We use JSON to carry structured data as strings in various places. JSON is a verbose format. Things generally get weird when Oracle VARCHAR datatype is exceeded; SOMETHING finds a way to somehow fail when passed a CLOB instead of a string.
This is particularly problematic when there's some relationship depth involved; for example the "JSON locality" column in specimenresults may contain many "place-time objects" each containing many geology and/or event attribute determinations.
It's possible/correct to reduce the size (number of characters) of JSON data by treating values as arrays...
{
"thing": ["a", "b", "c"]
}
but that's "non-standard" and not very human readable. I think we should probably stick to the verbose/"normal" format....
[
{"thing":"a"},
{"thing":"b"},
{"thing":"c"},
]
... as, among other things, these data are used to visualize complex object associations in a simple tabular format.
Much of Arctos data tends to be NULL, so we could save some 'bandwidth' by not including unused "fields" but that is also "non-standard" and unnecessarily difficult to write code to; this is my last choice, by a very wide margin.
For collecting event attributes, I've used short key names. They're fairly cryptic, but I think the value (when there is one) makes it fairly easy to figure out what's going on.
Long-format example:
UAM@ARCTOS> select getCollEvtAttrAsJson(11267580) from dual;
[
{
"EVENT_ATTRIBUTE_TYPE":"fake cat too",
"EVENT_ATTRIBUTE_VALUE":"common",
"EVENT_ATTRIBUTE_UNITS":"",
"EVENT_ATTRIBUTE_REMARK":"",
"EVENT_ATTRIBUTE_METHOD":"",
"EVENT_ATTRIBUTE_DATE":"",
"EVENT_ATTRIBUTE_DETERMINER":""
}
]
Short-format of the same data:
select getCollEvtAttrAsJson_abbr(11267580) from dual;
[
{
"TYP":"fake cat too",
"VAL":"common",
"U":"",
"RMK":"",
"MTH":"",
"D":"",
"DTR":""
}
]
The longer format just fails with more data.
select getCollEvtAttrAsJson(11325805) from dual;
[ ERROR CREATING JSON ]
The abbreviated keys work:
select getCollEvtAttrAsJson_abbr(11325805) from dual;
[
{
"TYP":"air temperature",
"VAL":"88888",
"U":"kelvin",
"RMK":"qw\"otz",
"MTH":"m'ethod",
"D":"Bobby Brown",
"DTR":"Bobby Brown"
},
{
"TYP":"air temperature",
"VAL":"-5",
"U":"celsius",
"RMK":"this is so fake",
"MTH":"fake",
"D":"Dusty L. McDonald",
"DTR":"Dusty L. McDonald"
},
{
"TYP":"electrical conductivity",
"VAL":"6",
"U":"S/m",
"RMK":"",
"MTH":"",
"D":"",
"DTR":""
},
{
"TYP":"fake cat too",
"VAL":"common",
"U":"",
"RMK":"",
"MTH":"",
"D":"",
"DTR":""
},
{
"TYP":"fake cat too",
"VAL":"rare",
"U":"",
"RMK":"",
"MTH":"",
"D":"",
"DTR":""
},
{
"TYP":"fake cat too",
"VAL":"rare",
"U":"",
"RMK":"",
"MTH":"",
"D":"",
"DTR":""
},
{
"TYP":"fake cattoo",
"VAL":"uncommon",
"U":"",
"RMK":"",
"MTH":"",
"D":"",
"DTR":""
},
{
"TYP":"fake categorical",
"VAL":"abandoned loan",
"U":"",
"RMK":"",
"MTH":"",
"D":"",
"DTR":""
},
{
"TYP":"fake categorical",
"VAL":"repository agreement",
"U":"",
"RMK":"",
"MTH":"",
"D":"",
"DTR":""
},
{
"TYP":"fake string",
"VAL":"boogity too",
"U":"",
"RMK":"",
"MTH":"boogity",
"D":"",
"DTR":""
},
{
"TYP":"fake string",
"VAL":"this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long",
"U":"",
"RMK":"",
"MTH":"",
"D":"",
"DTR":""
},
{
"TYP":"fake string",
"VAL":"this is long toothis is long toothis is long toothis is long toothis is long toothis is long toothis is long toothis is long to othis is long toothis is long toothis is long toothis is long toothis is long toothis is long too",
"U":"",
"RMK":"",
"MTH":"",
"D":"",
"DTR":""
},
{
"TYP":"fake string",
"VAL":"this was just added",
"U":"",
"RMK":"",
"MTH":"",
"D":"",
"DTR":""
},
{
"TYP":"water temperature",
"VAL":"water was very cold",
"U":"",
"RMK":"",
"MTH":"",
"D":"",
"DTR":""
}
]
Oracle12 would somewhat help by moving the length of varchar from 4K to 32K. Postgres has no defined limits and would make this almost completely irrelevant.
