File upload currently involves
- read a file
- push it off to a 'csv2query' function
- loop over the new query object/structure
- INSERT every row
That worked well enough in ACF, but for reasons I don't fully understand Lucee is very slow, and uses a lot of memory, in the csv2query step.
INSERT is fairly slow as well, but I don't think it's a limitation on the kinds of things you'd want to open in Excel.
My old home-grown CSVifier scripts are a bit faster but still resource-hungry, and do not handle imperfect CSV very well; I suspect they'd be frustrating for users without being a significantly better solution.
I haven't found a CFML replacement that both performs well and does a good job of handling CSV. There are some python-and-such libraries, I don't know how they work and they wouldn't be significantly easier to implement than the below.
Postgres (unlike Oracle) is very good with text file handling, but those tools aren't directly accessible to the front end.
I've got the seed of a fairly complicated set of scripts that exploit PG's native file handling. I suspect it would take a week or so to get them fully/safely linked via the UI. This would add more complexity than I'd like to the environment, and there's some chance it will just fail. It would almost certainly be more fragile than the CFML tools - eg, PG doesn't seem to deal with linebreaks in data at all, where the CFML can push them through and then throw row-specific errors.
For scale, https://github.com/ArctosDB/arctos/issues/2719 is 1363 bulkloader records. The csv2query SOMETIMES completes in the minute it's given, and occasionally plugs up the session (and given enough time is probably capable of taking the front end down). My scripts take just over 2 seconds to prepare the file and upload code, and then the upload scripts complete in a few milliseconds.
@ArctosDB/arctos-working-group-officers please advise.
 dustymc
dustymc
All 54 comments
My scripts take just over 2 seconds to prepare the file and upload code, and then the upload scripts complete in a few milliseconds.
While I enjoy instant gratification as much as the next user, is there some sort of "go get a cup of coffee, you'll get a notification when this is done" option that could work?
 Jegelewicz
on 2 Jun 2020
Jegelewicz
on 2 Jun 2020
some sort of "go get a cup of coffee, you'll get a notification when this is done" option
Probably not one without limitations. If I'm using Lucee in some capacity this seems to necessarily happen in memory, and eventually that gets used up and some sort of strange thing happens. I don't know precisely what those limitations are or how efficiently we could avoid them, but they do exist. (PG happily munched several billion rows over ~20 hours last week - it doesn't seem to have limitations other than disk space, and I can access several petabytes of that.)
If that's acceptable from user's standpoint I think it's worth exploring; it would be a much simpler and more integrated solution than needing to install PG on the webserver and then doing scary things to the file system, which is essentially what my PG solution requires.
The most expensive thing this applies to is the specimen bulkloader, which can be very wide (which demands memory). What's an acceptable number of rows/records for a "this is too big, upload smaller chunks or talk to a DBA" message?
dustymc
on 2 Jun 2020
What's an acceptable number of rows/records for a "this is too big, upload smaller chunks or talk to a DBA" message?
Well, I have been able to load at least 2500 records at a go previously. Not sure that it matters though. What matters is how much of your time is going to be spent doing something like this? I'd rather have you doing other things, things that I can't do. The bummer of the deal is that many of us depend upon the response from the bulkloader to figure out where we have data issues. I have loaded and reloaded to the bulkloader four or five times before I finally got it right. Pretty sure you don't want to be dealing with that!
I'd rather wait a day for my file to upload (knowing in advance that's how it works) than pester you constantly with "please upload" requests.
In any case, I am not really sure I know what you suggest we do here.
Jegelewicz
on 2 Jun 2020
I definitely don't hesitate to just throw whatever I have at the bulkloader and then fix the errors - I wrote all that fancy code, I'm gonna use it!
2.5K rows seems reasonable via CFML. 25K probably isn't (but is definitely fine for PG). "Functional requirements" would better let me know where to start.
Yes I don't know how to prioritize this either.
dustymc
on 2 Jun 2020
I could use a translation for what my next move is
 lin-fred
on 3 Jun 2020
lin-fred
on 3 Jun 2020
Can we have a translation/summary of the issue here? Is the question how
many records should be allowed to be bulkloaded at time? Are we telling
Dusty whether he should dedicate a bunch of time to making this process
faster and more streamlined? What does NMMNHS need to move forward?
