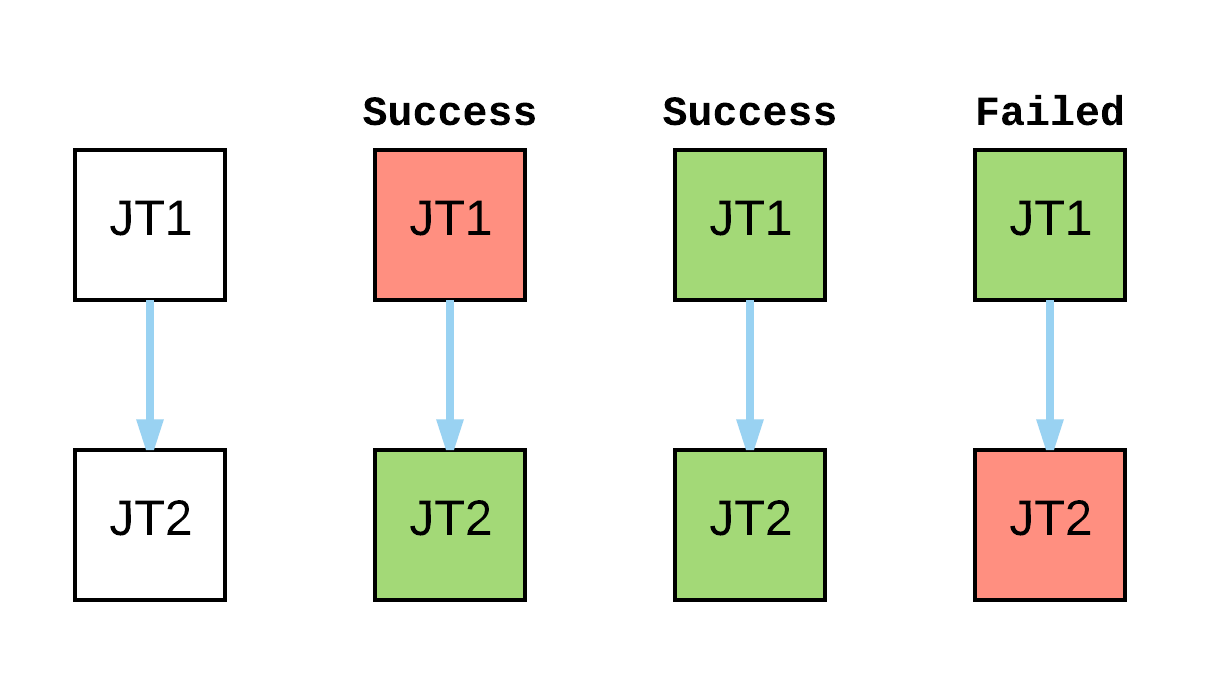
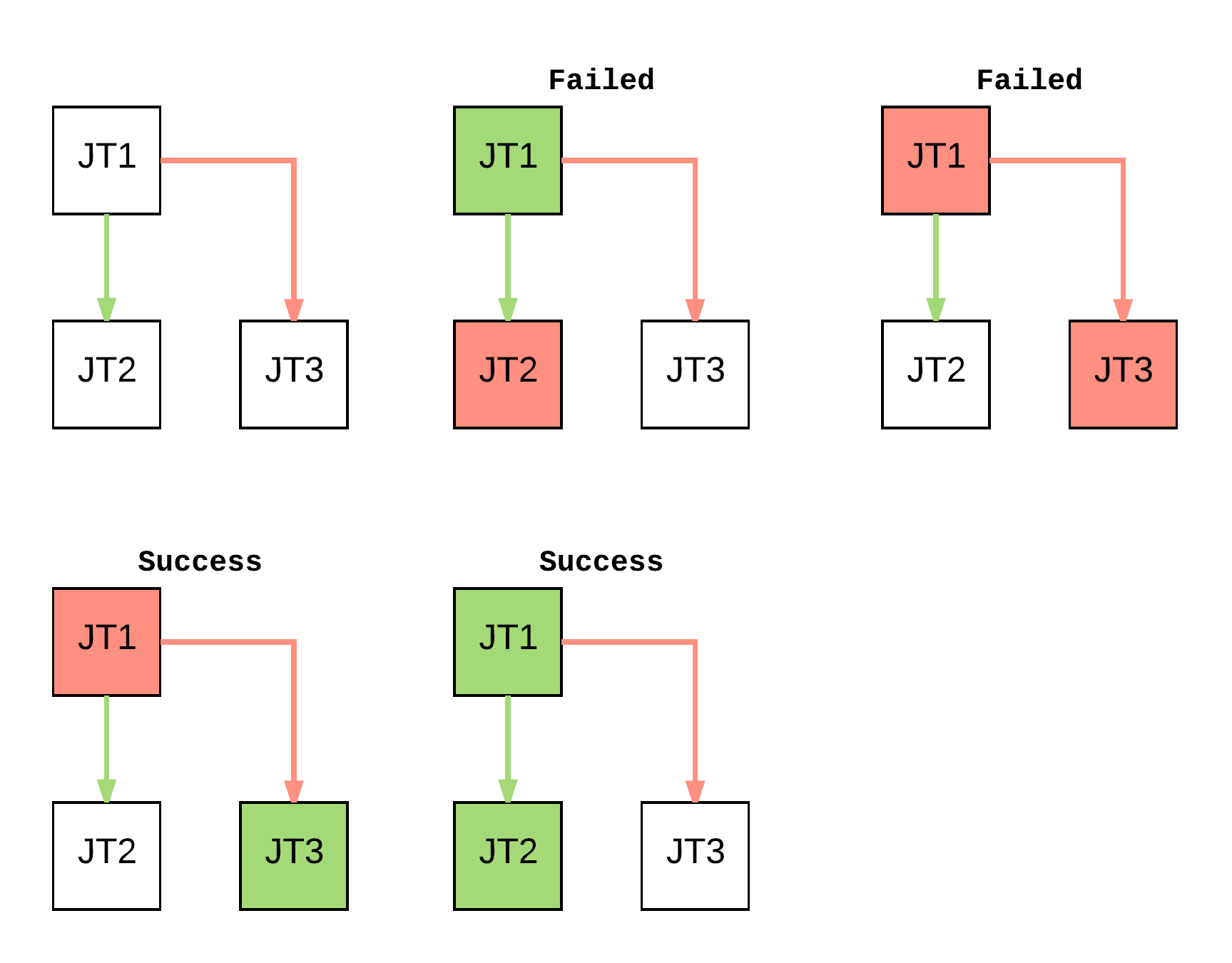
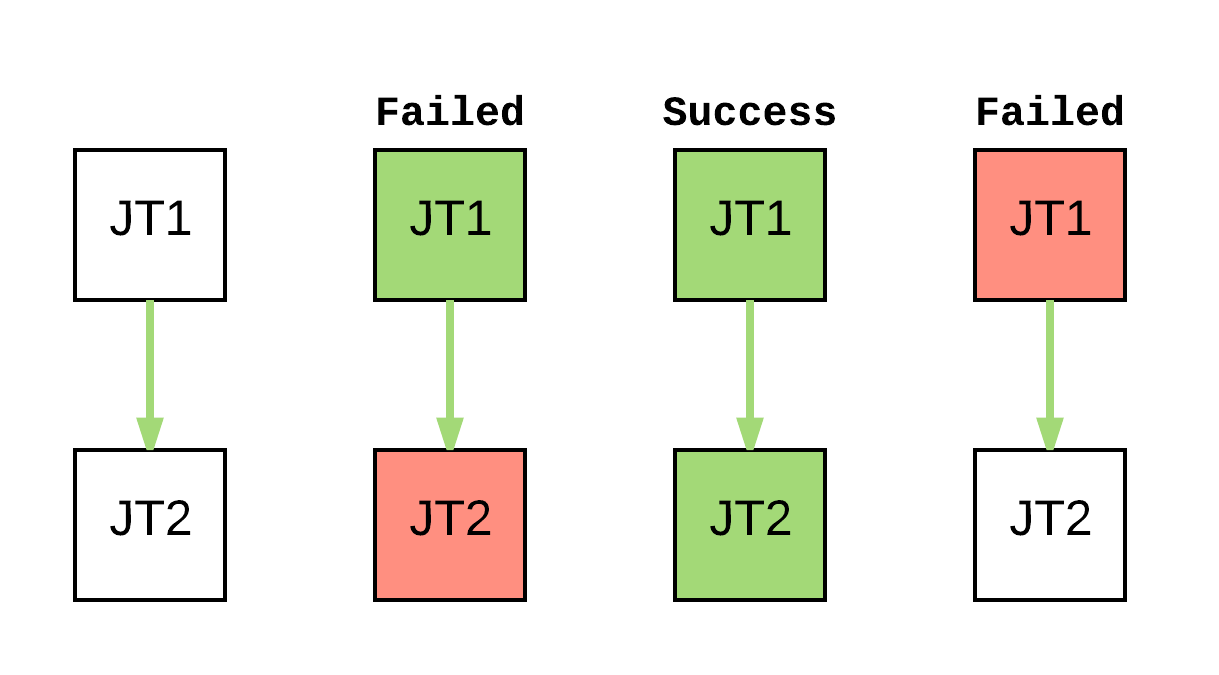
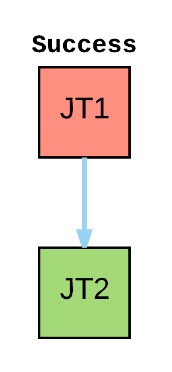
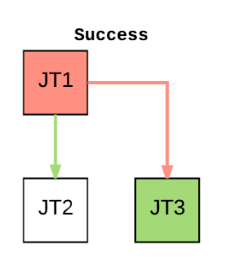
@naisanza you expect Workflow success/failure to work like the following examples?