I tentatively propose we standardize around using shortened keys in JSON data. Better ideas?
 dustymc
dustymc
All 16 comments
What are the cons of using the shortened keys? Who would care if we are
using something non-standard? Can we just document it?
This would be a temporary fix if we move to Postgres?
On Tue, Jun 25, 2019 at 11:17 AM dustymc notifications@github.com wrote:
We use JSON to carry structured data as strings in various places. JSON is
a verbose format. Things generally get weird when Oracle VARCHAR datatype
is exceeded; SOMETHING finds a way to somehow fail when passed a CLOB
instead of a string.This is particularly problematic when there's some relationship depth
involved; for example the "JSON locality" column in specimenresults may
contain many "place-time objects" each containing many geology and/or event
attribute determinations.It's possible/correct to reduce the size (number of characters) of JSON
data by treating values as arrays...{
"thing": ["a", "b", "c"]
}but that's "non-standard" and not very human readable. I think we should
probably stick to the verbose/"normal" format....[
{"thing":"a"},
{"thing":"b"},
{"thing":"c"},
]... as, among other things, these data are used to visualize complex
object associations in a simple tabular format.Much of Arctos data tends to be NULL, so we could save some 'bandwidth' by
not including unused "fields" but that is also "non-standard" and
unnecessarily difficult to write code to; this is my last choice, by a very
wide margin.For collecting event attributes, I've used short key names. They're fairly
cryptic, but I think the value (when there is one) makes it fairly easy to
figure out what's going on.Long-format example:
UAM@ARCTOS> select getCollEvtAttrAsJson(11267580) from dual;
[
{
"EVENT_ATTRIBUTE_TYPE":"fake cat too",
"EVENT_ATTRIBUTE_VALUE":"common",
"EVENT_ATTRIBUTE_UNITS":"",
"EVENT_ATTRIBUTE_REMARK":"",
"EVENT_ATTRIBUTE_METHOD":"",
"EVENT_ATTRIBUTE_DATE":"",
"EVENT_ATTRIBUTE_DETERMINER":""
}
]Short-format of the same data:
select getCollEvtAttrAsJson_abbr(11267580) from dual;
[
{
"TYP":"fake cat too",
"VAL":"common",
"U":"",
"RMK":"",
"MTH":"",
"D":"",
"DTR":""
}
]The longer format just fails with more data.
