Argo-cd: App stuck in loop while deleting endpoints / services
If you are trying to resolve an environment-specific issue or have a one-off question about the edge case that does not require a feature then please consider asking a
question in argocd slack channel.
Checklist:
- [x] I've searched in the docs and FAQ for my answer: https://bit.ly/argocd-faq.
- [x] I've included steps to reproduce the bug.
- [x] I've pasted the output of
argocd version.
Describe the bug
Version: v1.6.1
Deployment not deleting as expected when employing cascade
Enters a redeploy loop.
Appears to hang when deleting services.
Requires either forced deletion of svc (ArgoCD UI)
or
kubectl -n <ns> delete service --all
At which point ArgoCD removes app from UI.
I think whats happening is:
cascade delete is stuck in a cycle deleting endpoints.
It rarely gets to delete the underlying service, since the service redeploys its endpoint to match desired state of k8s cluster.
Suspect fix would be to ignore / skip endpoint deletion and delete the underlying associated service.
To Reproduce
Install app, sync, delete app
Tested with helm chart stable prometheus-operator and harbor both showed similar issue on delete.
Expected behavior
App delete to run to completion, no unwanted artifacts to be left on cluster.
Screenshots
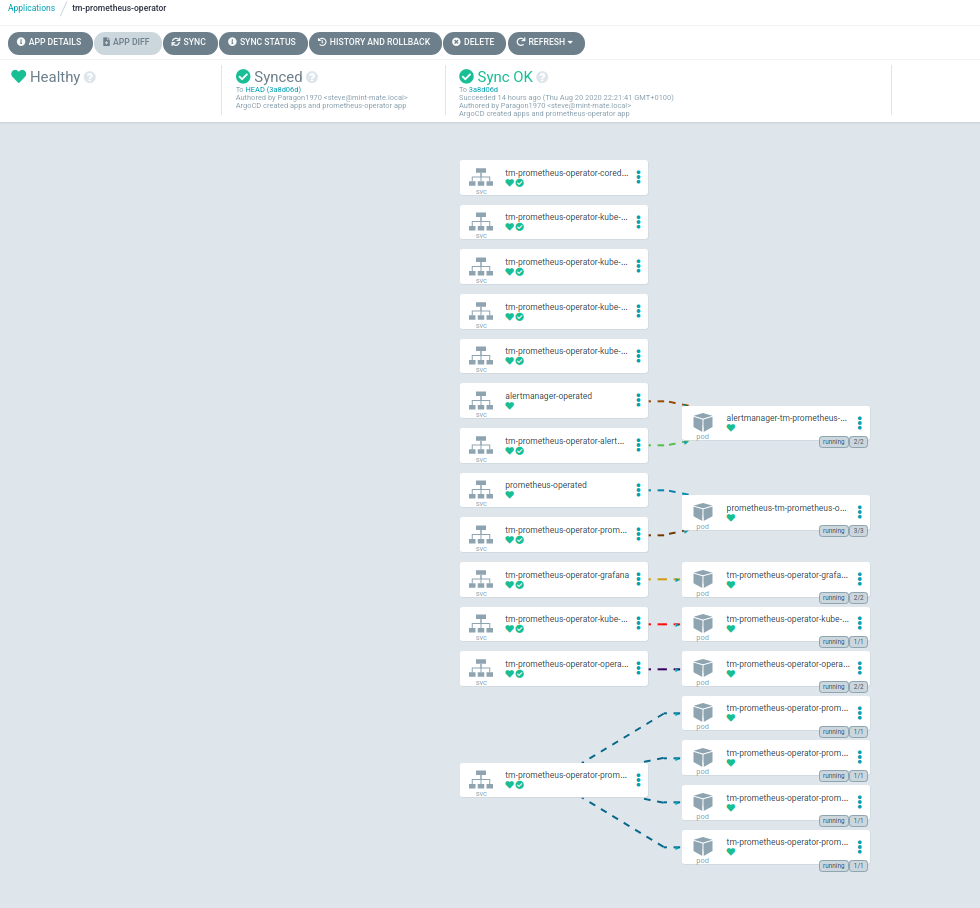
Prior to delete:
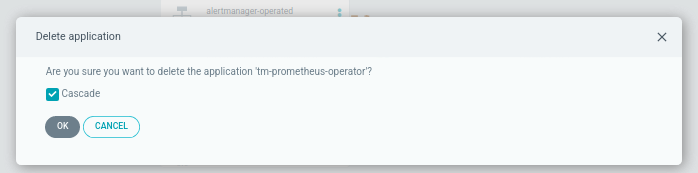
Selecting cascade delete:
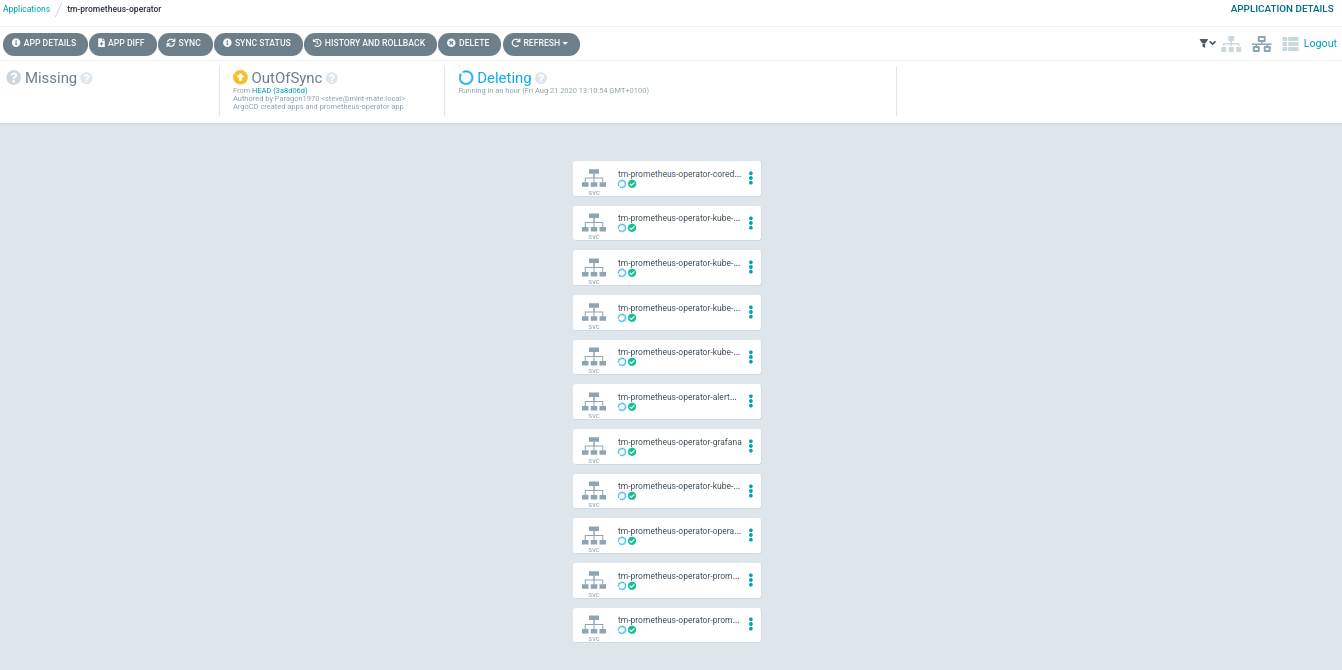
Hanging at SVC delete:
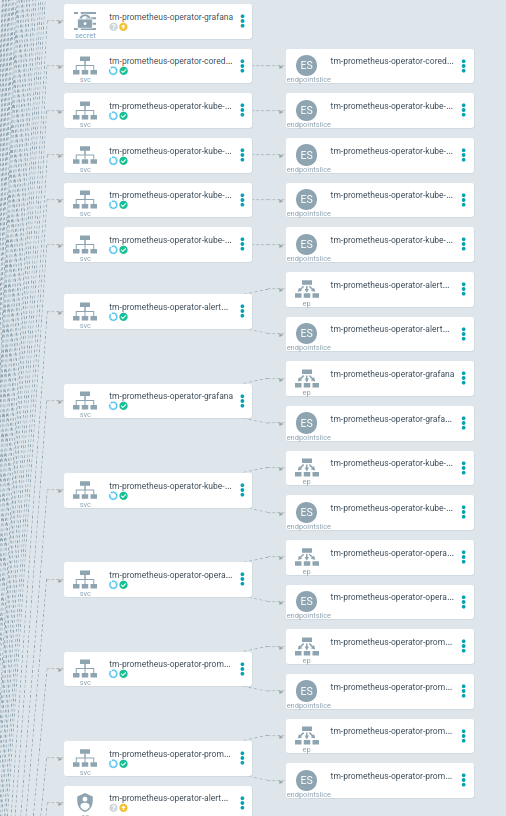
Expanded view showing redeploy of SVC endpoints (they get deleted and then redeployed since the SVC is still running.)