On Tue, Jun 2, 2020 at 4:44 PM Lindsey NMMNHS notifications@github.com
wrote:
- [EXTERNAL]*
I could use a translation for what my next move is
—
You are receiving this because you are on a team that was mentioned.
Reply to this email directly, view it on GitHub
https://github.com/ArctosDB/arctos/issues/2720#issuecomment-637846194,
or unsubscribe
https://github.com/notifications/unsubscribe-auth/ADQ7JBAQPZUXHESYTJAN2RTRUV6EHANCNFSM4NQ5MVJA
.
 campmlc
on 3 Jun 2020
campmlc
on 3 Jun 2020
Summary of current situation: Only relatively small CSV files can be uploaded.
Summary of this Issue: Do we need to change that? If so, how drastically and what's the priority?
dustymc
on 3 Jun 2020
Well I have ~7300 parts that need to load, and 415 mammals for the bulkloader. What's considered relatively small? 100? or 2k?
lin-fred
on 3 Jun 2020
I bulkloaded 30,000 records 1,000 at a time. I would think 5,000 at a time
would be more reasonable.
On Tue, Jun 2, 2020, 5:12 PM Lindsey NMMNHS notifications@github.com
wrote:
- [EXTERNAL]*
Well I have ~7300 parts that need to load, and 415 mammals for the
bulkloader. What's considered relatively small? 100? or 2k?—
You are receiving this because you are on a team that was mentioned.
Reply to this email directly, view it on GitHub
https://github.com/ArctosDB/arctos/issues/2720#issuecomment-637854970,
or unsubscribe
https://github.com/notifications/unsubscribe-auth/ADQ7JBBY7DMJMTWU5V6KCOTRUWBO7ANCNFSM4NQ5MVJA
.
campmlc
on 3 Jun 2020
And I agree with high priority if all other critical post migration issues
have been resolved. Any other issues holding people up?
On Tue, Jun 2, 2020, 5:20 PM Mariel Campbell campbell@carachupa.org wrote:
I bulkloaded 30,000 records 1,000 at a time. I would think 5,000 at a time
would be more reasonable.On Tue, Jun 2, 2020, 5:12 PM Lindsey NMMNHS notifications@github.com
wrote:
- [EXTERNAL]*
Well I have ~7300 parts that need to load, and 415 mammals for the
bulkloader. What's considered relatively small? 100? or 2k?—
You are receiving this because you are on a team that was mentioned.
Reply to this email directly, view it on GitHub
https://github.com/ArctosDB/arctos/issues/2720#issuecomment-637854970,
or unsubscribe
https://github.com/notifications/unsubscribe-auth/ADQ7JBBY7DMJMTWU5V6KCOTRUWBO7ANCNFSM4NQ5MVJA
.
campmlc
on 3 Jun 2020
What's considered relatively small?
I have no idea; it's probably more to do with bytes than rows.
I bulkloaded 30,000 records 1,000 at a time.
Oh my, please don't do that!
@lin-fred the fewer files you can smoosh your data into the happier I'll be, then send me CSV and let me know where you want it.
dustymc
on 3 Jun 2020
I bulkloaded 30,000 records 1,000 at a time.Oh my, please don't do that!
Sometimes it makes sense that way - especially when prepping data in some kind of sensible (to humans) groups....
Jegelewicz
on 3 Jun 2020
And even then each load took multiple loads to fix various data problems.I
can't imagine how much harder to fix more than a few thousand at a time.
On Tue, Jun 2, 2020, 5:56 PM Teresa Mayfield-Meyer notifications@github.com
wrote:
- [EXTERNAL]*
I bulkloaded 30,000 records 1,000 at a time.
Oh my, please don't do that!
Sometimes it makes sense that way - especially when prepping data in some
kind of sensible (to humans) groups....—
You are receiving this because you are on a team that was mentioned.
Reply to this email directly, view it on GitHub
https://github.com/ArctosDB/arctos/issues/2720#issuecomment-637873556,
or unsubscribe
https://github.com/notifications/unsubscribe-auth/ADQ7JBEHOMGSCPFDMVJJSIDRUWGQZANCNFSM4NQ5MVJA
.
campmlc
on 3 Jun 2020
@dustymc I have my master file that has all 7k records, you need it emailed to you because its a csv right?
lin-fred
on 3 Jun 2020
You are certainly welcome to upload however you want, but please don't feel compelled to do so. We'd have helped when we had to force-feed Oracle's evil little file handler, we're thrilled to do so now that we have better tools.