select getCollEvtAttrAsJson(11325805) from dual;
[ ERROR CREATING JSON ]The abbreviated keys work:
select getCollEvtAttrAsJson_abbr(11325805) from dual;
[
{
"TYP":"air temperature",
"VAL":"88888",
"U":"kelvin",
"RMK":"qw\"otz",
"MTH":"m'ethod",
"D":"Bobby Brown",
"DTR":"Bobby Brown"
},
{
"TYP":"air temperature",
"VAL":"-5",
"U":"celsius",
"RMK":"this is so fake",
"MTH":"fake",
"D":"Dusty L. McDonald",
"DTR":"Dusty L. McDonald"
},
{
"TYP":"electrical conductivity",
"VAL":"6",
"U":"S/m",
"RMK":"",
"MTH":"",
"D":"",
"DTR":""
},
{
"TYP":"fake cat too",
"VAL":"common",
"U":"",
"RMK":"",
"MTH":"",
"D":"",
"DTR":""
},
{
"TYP":"fake cat too",
"VAL":"rare",
"U":"",
"RMK":"",
"MTH":"",
"D":"",
"DTR":""
},
{
"TYP":"fake cat too",
"VAL":"rare",
"U":"",
"RMK":"",
"MTH":"",
"D":"",
"DTR":""
},
{
"TYP":"fake cattoo",
"VAL":"uncommon",
"U":"",
"RMK":"",
"MTH":"",
"D":"",
"DTR":""
},
{
"TYP":"fake categorical",
"VAL":"abandoned loan",
"U":"",
"RMK":"",
"MTH":"",
"D":"",
"DTR":""
},
{
"TYP":"fake categorical",
"VAL":"repository agreement",
"U":"",
"RMK":"",
"MTH":"",
"D":"",
"DTR":""
},
{
"TYP":"fake string",
"VAL":"boogity too",
"U":"",
"RMK":"",
"MTH":"boogity",
"D":"",
"DTR":""
},
{
"TYP":"fake string",
"VAL":"this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long this is long",
"U":"",
"RMK":"",
"MTH":"",
"D":"",
"DTR":""
},
{
"TYP":"fake string",
"VAL":"this is long toothis is long toothis is long toothis is long toothis is long toothis is long toothis is long toothis is long to othis is long toothis is long toothis is long toothis is long toothis is long toothis is long too",
"U":"",
"RMK":"",
"MTH":"",
"D":"",
"DTR":""
},
{
"TYP":"fake string",
"VAL":"this was just added",
"U":"",
"RMK":"",
"MTH":"",
"D":"",
"DTR":""
},
{
"TYP":"water temperature",
"VAL":"water was very cold",
"U":"",
"RMK":"",
"MTH":"",
"D":"",
"DTR":""
}
]Oracle12 would somewhat help by moving the length of varchar from 4K to
32K. Postgres has no defined limits and would make this almost completely
irrelevant.I tentatively propose we standardize around using shortened keys in JSON
data. Better ideas?—
You are receiving this because you are subscribed to this thread.
Reply to this email directly, view it on GitHub
https://github.com/ArctosDB/arctos/issues/2131?email_source=notifications&email_token=ADQ7JBC7WAC43SUB2VLAAKLP4JHJNA5CNFSM4H3KP5P2YY3PNVWWK3TUL52HS4DFUVEXG43VMWVGG33NNVSW45C7NFSM4G3TLCSA,
or mute the thread
https://github.com/notifications/unsubscribe-auth/ADQ7JBFHS66PJKGT7FTD2ZTP4JHJNANCNFSM4H3KP5PQ
.
 campmlc
on 25 Jun 2019
campmlc
on 25 Jun 2019
Sounds reasonable, but how about just making a shortened key list and using single or two digit keys? Something like:
TY = TYPE
VU = VALUE
UN = UNITS
RK = REMARK
MD = METHOD
DA = DATE
DT = DETERMINER
Maybe not as human readable, but we can keep a code list and this way we will know that all codes will take the same amount of space.
 Jegelewicz
on 25 Jun 2019
Jegelewicz
on 25 Jun 2019
What are the cons of using the shortened keys?
They're slightly more cryptic.
Who would care if we are using something non-standard?
If you mean the array approach, it's "non-standard" as in not what is generally expected, not non-Standard as in does not comply with RFC 8259. In theory, no programmer cares - it's the same data, you can do the same things with it. In practice, it's less commonly used and will probably mess with people's idea of what JSON should look like.
The arrays format is also not very human-readable - instead of a bunch of key-value pairs, things like the various columns in specimenresults would by default be more or less gibberish. I could fix that fairly easily, but it would be more work to build and maintain and would require significantly more resources from your browser.
This would be a temporary fix if we move to Postgres?
It could be, but changing things is generally evil - eg, I use these things throughout Arctos, and the point of JSON is that others may use them for their own applications. That would have to be another discussion if we get to a point where length is less important.
Can we just document it?
Sure, I'm just not sure how. It will all be in the git/DDL repository so should be clear enough to anyone who finds that. It may not be clear that we've used some function to populate some value in some JSON object in some column.
keep a code list
Seems like a reasonable start anyway. I'll use your values for now, and try to start some documentation once the dust has settled a bit (unless someone finds a reason to avoid this approach).
