Apex: Apply apex to an already trained normal model and continue the training
Can I train a PyTorch model for let's say 4 epochs in a normal fashion while saving the model, and then continue the training by applying amp?
 Rhuax
Rhuax
All 23 comments
I don't know the best way to do this off the top of my head, but I'm taking a detailed look at amp checkpointing (saving/restoring models) this week and next week, and I'll include this use case on my list of things to support.
 mcarilli
on 8 Apr 2019
mcarilli
on 8 Apr 2019
I'm pretty sure if you load existing FP32 weights into your model before AMPing it'll just work. I've done that successfully.
I think that restoring the optimizer state can be problematic, even if it's before initializing AMP (memory fuzzy).
 rwightman
on 15 Apr 2019
rwightman
on 15 Apr 2019
In NVIDIA/tacotron2, you seem to be able to go from FP16 -> full precision and back with no problem. OTOH I just ran into an issue where the first few updates wreck the previous loss, wiping out many epochs worth of optimization. Seems like a Checkpointing issue...
 apsears
on 15 Apr 2019
apsears
on 15 Apr 2019
@mcarilli do you have any ETA on this? I really think this is a critical feature. As of now, I cannot use AMP as it gives me the following divergence issues after checkpoint reloading:
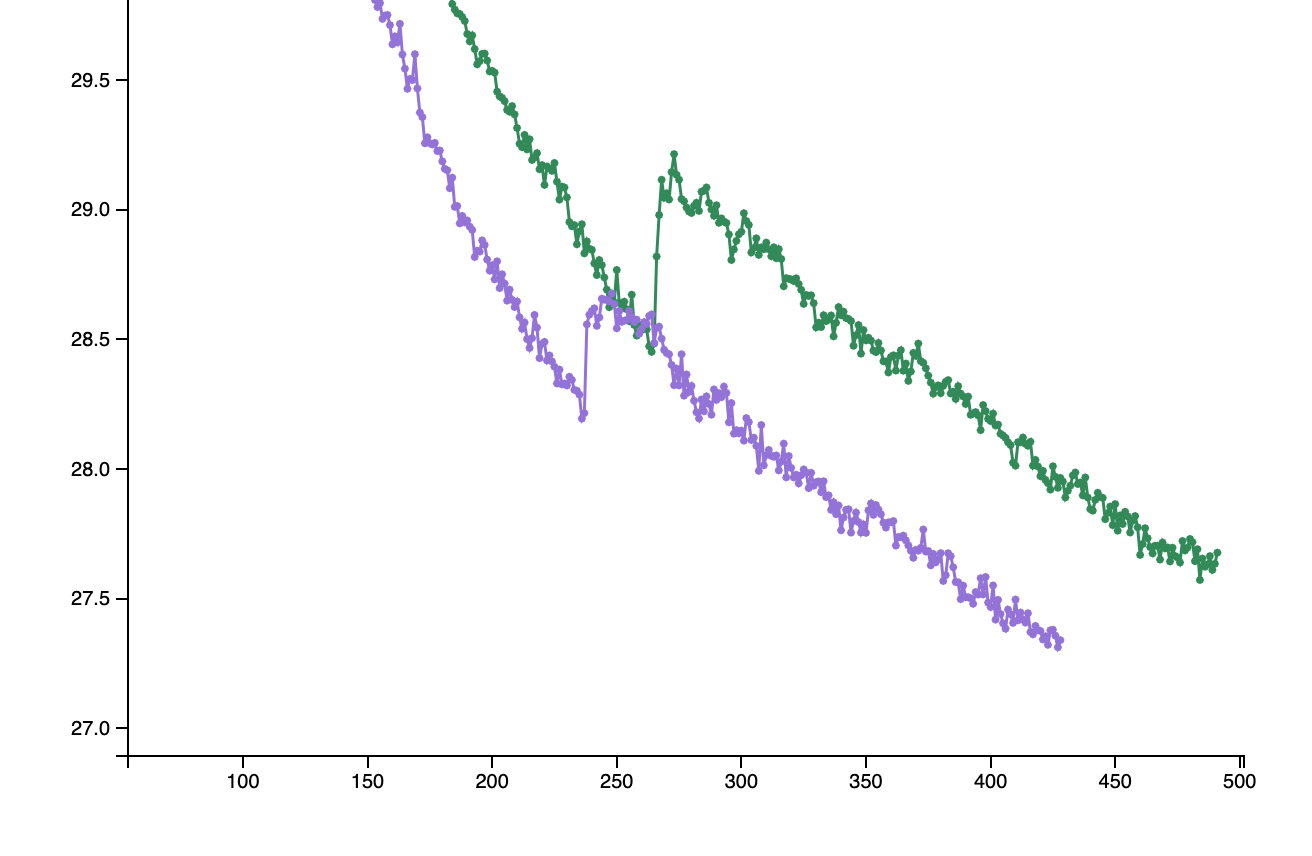
In that case experiments ended up recovering, but sometimes they never reach the performance they were at during the checkpoint. For now I switched back to FP16_Optimizer because it does not have the same problem, but I miss the ability to accumulate gradients over several batches, which limits the performance I can get in some tasks.
