ISSUE TYPE
- Feature Idea
COMPONENT NAME
- API
- UI
SUMMARY
It would be great to see AWX Jobs be able to re-run a Template only on hosts that failed. This would be similar to how Ansible handles it via using "--limit @site.retry" for failed hosts. In the UI, this could be another button similar to the existing rocket ship that denotes launching the entire Job on all hosts again. This will help lower the load on the Ansible Tower nodes as it does not need to process the successful hosts again.
For brownie points, it would also be great to have this integrated into both a normal Job/Template and the newer Workflow Template. A Workflow could look like: "If Job fails, then automatically only re-run on failed hosts."
ENVIRONMENT
- AWX version: 2017-09
- Ansible version: 2.4.0
STEPS TO REPRODUCE
Run a Template. If the Job fails on some of the hosts there is no way to quickly/automatically re-run the Template only on the failed hosts.
EXPECTED RESULTS
If a Job fails, there should be an option to "Rerun on, and limit to, failed hosts."
ACTUAL RESULTS
The Template will need to be re-run on all hosts in the specified Inventory, even though some of them already had a successful run and do not need the Playbook to be run on them again.
 ekultails
ekultails
All 35 comments
+1
 hudecof
on 22 Sep 2017
hudecof
on 22 Sep 2017
+1
 senorsmile
on 24 Sep 2017
senorsmile
on 24 Sep 2017
Proposed API mechanism:
Leverage the /api/v2/jobs/N/restart/ endpoint. Accept a flag, like "failed_hosts_only": true.
We should be able to easily obtain the hosts with failed status, while also down-selecting from the hosts from the original job. /api/v2/jobs/46/job_host_summaries/?job__status=failed, QED.
The failed-hosts-relaunched job will use the --limit parameter, as this is how the .retry file feature works in Ansible core. This will simply consist of a listing of the hosts to run against.
RBAC: exact same permission required as simple relaunch, since the action is only a subset of what relaunch is.
 AlanCoding
on 6 Oct 2017
AlanCoding
on 6 Oct 2017
Endpoint is /api/v2/jobs/N/relaunch/.
The new limit would be the equivalent of ",".join(host_names) for each host_name in api/v2/jobs/N/job_host_summaries/?failed=true. It would also be possible relaunch on hosts meeting other criteria, e.g.:
api/v2/jobs/N/job_host_summaries/?changed__gt=0to relaunch against hosts that changed, to check if your playbook is idempotent.api/v2/jobs/N/job_host_summaries/?dark__gt=0to relaunch against hosts that were previously unreachable.
This approach would include hosts that were created during the previous playbook run via add_host, even though those hosts aren't in the original inventory, so we'll need to evaluate if we want that and what the side effects are.
I would propose posting {"hosts": "<status>"} to /api/v2/jobs/N/relaunch/, where <status> could be one of "all" (the current default for relaunch), "failed", "ok", "changed" or "dark" (and maybe "skipped" or "processed" if there are any conceivable use cases for those).
 cchurch
on 9 Oct 2017
cchurch
on 9 Oct 2017
^ I support this proposal.
AlanCoding
on 9 Oct 2017
@trahman73 thinking about the UI aspect...
What if the relaunch button would pop up another window if you hovered over it. That could then be the place where we offer the options of "retry on: ok, changed, failed, etc." Just wanted to throw that out there, because the decision to allow relaunch for all status types will impact your side of things.
AlanCoding
on 9 Oct 2017
@AlanCoding
 trahman73
on 10 Oct 2017
trahman73
on 10 Oct 2017
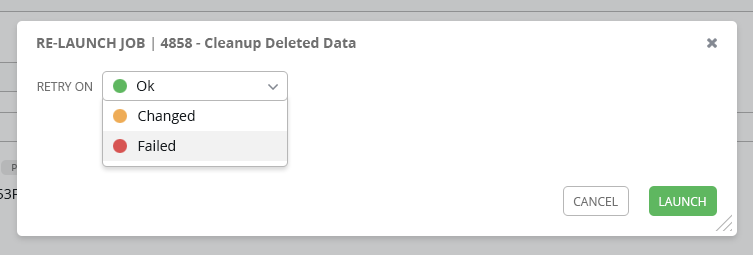
That looks good for a menu once you're retrying on a subset of hosts. I think that would be good as long as it didn't interfere with the current flow of relaunching, which you click it once, it relaunches normally, and it keeps you on the same page. I know people have complained when we broke that functionality in that past. If that is a menu you can get from a hover and click or something like that, then that looks great!
(reading "Cleanup Deleted Data") just a heads up, if that's a system job, this feature would not apply to it. AFAIK, this would only apply to relaunches of playbook runs, which excludes project/inventory updates, system jobs, workflow jobs, etc.