"can't imagine how much harder to fix more than a few thousand at a time" is probably also tool-dependent. The way I do cleanup, the number of rows is almost irrelevant - of course it takes more time to reconcile a million agents-or-whatever than one, but I only find unique values one, map them once, and repatriate them once.
"Map them once" is the key part of that - I map MLC --> @campmlc ONCE, not once for each "segment" in which it occurs.
Much of that's now available in Arctos (as pre-bulkloader, which I believe still needs rebuild for PG).
@lin-fred please just zip and attach here
dustymc
on 3 Jun 2020
I generally do larger batches, I'd be open to large bulkloading batches, but would also be ok with something like a 5k limit
Heres the file @dustymc need for bulkloading parts
Shell_PartsTable_bulkload.zip
lin-fred
on 3 Jun 2020
That failed with ERROR: null value in column "lot_count" violates not-null constraint
dustymc
on 3 Jun 2020
We should definitely prioritize this, given new collections
pre-bulkloader, which I believe still needs rebuild for PG
On Tue, Jun 2, 2020, 7:27 PM Lindsey NMMNHS notifications@github.com
wrote:
- [EXTERNAL]*
I generally do larger batches, I'd be open to large bulkloading batches,
but would also be ok with something like a 5k limitHeres the file @dustymc https://github.com/dustymc need for bulkloading
parts
Shell_PartsTable_bulkload.zip
https://github.com/ArctosDB/arctos/files/4720495/Shell_PartsTable_bulkload.zip—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/ArctosDB/arctos/issues/2720#issuecomment-637899737,
or unsubscribe
https://github.com/notifications/unsubscribe-auth/ADQ7JBAHYYMUSM5ROP7JTX3RUWRJRANCNFSM4NQ5MVJA
.
campmlc
on 3 Jun 2020
@dustymc should be fixed
Shell_PartsTable_bulkload.zip
lin-fred
on 3 Jun 2020
ERROR: null value in column "lot_count" violates not-null constraint
dustymc
on 3 Jun 2020
@dustymc third time is the charm?
Shell_PartsTable_bulkload.zip
lin-fred
on 3 Jun 2020
COPY 7150
should be there
dustymc
on 3 Jun 2020
What do you mean?
edit: I'm just going to upload them in smaller chunks since there seem to be some catalog problems
lin-fred
on 3 Jun 2020
@dustymc This one timed out when trying to upload to https://arctos.database.museum/tools/BulkloadParts.cfm
It has 1,806 parts
Jegelewicz
on 4 Jun 2020
COPY 1806
dustymc
on 4 Jun 2020
Is this because stuff is still loading?
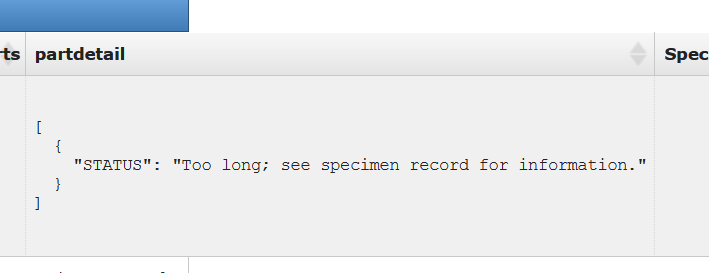
from https://arctos.database.museum/SpecimenResults.cfm?catnum=25608&guid_prefix=NMMNH%3APaleo
specimen record looks like this

Jegelewicz
on 4 Jun 2020
No that's Oracle weird meets postgres weird. I'll get converted to actual JSON without length limitations or wonky concat-null-and-die issues at some point.
dustymc
on 4 Jun 2020
@dustymc the records are back in, can you re-try https://github.com/ArctosDB/arctos/issues/2720#issuecomment-638521039 ?
Thanks!
Jegelewicz
on 7 Jun 2020
Also, Here is a large set of specimen records. Let's see if these will bulkload.
Specimen Records 3000-5399.zip
Jegelewicz
on 8 Jun 2020
@Jegelewicz are the parts still in the parts loader?
large set of specimen records.