Ive also combined value and units - that saves some 'bandwidth,' probably generally makes things more human-readable, but would be more difficult to extract.
{"T":"air temperature","V":"88888 kelvin","R":"qw\"otz","M:"m'ethod","D":"2019-06-02","A":"Bobby Brown"}
Now's a good time if that need un-done....
dustymc
on 25 Jun 2019
Can we just document it?Sure, I'm just not sure how. It will all be in the git/DDL repository so should be clear enough to anyone who finds that. It may not be clear that we've used some function to populate some value in some JSON object in some column.
Can we add a code table in Arctos? Even if it isn't being used by us (as part of Arctos), it would be in a public place.
Jegelewicz
on 25 Jun 2019
Ive also combined value and units - that saves some 'bandwidth,' probably generally makes things more human-readable, but would be more difficult to extract.
Ick. But maybe if they are separated by something that makes them easy to parse? Is the space between them enough?
Jegelewicz
on 25 Jun 2019
add a code table in Arctos?
Yea, not a bad idea.
Ick
Yea... all values with units are numeric, so yes they can be parsed on the space. Still ick though. If someone was actually using this I'd ask them what they want....
Here's the locality stack for specimen with a couple of events, some geology, and some event attributes.
[
{
"ST":"collection",
"VS":"unaccepted",
"VB":"",
"VD":"",
"AB":"Dusty L. McDonald",
"AD":"2019-05-01",
"CM":"",
"CS":"",
"BD":"1956-07-01",
"ED":"1956-07-01",
"VBD":"01 JUL 1956",
"VBL":"Point Barrow",
"HB":"",
"SL":"Point Barrow",
"CD":"71.3875,-156.481111",
"CE":"602 m",
"EL":"",
"DP":"",
"DM":"World Geodetic System 1984",
"HG":"North America, Beaufort Sea, United States, Alaska",
"GY":[
{
"TY":"Eon/Eonothem",
"VU":"Precambrian",
"RK":"remarkable!",
"MD":"looks old",
"DA":"2019-06-02",
"DT":"J. R. Lichtenfels"
},
{
"TY":"formation",
"VU":"Bafunzawa Formation",
"RK":"",
"MD":"",
"DA":"",
"DT":""
},
{
"TY":"group",
"VU":"Austin Group",
"RK":"",
"MD":"",
"DA":"",
"DT":""
}
],
"EA":[
{
"TY":"air temperature",
"VU":"88888 kelvin",
"RK":"qw\"otz",
"MD":"m'ethod",
"DA":"2019-06-02",
"DT":"Bobby Brown"
},
{
"TY":"air temperature",
"VU":"-5 celsius",
"RK":"this is so fake",
"MD":"fake",
"DA":"2019-06-05",
"DT":"Dusty L. McDonald"
},
{
"TY":"electrical conductivity",
"VU":"1234567890 S/m",
"RK":"",
"MD":"",
"DA":"",
"DT":""
},
{
"TY":"fake cat too",
"VU":"rare",
"RK":"",
"MD":"",
"DA":"",
"DT":""
}
]
},
{
"ST":"collection",
"VS":"accepted",
"VB":"",
"VD":"",
"AB":"Dusty L. McDonald",
"AD":"2019-05-01",
"CM":"",
"CS":"",
"BD":"1956-07-01",
"ED":"1956-07-01",
"VBD":"01 JUL 1956",
"VBL":"Point Barrow",
"HB":"",
"SL":"Point Barrow",
"CD":"71.3875,-156.481111",
"CE":"602 m",
"EL":"",
"DP":"",
"DM":"World Geodetic System 1984",
"HG":"North America, Beaufort Sea, United States, Alaska",
"GY":[
{
"TY":"formation",
"VU":"Bafunzawa Formation",
"RK":"",
"MD":"",
"DA":"",
"DT":""
},
{
"TY":"group",
"VU":"Austin Group",
"RK":"",
"MD":"",
"DA":"",
"DT":""
},
{
"TY":"Eon/Eonothem",
"VU":"Precambrian",
"RK":"remarkable!",
"MD":"looks old",
"DA":"2019-06-02",
"DT":"J. R. Lichtenfels"
}
],
"EA":[
{
"TY":"air temperature",
"VU":"88888 kelvin",
"RK":"qw\"otz",
"MD":"m'ethod",
"DA":"2019-06-02",
"DT":"Bobby Brown"
},
{
"TY":"air temperature",
"VU":"-5 celsius",
"RK":"this is so fake",
"MD":"fake",
"DA":"2019-06-05",
"DT":"Dusty L. McDonald"
},
{
"TY":"electrical conductivity",
"VU":"1234567890 S/m",
"RK":"",
"MD":"",
"DA":"",
"DT":""
},
{
"TY":"fake cat too",
"VU":"rare",
"RK":"",
"MD":"",
"DA":"",
"DT":""
}
]
}
]
It's easy to adjust the abbreviations until it's used (sometime this week, maybe, I hope); input appreciated. The format does what I immediately need, and I think will work well enough for the average specimen in the short term, at least.