AlanCoding
on 10 Oct 2017
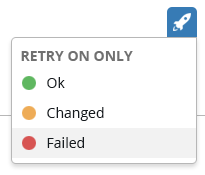
@AlanCoding Based on your feedback, we can try something like this on click or on hover.
trahman73
on 10 Oct 2017
I think that looks really good.
AlanCoding
on 10 Oct 2017
@AlanCoding @trahman73 instead of "Ok" I think we should maybe have that be "All"?
 jlmitch5
on 10 Oct 2017
jlmitch5
on 10 Oct 2017
"Ok" is a different meaning than "All" because "All" includes the failed hosts as well. "All" would just be the existing relaunch functionality.
So if clicking directly on the rocket does the "all" retry, maybe the text would be more clear if it said "RETRY ON ONLY", or something like that
AlanCoding
on 10 Oct 2017
Question for UI, ping @jlmitch5:
I am considering if it would be valuable to provide the job summary data for a GET to the /relaunch/ endpoint. If so, I'm wondering what would be the right granulaity for this.
A mock of the response, giving the number of hosts for each:
{
"passwords_needed_to_start": [],
"host_summary": {
"ok": 4,
"changed": 2,
"failed": 1,
"unreachable": 0
}
}
We could _list_ the hostnames for each, which is what we would use for --limit, but I don't actually see any use for this, and it could be burdensome for large inventories.
I'm thinking that you may want to grey out an option if the number of hosts is 0. I will also consider having the API validate for this scenario, so that we don't relaunch if the relaunch would target an empty host list.
This approach would require that you fire off a GET to the /relaunch/ endpoint in order to populate the hover-over dropdown. Does this seem like it would fit nicely into your implementation?
@trahman73 I noticed that we may want to add "unreachable" to the list. Consider the Ansible playbook summary:
ok=1 changed=0 unreachable=0 failed=0
Question: would we want integration of this feature into workflows? That is, have a workflow where you have the "failed" branch relaunch on only the failed hosts. Initial impression is that this will be very non-trivial @wenottingham
AlanCoding
on 16 Oct 2017
I think to do that reliably in workflows, you'd need something like a single workflow step with semantics of "relaunch until all succeed, max number of relaunches = N". That's a much bigger backend concept that I wouldn't create directly as part of this.
 wenottingham
on 16 Oct 2017
wenottingham
on 16 Oct 2017
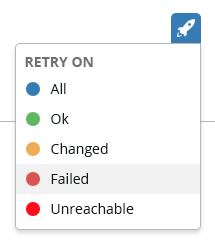
@AlanCoding
I added an ALL option as the UX for this really gets grouped into our normal relaunch flow.
trahman73
on 16 Oct 2017
Discovered a new wrinkle in this. Testing environment:
PLAY RECAP **********************************************************************************************************************************************************************
1 : ok=2 changed=0 unreachable=0 failed=1
2 : ok=3 changed=1 unreachable=0 failed=0
3 : ok=2 changed=0 unreachable=1 failed=0
4 : ok=3 changed=1 unreachable=0 failed=0
5 : ok=2 changed=0 unreachable=1 failed=0
6 : ok=2 changed=0 unreachable=0 failed=0
$ cat status/random_status.retry
1
3
5
This is the default Ansible "retry" style. You can see that unreachable hosts are not counted as failed, but they are included in the retry file.
This presents a challenge for us in terms of how to communicate this to the user.
AlanCoding
on 16 Oct 2017
Then when relaunching on 'failed', include unreachable by default? (may also need to roll changed into 'ok', in terms of host status)
wenottingham
on 17 Oct 2017
Then when relaunching on 'failed', include unreachable by default? (may also need to roll changed into 'ok', in terms of host status)
Agree with the first proposition here. That will just have to be documented, and I was going to look into using a mapped choice, so that I can apply a label and say descriptively "Retry on failed and unreachable hosts".
On the 2nd item, "changed" hosts are a subset of "ok" hosts, right?
AlanCoding
on 17 Oct 2017
That's my understanding at the host level - changed is a subset of OK, unreachable is a subset of failed.
wenottingham
on 17 Oct 2017
Unreachable is not a subset of failed because of:
3 : ok=2 changed=0 unreachable=1 failed=0
EDIT: I have discovered that JobHostSummary has a boolean "failed" field. This gives what I want, although it will give inconsistent results with the failed _count_, which is an entirely different animal. This will be a special case, but it won't be a horrible special case.
We don't want an option for "skipped" hosts, do we?