COPY 15123
dustymc
on 8 Jun 2020
Not that I can see, but I was going on your word in https://github.com/ArctosDB/arctos/issues/2737#issuecomment-638945031
Jegelewicz
on 8 Jun 2020
Oh - yea that's an unexpected twist on using COPY.
arctosprod@arctos>> select username,guid_prefix,count(*) from cf_temp_parts group by username,guid_prefix;
username | guid_prefix | count
--------------+-------------+-------
DLM | NMMNH:Paleo | 193
arctosprod | NMMNH:Paleo | 1806
ACDOLL | | 1
ROBSON | UMNH:Mamm | 58
AEROCHILD | UTEP:HerpOS | 59
arctosprod | NMMNH:Inv | 7150
SARA | | 2
CFILIPEK | JSNM:Paleo | 11
FSKBH1 | UAM:Fish | 90
DIANNAKREJSA | ASNHC:Mamm | 1
(10 rows)
Time: 10.555 ms
arctosprod@arctos>> update cf_temp_parts set username='jegelewicz' where username='arctosprod';
UPDATE 8956
There now?
dustymc
on 8 Jun 2020
@lin-fred those NMMNH:Inv parts are yours!
Jegelewicz
on 9 Jun 2020
What's going on?
lin-fred
on 9 Jun 2020
I think you will be able to see these in the part bulkload tool and approve them to load....
Jegelewicz
on 9 Jun 2020
Am I looking in the right area?
Also,
https://github.com/ArctosDB/arctos/issues/2720#issuecomment-638286806
I ended up loading them myself because I didn't know what COPY meant, and there was a catalog issue I needed to deal with. They can be deleted from the parts bulkloader? Although I can't see them
