Aws-load-balancer-controller: Add the option to specify a load balancer name
is it possible to specify the ALB load balancer name via annotation from my ingress?
It would be nice to be able to control the name
 lee5i3
lee5i3
All 13 comments
Right now this can't be done, the ALB name is a function of the cluster name and a hashing of some other details. It was needed to be done for aligning the ingresses with existing load balancers at start up.
I think that we might be able to work around this now by using the resource tagging API that was announced last March: https://aws.amazon.com/blogs/aws/new-aws-resource-tagging-api/. Previously we needed to iterate over all ALBs and pull back their tags which is API heavy.
 bigkraig
on 18 Jun 2018
bigkraig
on 18 Jun 2018
Much of the necessary work for this has been completed and now it is a matter of creating the annotation.
bigkraig
on 28 Jun 2018
This would be a nice feature to have with my current setup, which is a mixture of alb-ingress-controller and ingress-nginx.
I have an alb-ingress-controller Ingress in front of a ClusterIP Service for an nginx-ingress-controller deployment. The ALB is routing to the nginx pods correctly, but in order to have route53 records created via external-dns, nginx must be deployed with a flag --publish-status-address=<alb-dns>, which currently can't be set to a fixed value, requiring a bit of pipeline code to automate the cluster creation process.
 thadamski
on 31 Jan 2019
thadamski
on 31 Jan 2019
This would be a nice feature to have with my current setup, which is a mixture of
alb-ingress-controllerandingress-nginx.I have an
alb-ingress-controllerIngress in front of a ClusterIP Service for annginx-ingress-controllerdeployment. The ALB is routing to the nginx pods correctly, but in order to have route53 records created viaexternal-dns, nginx must be deployed with a flag--publish-status-address=<alb-dns>, which currently can't be set to a fixed value, requiring a bit of pipeline code to automate the cluster creation process.
@thadamski
If i understand your problem correctly. Wouldn't it be better to have an fixed DNS name via external-dns for ALB?
I.e. You can always using nginx.example.com as entry point to your nginx, and setting --publish-status-address=nginx.example.com, and also using external-dns to map the auto-provisioned alb-dns to nginx.example.com 😄
The benefit is that your infrastructure code is reproducable instead of relies on an pre-provisioned ALB .
 M00nF1sh
on 1 Feb 2019
M00nF1sh
on 1 Feb 2019
@M00nF1sh, I think so, I never thought of that, thanks for the suggestion!
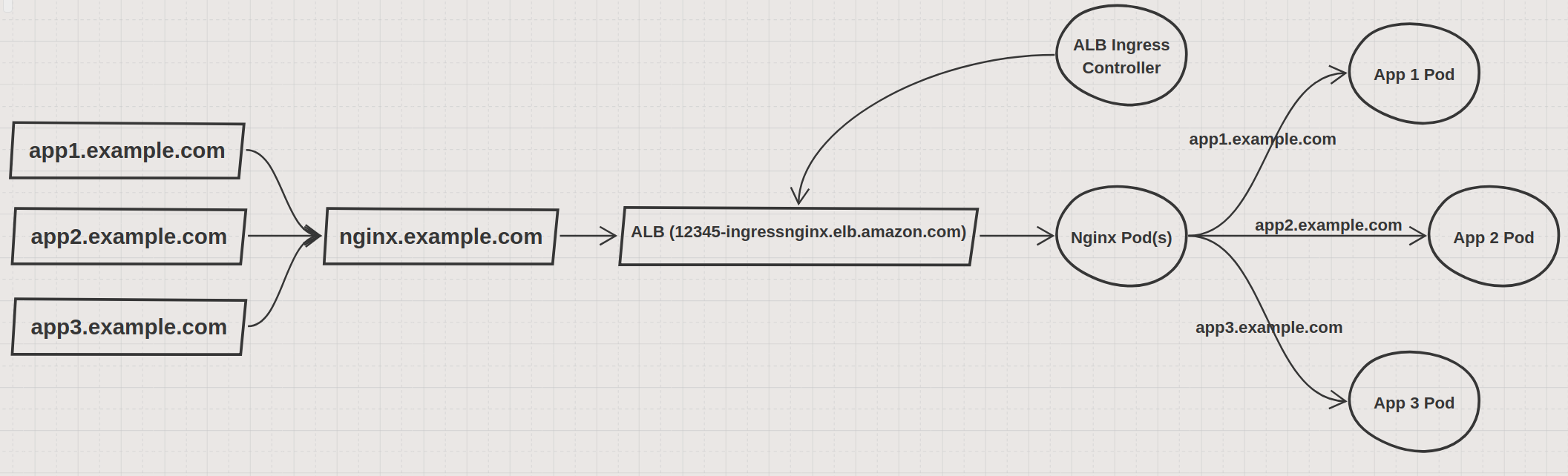
Sounds like I'd just have an extra alias hop in between my apps' route53 records and the ALB dns name, roughly how the following diagram is sketched out:
thadamski
on 1 Feb 2019
@thadamski
Yeah..the cname chain may hurts the resolve performance a little bit, but most dns resolves are cached at different layers(i'm not an dns expert so i might be wrong), so it might not matter.