Here's the event key:
jsond:=jsond || rsep || '{';
jsond:=jsond || '"ST":"' || r.SPECIMEN_EVENT_TYPE || '"';
jsond:=jsond || ',"VS":"' || r.VERIFICATIONSTATUS || '"';
jsond:=jsond || ',"VB":"' || r.VERIFIEDBY || '"';
jsond:=jsond || ',"VD":"' || r.VERIFIEDDATE || '"';
jsond:=jsond || ',"AB":"' || r.ASSIGNEDBY || '"';
jsond:=jsond || ',"AD":"' || r.ASSIGNEDDATE || '"';
--jsond:=jsond || ',"SPECIMEN_EVENT_REMARK":"' || r.SPECIMEN_EVENT_REMARK || '"';
jsond:=jsond || ',"CM":"' || escape_json(r.COLLECTING_METHOD) || '"';
jsond:=jsond || ',"CS":"' || escape_json(r.COLLECTING_SOURCE) || '"';
jsond:=jsond || ',"BD":"' || r.BEGAN_DATE || '"';
jsond:=jsond || ',"ED":"' || r.ENDED_DATE || '"';
jsond:=jsond || ',"VBD":"' || escape_json(r.VERBATIM_DATE) || '"';
jsond:=jsond || ',"VBL":"' || escape_json(r.VERBATIM_LOCALITY) || '"';
jsond:=jsond || ',"HB":"' || escape_json(r.HABITAT) || '"';
jsond:=jsond || ',"SL":"' || escape_json(r.SPEC_LOCALITY) || '"';
jsond:=jsond || ',"CD":"' || r.COORDINATES || '"';
jsond:=jsond || ',"CE":"' || r.COORDINATE_ERROR || '"';
jsond:=jsond || ',"EL":"' || r.ELEVATION || '"';
jsond:=jsond || ',"DP":"' || r.DEPTH || '"';
jsond:=jsond || ',"DM":"' || r.DATUM || '"';
jsond:=jsond || ',"HG":"' || r.HIGHER_GEOG || '"';
jsond:=jsond || ',"GY":' || r.GEOLOGY ;
jsond:=jsond || ',"EA":' || r.eventAttrs ;
geology
jsond:=jsond || '"TY":"' || escape_json(r.GEOLOGY_ATTRIBUTE) || '"';
jsond:=jsond || ',"VU":"' || escape_json(r.GEO_ATT_VALUE) ||'"';
jsond:=jsond || ',"RK":"' || escape_json(r.GEO_ATT_REMARK) || '"';
jsond:=jsond || ',"MD":"' || escape_json(r.GEO_ATT_DETERMINED_METHOD) || '"';
jsond:=jsond || ',"DA":"' || escape_json(r.GEO_ATT_DETERMINED_DATE) || '"';
jsond:=jsond || ',"DT":"' || escape_json(r.geo_determiner) || '"';
jsond:=jsond || '}';
event attributes
jsond:=jsond || '"TY":"' || escape_json(r.event_attribute_type) || '"';
jsond:=jsond || ',"VU":"' || trim(escape_json(r.event_attribute_value) || ' ' || escape_json(r.event_attribute_units)) ||'"';
jsond:=jsond || ',"RK":"' || escape_json(r.event_attribute_remark) || '"';
jsond:=jsond || ',"MD":"' || escape_json(r.event_determination_method) || '"';
jsond:=jsond || ',"DA":"' || escape_json(r.event_determined_date) || '"';
jsond:=jsond || ',"DT":"' || escape_json(r.event_determiner) || '"';
https://github.com/ArctosDB/DDL/blob/master/functions/concatpartsdetail.sql tends to overflow and melt as well, but it's not in my way right this very second....