edit: @Jegelewicz can delete the parts that were uploaded for NMMNHS Inv
lin-fred
on 9 Jun 2020
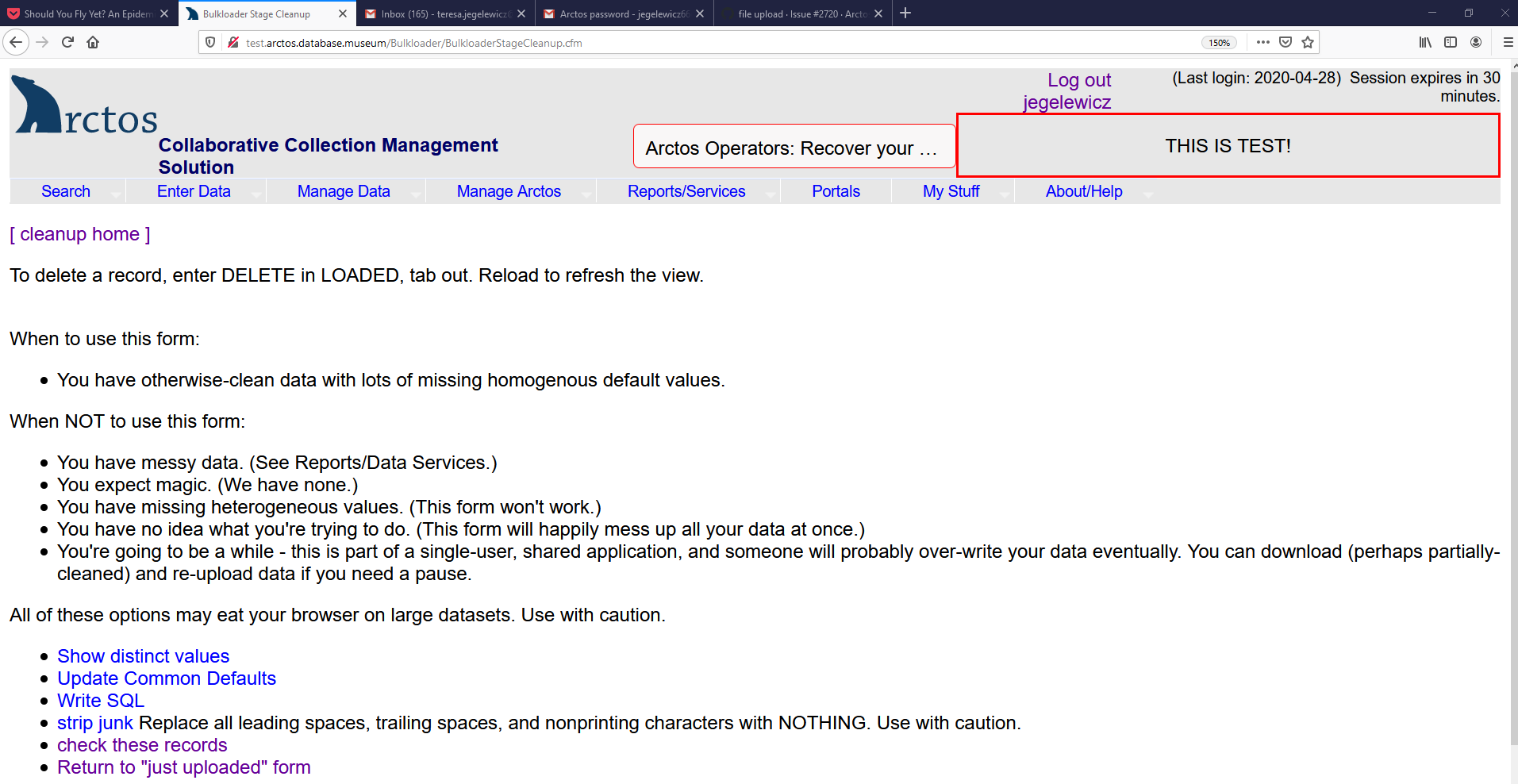
I've got a solution patched in to test, please try it out.
Note that test will only accept fairly small files - don't try to stress-test anything, it won't work, but it would be very useful if a few people with varying levels of access would try uploading CSV in several places.
dustymc
on 9 Jun 2020
@dustymc can you get rid of all the stuff in the parts bulkload tool that is for NMMNH:Inv? Lindsey already loaded them in small batches, so they are dupes.
Jegelewicz
on 10 Jun 2020
Please test this ASAP - I need to push this to production before I can move on, it needs tested first.
dustymc
on 10 Jun 2020
@Jegelewicz deleted, here they are just in case
arctosprod@arctos>> create table temp_cache.NMMNHinvpts as select * from cf_temp_parts where guid_prefix='NMMNH:Inv';
SELECT 7150
In test when I try to fix/view with Arctos Tools
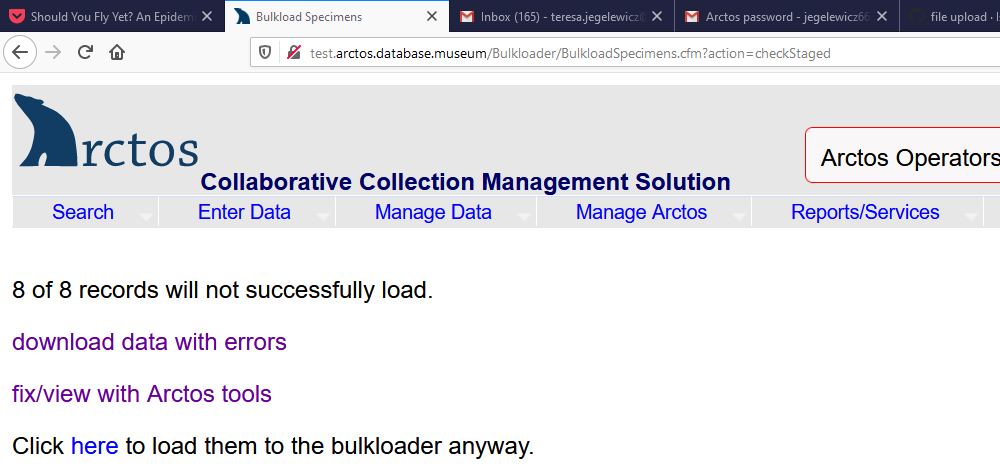
I get this
Jegelewicz
on 10 Jun 2020
Attempted a part bulkload with 2,487 rows. When I tried uploading the file I get
,
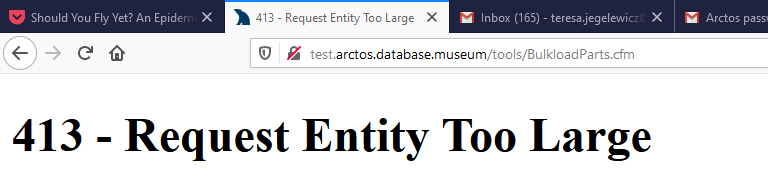
Jegelewicz
on 10 Jun 2020
Tried again with #rows = 1,390, same thing.