 chrismeyersfsu
on 9 Oct 2017
chrismeyersfsu
on 9 Oct 2017
@chrismeyersfsu These two seem like false-positives. They should both also return a failed state if any part of the flow fails, otherwise you would think everything was successful
naisanza
on 9 Oct 2017
The logic you propose @naisanza is as simple as if any job in a workflow fails then the workflow should be failed?
chrismeyersfsu
on 9 Oct 2017
@naisanza @chrismeyersfsu In PR #382 I proposed a way of defining workflow job failure state:
A workflow job fails if there exist a node in the workflow which
contains at least one sub node, but no sub nodes are triggered to run
after the workflow job finished running.
 jangsutsr
on 9 Oct 2017
jangsutsr
on 9 Oct 2017
@chrismeyersfsu if something came back and said it was successful, and without looking at the run summary, how could you be certain nothing failed?
Thus, if anything failed, the workflow should at least say something about it, like either a "PARTIAL FAILURE", or "Run contained failures"
I hadn't known my workflow had issues until I troubleshooted it, and saw there was a failure, because I just saw a success and assumed everything went accordingly
The same reason if you had a simple Ansible Playbook, it would fail if there were errors. It wouldn't just run through the failures and say it was all good just because the very last command was successful.
naisanza
on 10 Oct 2017
I would note that this is documented behavior: https://docs.ansible.com/ansible-tower/latest/html/userguide/workflows.html#workflow-states
To change it, we'd need potentially multiple new states - is a workflow where all failures have been 'handled' by on-failure nodes a succes? A failure?
 wenottingham
on 10 Oct 2017
wenottingham
on 10 Oct 2017
@wenottingham a documented feature that gives you a false positive feels like a feature design to reconsider; unless we all enjoy a bit of uncertainty and chaos
naisanza
on 10 Oct 2017
The purpose of the workflow in general is to allow specifically for failure scenarios. The flexibility of being able to call other jobs based on failure gives you the user the ability to respond to the failure... either through notifications or remediation.
In this way, if you had a failure that could occur some non trivial number of times but is successfully handled by your remediation OR properly notifies you given a follow up template then the high occurrence of failure also would render the result of the workflows worthless.
Our intention was that the workflow state records that it ran and only denote failure when the workflow system fails (this occurs usually because a change to a job template renders the workflow partially unusable). This is a much more likely unplanned scenario and the one that we really need to draw attention to.
@wenottingham is correct in that we could add more states or denote unplanned failures. The simple change that we could make would be to set a failure mode if any node failed but did not have an existing error/failed (or any) handler. We could denote it as an unplanned failure and distinguish it from a workflow logic error (job template change making it incompatible with the workflow).
matburt
on 10 Oct 2017
This is now taken care of in #382
matburt
on 13 Oct 2017
Related issues
 cs35-owncloud
·
3Comments
cs35-owncloud
·
3Comments
 marshmalien
·
3Comments
marshmalien
·
3Comments
 Gui13
·
3Comments
Gui13
·
3Comments
 kakkotetsu
·
3Comments
kakkotetsu
·
3Comments
 worsco
·
3Comments
worsco
·
3Comments
Most helpful comment
This is now taken care of in #382