dustymc
on 25 Jun 2019
Seems fine to me, except for:
jsond:=jsond || ',"VBD":"' || escape_json(r.VERBATIM_DATE) || '"';
jsond:=jsond || ',"VBL":"' || escape_json(r.VERBATIM_LOCALITY) || '"';
Can they be RD and RL?
Jegelewicz
on 25 Jun 2019
done
UAM@ARCTOS> select getJsonEventBySpecimen(collection_object_id) from flat where guid='UAMObs:Ento:238566';
[
{
"ST":"collection",
"VS":"unaccepted",
"VB":"",
"VD":"",
"AB":"Dusty L. McDonald",
"AD":"2019-05-01",
"CM":"",
"CS":"",
"BD":"1956-07-01",
"ED":"1956-07-01",
"RD":"01 JUL 1956",
"RL":"Point Barrow",
"HB":"",
"SL":"Point Barrow",
"CD":"71.3875,-156.481111",
"CE":"602 m",
"EL":"",
"DP":"",
"DM":"World Geodetic System 1984",
"HG":"North America, Beaufort Sea, United States, Alaska",
"GY":[
{
"TY":"Eon/Eonothem",
"VU":"Precambrian",
"RK":"remarkable!",
"MD":"looks old",
"DA":"2019-06-02",
"DT":"J. R. Lichtenfels"
},
{
"TY":"formation",
"VU":"Bafunzawa Formation",
"RK":"",
"MD":"",
"DA":"",
"DT":""
},
{
"TY":"group",
"VU":"Austin Group",
"RK":"",
"MD":"",
"DA":"",
"DT":""
}
],
"EA":[
{
"TY":"air temperature",
"VU":"88888 kelvin",
"RK":"qw\"otz",
"MD":"m'ethod",
"DA":"2019-06-02",
"DT":"Bobby Brown"
},
{
"TY":"air temperature",
"VU":"-5 celsius",
"RK":"this is so fake",
"MD":"fake",
"DA":"2019-06-05",
"DT":"Dusty L. McDonald"
},
{
"TY":"electrical conductivity",
"VU":"1234567890 S/m",
"RK":"",
"MD":"",
"DA":"",
"DT":""
},
{
"TY":"fake cat too",
"VU":"rare",
"RK":"",
"MD":"",
"DA":"",
"DT":""
}
]
},
{
"ST":"collection",
"VS":"accepted",
"VB":"",
"VD":"",
"AB":"Dusty L. McDonald",
"AD":"2019-05-01",
"CM":"",
"CS":"",
"BD":"1956-07-01",
"ED":"1956-07-01",
"RD":"01 JUL 1956",
"RL":"Point Barrow",
"HB":"",
"SL":"Point Barrow",
"CD":"71.3875,-156.481111",
"CE":"602 m",
"EL":"",
"DP":"",
"DM":"World Geodetic System 1984",
"HG":"North America, Beaufort Sea, United States, Alaska",
"GY":[
{
"TY":"Eon/Eonothem",
"VU":"Precambrian",
"RK":"remarkable!",
"MD":"looks old",
"DA":"2019-06-02",
"DT":"J. R. Lichtenfels"
},
{
"TY":"formation",
"VU":"Bafunzawa Formation",