Tried again with 779, same.
Tried again with 22, results:
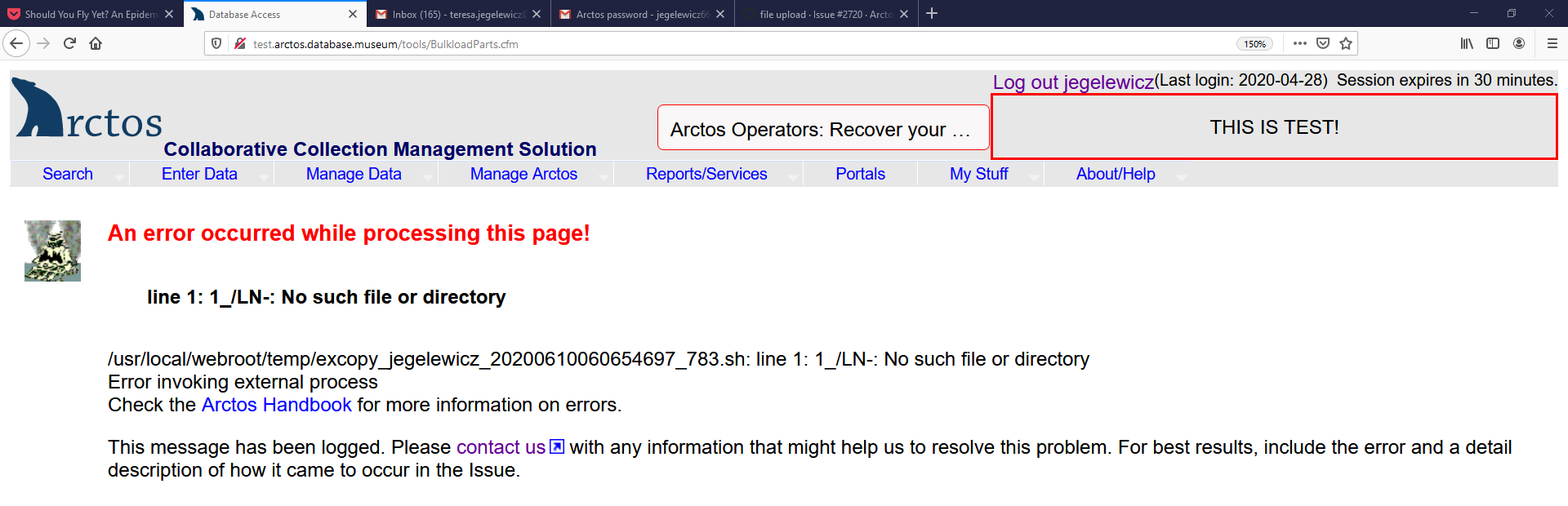
Jegelewicz
on 10 Jun 2020
Attempted to upload 10 records to the main bulkloader. Got
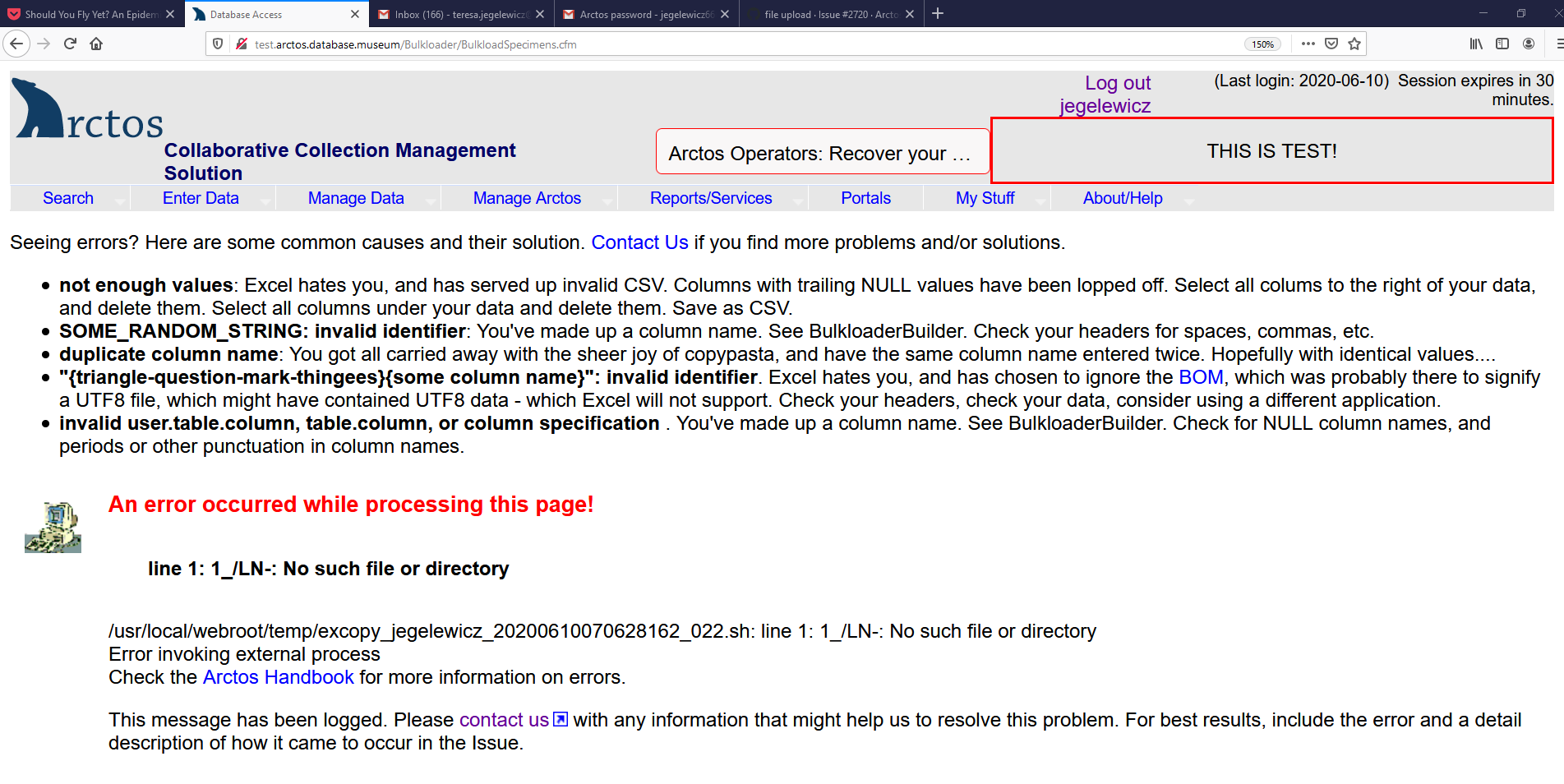
Jegelewicz
on 10 Jun 2020