BTW, what's the feature gap between ALB & nginx that make you have to keep the nginx proxy? It's a extra traffic-hop and single-point-of-failure. I'd like to know your use case and talk with ALB team to close the gap. (one known feature gap is URL rewrite :D)
another BTW, just did an nslookup www.microsoft.com, seems they are doing www.microsoft.com -> www.microsoft.com-c-3.edgekey.net -> www.microsoft.com-c-3.edgekey.net.globalredir.akadns.net -> e13678.dspb.akamaiedge.net 🤣
M00nF1sh
on 1 Feb 2019
@M00nF1sh, The ALB alone could probably suit our scenario, which I think is a bit non-standard. The nginx controller was introduced to reduce the number of AWS calls needed whenever Pods are rescheduled/upgraded.
In the example drawing above, there will be more like 500 apps, each with their own Pod, which contains three containers. The Pod has three ingress paths, each resolving to one of the three containers within a given Pod. Each one of those ingress paths results in a ALB rule pointing to a TargetGroup, so 500 Pods would result in 1500 Rules and TargetGroups. I'm sure an ALB can handle it the configuration once created, but in the event of a large WorkerNode going down, I wanted to reduce the number of AWS requests that would need to be made to reconfigure the routing to the Pod IPs.
thadamski
on 1 Feb 2019
Oh, get it 😄.
Another issue is that currently we provision 1 alb per Ingress resource. So if your apps lives in different namespace, then your solution make sense. (we'll improve this very soon by support single ALB across namespaces).
For the pods rescheduled/upgraded issue, If you are using mode:instance with NodePort, then only node changes will result in targetGroup changes. If a lot of workerNode going down, it's indeed a lot of API calls(I havn't thought of this before).
I'll talk with ALB team to see whether this is something we can improve on 😄
M00nF1sh
on 1 Feb 2019
While we're at it, it would be nice to able to specify the TargetGroup name, or for the name to be automatically set to the service name (prepended by the loadbalancer name, of course).
Right now the TG name is a string of seemingly arbitrary letters, which pollutes the AWS Console. The name is needed to convey meaning.
 TarekAS
on 8 Feb 2019
TarekAS
on 8 Feb 2019
Issues go stale after 90d of inactivity.
Mark the issue as fresh with /remove-lifecycle stale.
Stale issues rot after an additional 30d of inactivity and eventually close.
If this issue is safe to close now please do so with /close.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/lifecycle stale
 fejta-bot
on 9 May 2019
fejta-bot
on 9 May 2019
Stale issues rot after 30d of inactivity.
Mark the issue as fresh with /remove-lifecycle rotten.
Rotten issues close after an additional 30d of inactivity.
If this issue is safe to close now please do so with /close.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/lifecycle rotten
fejta-bot
on 8 Jun 2019
Rotten issues close after 30d of inactivity.
Reopen the issue with /reopen.
Mark the issue as fresh with /remove-lifecycle rotten.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/close
fejta-bot
on 8 Jul 2019
@fejta-bot: Closing this issue.
In response to this:
Rotten issues close after 30d of inactivity.
Reopen the issue with/reopen.
Mark the issue as fresh with/remove-lifecycle rotten.Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/close
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository.
 k8s-ci-robot
on 8 Jul 2019
k8s-ci-robot
on 8 Jul 2019
Related issues
 rdubya16
·
4Comments
rdubya16
·
4Comments
 gigi-at-zymergen
·
5Comments
gigi-at-zymergen
·
5Comments
 JakubJecminek
·
5Comments
JakubJecminek
·
5Comments
 mgoodness
·
5Comments
mgoodness
·
5Comments
 joseppla
·
5Comments
joseppla
·
5Comments
Most helpful comment
Much of the necessary work for this has been completed and now it is a matter of creating the annotation.