"RK":"",
"MD":"",
"DA":"",
"DT":""
},
{
"TY":"group",
"VU":"Austin Group",
"RK":"",
"MD":"",
"DA":"",
"DT":""
}
],
"EA":[
{
"TY":"air temperature",
"VU":"-5 celsius",
"RK":"this is so fake",
"MD":"fake",
"DA":"2019-06-05",
"DT":"Dusty L. McDonald"
},
{
"TY":"air temperature",
"VU":"88888 kelvin",
"RK":"qw\"otz",
"MD":"m'ethod",
"DA":"2019-06-02",
"DT":"Bobby Brown"
},
{
"TY":"electrical conductivity",
"VU":"1234567890 S/m",
"RK":"",
"MD":"",
"DA":"",
"DT":""
},
{
"TY":"fake cat too",
"VU":"rare",
"RK":"",
"MD":"",
"DA":"",
"DT":""
},
{
"TY":"air temperature",
"VU":"-7 fahrenheit",
"RK":"",
"MD":"another edit",
"DA":"",
"DT":""
}
]
},
{
"ST":"collection",
"VS":"unaccepted",
"VB":"",
"VD":"",
"AB":"Dusty L. McDonald",
"AD":"2019-05-01",
"CM":"",
"CS":"",
"BD":"1956-07-01",
"ED":"1956-07-01",
"RD":"01 JUL 1956",
"RL":"Point Barrow",
"HB":"",
"SL":"Point Barrow",
"CD":"71.3875,-156.481111",
"CE":"602 m",
"EL":"",
"DP":"",
"DM":"World Geodetic System 1984",
"HG":"North America, Beaufort Sea, United States, Alaska",
"GY":[
{
"TY":"formation",
"VU":"Bafunzawa Formation",
"RK":"",
"MD":"",
"DA":"",
"DT":""
},
{
"TY":"group",
"VU":"Austin Group",
"RK":"",
"MD":"",
"DA":"",
"DT":""
},
{
"TY":"Eon/Eonothem",
"VU":"Precambrian",
"RK":"remarkable!",
"MD":"looks old",
"DA":"2019-06-02",
"DT":"J. R. Lichtenfels"
}
],
"EA":[
{
"TY":"air temperature",
"VU":"88888 kelvin",
"RK":"qw\"otz",
"MD":"m'ethod",
"DA":"2019-06-02",
"DT":"Bobby Brown"
},
{
"TY":"air temperature",
"VU":"-5 celsius",
"RK":"this is so fake",
"MD":"fake",
"DA":"2019-06-05",
"DT":"Dusty L. McDonald"
},
{
"TY":"electrical conductivity",
"VU":"1234567890 S/m",
"RK":"",
"MD":"",
"DA":"",
"DT":""
},
{
"TY":"fake cat too",
"VU":"rare",
"RK":"",
"MD":"",
"DA":"",
"DT":""
}
]
}
]
It looks very neat - I like that.
Jegelewicz
on 25 Jun 2019
I'm kinda digging it too - I just added JSON event attributes and locality to edit specimen event....
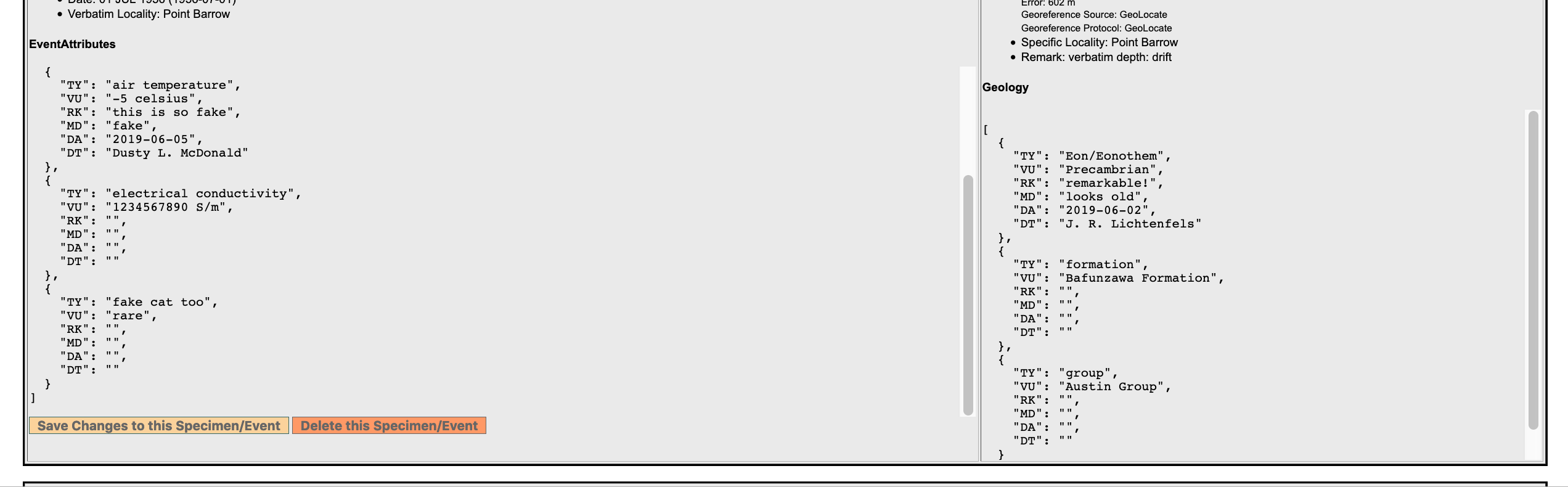
To me, that's more readable than this mess....