@dustymc 85 of the 15K+ records you loaded for me have problems. I am afraid to try to download and lose info. Any way you can get the 85 out and send them to me so I can fix those and re-load them, but leave the rest there so I can load them?
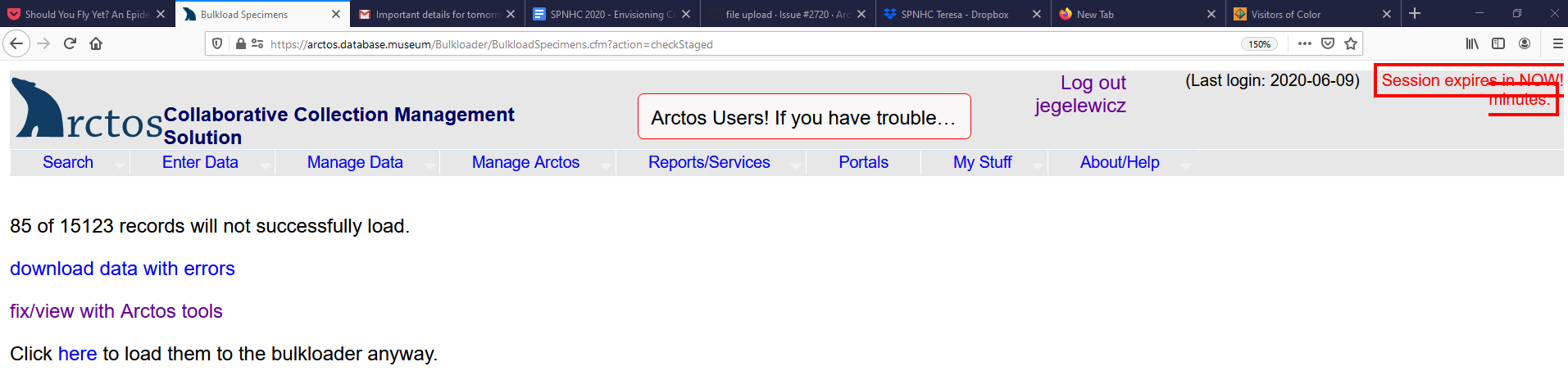
Thanks!