Thanks!
 glample
on 28 May 2019
glample
on 28 May 2019
I agree it's a critical feature. @ptrblck and I decided on a strategy then got preempted with a bunch of work debugging/optimizing some internal models. I'm hoping to implement it next week, barring further interrupts...I'll keep you updated if that changes.
mcarilli
on 29 May 2019
@mcarilli any luck with the checkpointing?
Do you know if there is a temporary workaround I could use in the meantime?
glample
on 14 Jun 2019
Any progress?
 hadaev8
on 27 Jul 2019
hadaev8
on 27 Jul 2019
@Rhuax, @rwightman, @apsears, @glample, @hadaev8
Checkpointing just got merged into out master branch.
Checkout the README to see an example usage.
 ptrblck
on 27 Aug 2019
ptrblck
on 27 Aug 2019
@ptrblck
May you give example how to load inside a function?
def load_checkpoint(checkpoint_path, model, optimizer, warm_start_rus):
assert os.path.isfile(checkpoint_path)
print("Loading checkpoint '{}'".format(checkpoint_path))
checkpoint_dict = torch.load(checkpoint_path, map_location='cpu')
model.load_state_dict(checkpoint_dict['state_dict'])
optimizer.load_state_dict(checkpoint_dict['optimizer'])
amp.load_state_dict(checkpoint['amp'])
print("Loaded checkpoint '{}' from iteration {}" .format(
checkpoint_path, iteration))
return model, optimizer, learning_rate, iteration
I need to pass amp inside, right?
hadaev8
on 28 Aug 2019
@hadaev8 This should work, if you've called amp.initialize before on your model and optimizer.
ptrblck
on 29 Aug 2019
@ptrblck
AttributeError: 'AmpState' object has no attribute 'loss_scalers'
Any advice?
hadaev8
on 29 Aug 2019
@hadaev8 Could you post a reproducible code snippet so that we can debug it?
ptrblck
on 30 Aug 2019
My code based on this repo
https://github.com/NVIDIA/tacotron2
Not easy to make snippet
hadaev8
on 30 Aug 2019
@ptrblck
https://i.imgur.com/0962R8H.png
hadaev8
on 7 Sep 2019
Thanks for the update.
amp.state_dict() tries to return the loss_scaler(s), which aren't initialized in your code snippet.
Make sure to create a model and call amp.initialize() on it first.
model = nn.Linear(1, 1).cuda()
model = amp.initialize(model, opt_level='O1')
amp.state_dict()
Anyway, we should improve the error message and raise a proper warning.
ptrblck
on 9 Sep 2019
@ptrblck
I get my problem case, tried to set state dict before amp.initialize, thanks.
hadaev8
on 9 Sep 2019
Hey, @ptrblck! Thanks for following up with everyone in this thread. FYI, I get the same problem of the checkpoint with opt_level='O2' but it works with opt_level='O1'
 giacaglia
on 2 Dec 2019
giacaglia
on 2 Dec 2019
@giacaglia What kind of error are you seeing? Do you see a bump in the loss(es)?
If so, did you also restored the optimizer's state_dict as well as amp's?
ptrblck
on 5 Dec 2019
Yes, I did see a big bump in the losses. I saved the optimizer's state_dict as well as amp's. The problem doesn't occur when I set opt_level to O1. I can try to make the problem reproducible if that is of any help
giacaglia
on 5 Dec 2019
Sure! That would be helpful for debugging, although we recommend to use O1. ;)
ptrblck
on 5 Dec 2019
@ptrblck Can you confirm you recommend O1? Aren't the vast bulk of the speed improvements due to the O2 optimizations?
 daniel347x
on 22 Feb 2020
daniel347x
on 22 Feb 2020
@daniel347x
Yes, we recommend O1 for the typical use case. You might of course compare different opt levels for your use case. :)
ptrblck
on 22 Feb 2020
@ptrendx I get the AttributeError: 'AmpState' object has no attribute 'loss_scalers' error as @hadaev8 but I am saving the state after a few batches. I think it might be important to mention that I have the enabled parameter of amp.initialize set to False. Could you please initialize the loss_scalers with some dummy data to allow for versatility? A workaround is to enable AMP but use O0.
 danieltudosiu
on 26 Mar 2020
danieltudosiu
on 26 Mar 2020
Related issues
 dave-epstein
·
3Comments
dave-epstein
·
3Comments
 flymark2010
·
3Comments
flymark2010
·
3Comments
 ccoulombe
·
3Comments
ccoulombe
·
3Comments
 DeeDive
·
4Comments
DeeDive
·
4Comments
 aliyesilkanat
·
4Comments
aliyesilkanat
·
4Comments
Most helpful comment
@Rhuax, @rwightman, @apsears, @glample, @hadaev8
Checkpointing just got merged into out master branch.
Checkout the README to see an example usage.