so maybe I'll use the JSON format on specimendetail as well??
dustymc
on 25 Jun 2019
No, please don't put JSON in specimen detail. It is not readable to general
public
On Tue, Jun 25, 2019, 2:47 PM dustymc notifications@github.com wrote:
I'm kinda digging it too - I just added JSON event attributes and locality
to edit specimen event....
[image: Screen Shot 2019-06-25 at 1 44 47 PM]
https://user-images.githubusercontent.com/5720791/60131953-6be6a900-974f-11e9-8a46-7123f2190d44.pngTo me, that's more readable than this mess....
[image: Screen Shot 2019-06-25 at 1 45 15 PM]
https://user-images.githubusercontent.com/5720791/60132001-80c33c80-974f-11e9-8dcc-bb30e83013c2.pngso maybe I'll use the JSON format on specimendetail as well??
—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
https://github.com/ArctosDB/arctos/issues/2131?email_source=notifications&email_token=ADQ7JBHETC43POR6ES3MGATP4J75FA5CNFSM4H3KP5P2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGODYRROIA#issuecomment-505616160,
or mute the thread
https://github.com/notifications/unsubscribe-auth/ADQ7JBBV4MVMTJQIEVJ2FZDP4J75FANCNFSM4H3KP5PQ
.
campmlc
on 25 Jun 2019
I agree with Mariel. For specimen event detail the full blown descriptions are better.
Jegelewicz
on 25 Jun 2019
dustymc
on 2 Jul 2019
Reopening this ref https://github.com/ArctosDB/arctos/issues/2141#issuecomment-508156330
The keys are a bit esoteric
We're in postgres, JSON is a datatype, there are no limitations on string length that we're likely to encounter. Verbose keys still have costs (storage and transmission), but they're not the limitation they were in 2019. Should we change eg ST to specimen_event_type?
dustymc
on 17 Mar 2021
Verbose keys still have costs (storage and transmission), but they're not the limitation they were in 2019. Should we change eg ST to specimen_event_type?
pro would be that you would know what the heck each "thing" was (sort-of, because the field names aren't always super-clear)
con the blob gets huge - IS that a con?
What else?
Jegelewicz
on 17 Mar 2021
con the blob gets huge - IS that a con?
Depends what you're trying to do. It might add a few GB to a file. Is that balanced by easier understanding? (We'll keep https://handbook.arctosdb.org/documentation/json.html, whatever else happens, so it is possible to figure out our keys, however they're spelled.)
Longer would also be a bit more likely to wrap or overflow in some views.
dustymc
on 17 Mar 2021
Related issues
 sharpphyl
·
7Comments
sharpphyl
·
7Comments
 mkoo
·
3Comments
dustymc
·
3Comments
Jegelewicz
·
6Comments
mkoo
·
3Comments
dustymc
·
3Comments
Jegelewicz
·
6Comments
 DerekSikes
·
3Comments
DerekSikes
·
3Comments
Most helpful comment
I agree with Mariel. For specimen event detail the full blown descriptions are better.