Jegelewicz
on 10 Jun 2020
fix/view with Arctos Tools
https://github.com/ArctosDB/arctos/issues/2727
2,487 r
don't try to stress-test anything, it won't work
10
Thanks! Try again.
85
dustymc
on 10 Jun 2020
I went to test again, but thought I should see if the 85 records were already there. Went to Browse and Edit, Datatables and got this:
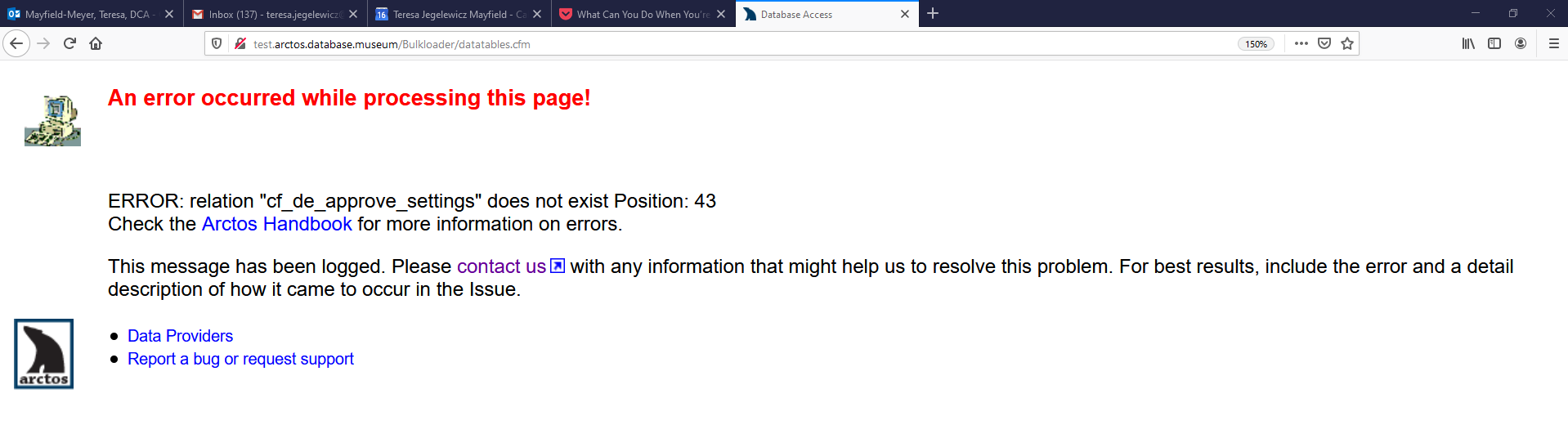
Jegelewicz
on 16 Jun 2020
Datatables isn't in test; I need a new instance of PG and a recovery to make that happen.
dustymc
on 16 Jun 2020
Bulk loading attributes is still showing that no data is being uploaded to process into Arctos.
 awilkins007
on 24 Jun 2020
awilkins007
on 24 Jun 2020
@dustymc
Jegelewicz
on 24 Jun 2020
Data?
dustymc
on 24 Jun 2020
@awilkins007 can you zip up your file and put it here?
Jegelewicz
on 24 Jun 2020
Here's the file for you. The date field will need to reset to the correct formatting but other than that it should be good to go.
awilkins007
on 24 Jun 2020
Thanks, it'll be fixed in the next release, probably tonight
dustymc
on 24 Jun 2020
Related issues
Jegelewicz
·
5Comments
 AJLinn
·
4Comments
dustymc
·
3Comments
dustymc
·
4Comments
dustymc
·
4Comments
AJLinn
·
4Comments
dustymc
·
3Comments
dustymc
·
4Comments
dustymc
·
4Comments