If applicable, add screenshots to help explain your problem.
Version
argocd: v1.6.1+159674e
BuildDate: 2020-06-19T00:39:46Z
GitCommit: 159674ee844a378fb98fe297006bf7b83a6e32d2
GitTreeState: clean
GoVersion: go1.14.1
Compiler: gc
Platform: linux/amd64
Logs
Paste any relevant application logs here.
 Paragon1970
Paragon1970
All 9 comments
Is there anything special about the structure of the resources in your application? We aren't able to reproduce this.
 jessesuen
on 21 Aug 2020
jessesuen
on 21 Aug 2020
I can reproduce it with K8S 1.18 using guestbook app from https://github.com/argoproj/argocd-example-apps
 alexmt
on 24 Aug 2020
alexmt
on 24 Aug 2020
I think this is related to https://github.com/kubernetes/kubernetes/issues/91287 . The issue is supposed to be fixed. I've upgraded minukube to v1.18.8 but still seeing the same issue.
alexmt
on 24 Aug 2020
We notice that eventually kubernetes is able to delete the endpoint successfully, but it may last for minutes. Ultimately this appears to be a kubernetes bug but somehow exacerbated somehow by the way Argo CD deletes it
jessesuen
on 24 Aug 2020
Reproduced by installing into fresh cluster within AWS and still seeing same issue though with additional deletion problems.
Firstly it hangs on deletion svc's and endpoints but once these are manually deleted it hangs deleting rolebindings, clusterrolebinding and roles.
Tested with prometheus-operator 9.1.0 deployment cloned from helm stable https://kubernetes-charts.storage.googleapis.com repo.
K8s version 1.18.2
Applying 'force' removes the components but this can only be applied individually, not at the top level app which only allows for an checked / unchecked cascade option.
Paragon1970
on 25 Aug 2020
The stuck RBAC resources are actually a bug in the K8s Garbage Collector with K8s versions <= 1.18.4 when using foreground deletion. Argo CD usese foreground deletion for normal deletions, and background deletion when "force" delete is used. I'm unsure whether we should work around this.
Refer to https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG/CHANGELOG-1.18.md#changelog-since-v1183 and https://github.com/kubernetes/kubernetes/pull/90534
 jannfis
on 25 Aug 2020
jannfis
on 25 Aug 2020
Thank you,
I just checked the original cluster of which this bug was initially filed (its running locally under Proxmox) and realized its version is 1.18.4 which would explain why it never experienced the RBAC resource issue.
Paragon1970
on 25 Aug 2020
Found corresponding Kubernetes issue: https://github.com/kubernetes/kubernetes/issues/90512 . The bug was fixed two days ago and will be cherry-picked into 1.18.
alexmt
on 28 Aug 2020
There is not much we can do on Argo CD side. Kubernetes v1.18.9 should resolve it when it is available. I think we can close it.
alexmt
on 28 Aug 2020
Related issues
 ksaito1125
·
3Comments
ksaito1125
·
3Comments
 estahn
·
3Comments
estahn
·
3Comments
 jutley
·
3Comments
jutley
·
3Comments
 clintberry
·
3Comments
clintberry
·
3Comments
 KarstenSiemer
·
3Comments
KarstenSiemer
·
3Comments
Most helpful comment
There is not much we can do on Argo CD side. Kubernetes v1.18.9 should resolve it when it is available. I think we can close it.