AlanCoding
on 17 Oct 2017
Don't think we want an option for skipped, because (barring someone modifying the playbook) they'd just be skipped again...
wenottingham
on 17 Oct 2017
I have created and documented a repo with instructions for running a test job that produces all the statuses under consideration here:
https://github.com/AlanCoding/tower-cli-examples/tree/master/status
Example result, when looking at the job's relaunch endpoint:
{
"passwords_needed_to_start": [],
"retry_counts": {
"failed": 12,
"all": 30,
"changed": 2,
"ok": 25,
"unreachable": 4
}
}
You can see that none of the numbers are the same. This is because of the unique situation where the play targets hosts that will ultimately run no tasks. Since even using set_fact will result in an "ok", there is no way to force this situation except through using a host pattern, which is what I did.
This also expresses the functionality of targeting the "ok" hosts, as I have it implemented now. If you run against ok hosts, you do not run against all hosts that were included in the play, you only run against hosts that run against the play, and actually ran 1 or more tasks.
I agree this is jargony, but it is a definable behavior - and has the main benefit of maintaining a consistency with the way that Ansible, itself, reports host status at the end of a playbook.
AlanCoding
on 17 Oct 2017
Link https://github.com/ansible/ansible/issues/31245
possible new status options, that could be added, if this gets in the Ansible core devel branch:
- rescue
- ignored
AlanCoding
on 18 Oct 2017
Additional notes of things to double-check.
Say that a playbook provisions a host, behave sanely when relaunching against a status that includes these hosts.
(I think we're fine here)
Case:
- you add a host name "5" to your inventory
- launch a job with limit of "1,2,3"
- use a task in your playbook
add_host: 5, and run more tasks against it - relaunch against ok hosts
block the playbook on stats event, see that the relaunch behavior is sane.
--> verify that a playbook_on_stats event exists in the POST method
Case:
a host has a comma in its name
Case:
- inside of playbook, have task
meta: clear_host_errors - have subsequent tasks that fail
then the host could have failed>0 and host will still be included in retry file, AWX behavior unclear, but this makes it difficult to claim full parity with the retry files.
Added detail: verify what condition on the job will indicate if failed hosts exist. It is believed that if job "status" field is "failed", this necessarily implies >=1 failed host exists.
AlanCoding
on 18 Oct 2017
I've tested this in the UI. Looks like it has been fully implemented.
AlanCoding
on 11 Dec 2017
Docs coverage in PR #295.
 tvo318
on 12 Jan 2018
tvo318
on 12 Jan 2018
Above you mentioned that the user relaunching the job should only require the same permissions as they did to run it. Currently trying to relaunch a job as the Normal User that first launched the job but am getting "Job was launched with prompted fields. Organization level permissions required."
Does this mean only admins are allowed to re run jobs with surveys? or is this a bug?
 mkempster22
on 28 Feb 2018
mkempster22
on 28 Feb 2018
That means that the job had fields provided on launch. Was the JT modified to change which fields prompts on launch? You can navigate to the jobs /api/v2/jobs/N/create_schedule/ endpoint and see what prompts were provided.
AlanCoding
on 28 Feb 2018
The job was just normal job template with a survey, so the user filled in the survey and ran it. Needed to rerun it again and it told them they couldn't. So is it that jobs with modified variables i.e. Survey based jobs can't be rerun like that?
mkempster22
on 28 Feb 2018
Ah, I see. Looks like we didn't carve out an exception to survey variables in that case. That would be good to do, you could file a new issue for that.
AlanCoding
on 28 Feb 2018
Ah right thanks for clarifying that. I'll raise a new issue
mkempster22
on 28 Feb 2018
Is there a magic variable name within AWX we could use to limit to failed hosts?
I'm attempting to set up two templates, the second being a clone of the first with limit = "@play.retry", then a workflow template chaining them together. I notice digging into the file system that .retry files aren't being created though.
 LukeDRussell
on 5 Sep 2018
LukeDRussell
on 5 Sep 2018
No, there's not a variable, and I'm not sure how it would work in practice, as failed hosts is inherently a thing that is tied to a job, not to a job template.
Imagine a job with prompted limits and allow_simultaneous set, where three runs are running concurrently with different limits. A "last failed for this template" that could be passed to a new run is entirely ambiguous in that context.
wenottingham
on 5 Sep 2018
Yeh that makes sense, I'm quite new to AWX.
My use case is very much the same as the original post. We're pointing AWX at a bunch of networking devices, and the management connection is not always reliable.
I'm hoping to actually generate slack notifications or log tickets when a job fails, but I would get way too many false positives due to ssh timeouts, authentication foibles and other crud that isn't really related to the hosts state.
A workflow template that runs a template 3 times with a limit to retry applied each time could be trusted a lot more.
LukeDRussell
on 5 Sep 2018
Related issues
 kakkotetsu
·
3Comments
kakkotetsu
·
3Comments
 agaffney
·
3Comments
agaffney
·
3Comments
 cs35-owncloud
·
3Comments
cs35-owncloud
·
3Comments
 icsm2017
·
4Comments
icsm2017
·
4Comments
 darkaxl
·
3Comments
darkaxl
·
3Comments