Amplify-cli: Any way to avoid duplicated data from graphql query
Say you have a graphql schema like this:
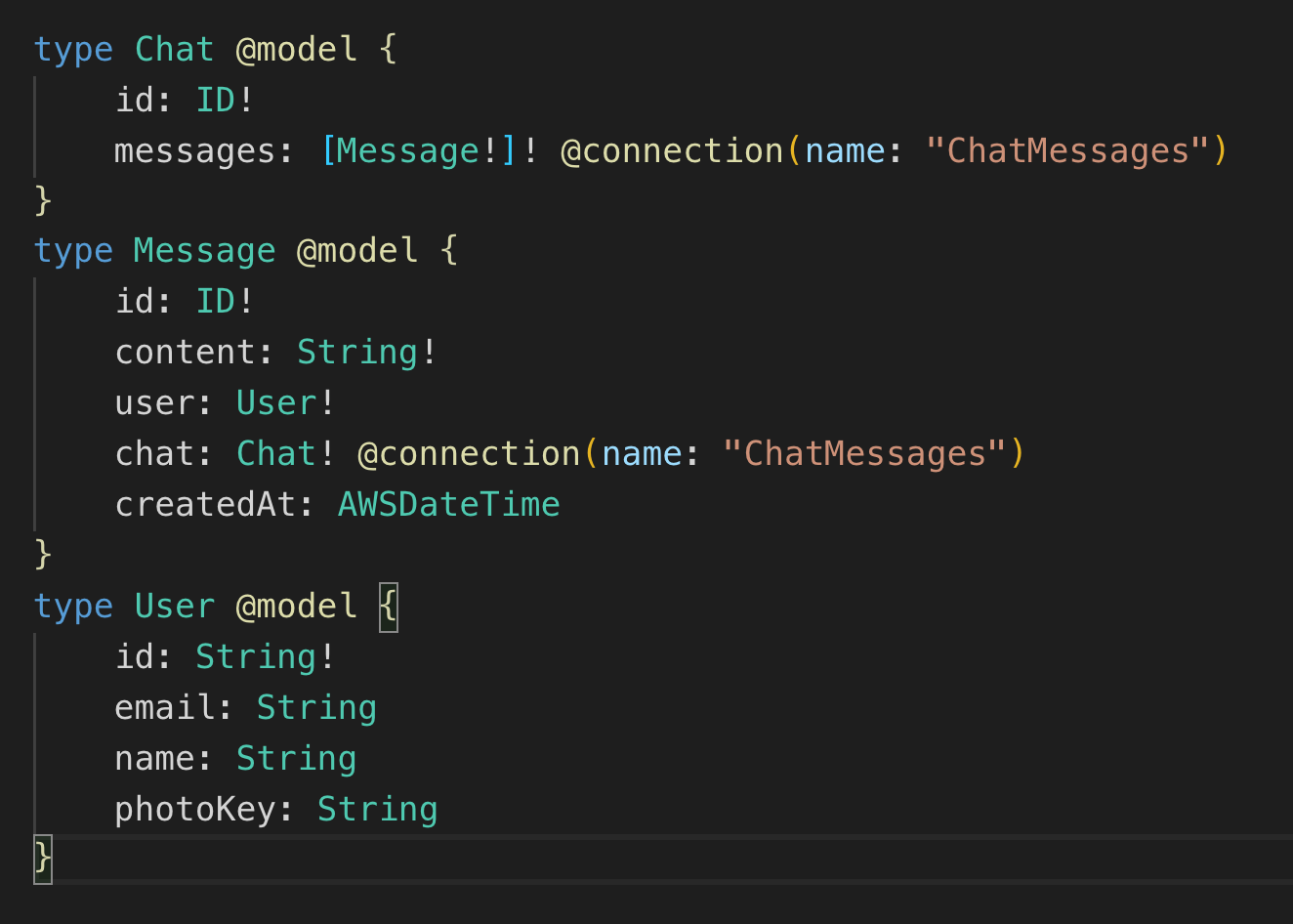
If you want to get all the required data for rendering the chat in a single query, the query would look something like this:

But of course that means that there will be possibility for huge duplication of data about users in the response (wasting resources everywhere).
Is there any way in Amplify to specify so that the server returns each individual Users' data just once in the whole response, and then in other places it uses just the id?
Any other idea of how to approach this? (Besides the obvious way of fetching just users' ids, and then fetching user's data in separate graphql query) . Thanks!
 tgjorgoski
tgjorgoski
All 6 comments
@tgjorgoski You can specify what you would like as a response in the graphql query. So if you didn't want to duplicate the data for chat you can limit the info to just the user and not include the chat
query {
getChat(id: "....") {
id
content
createdAt
user {
id
email # and other necessary info related to user and not add chat related info
}
}
}
If you have any other questions on this please feel free to comment.
 SwaySway
on 3 Oct 2019
SwaySway
on 3 Oct 2019
@SwaySway , I'm affraid you didn't understand the question.
I want to get the chat messages including WHO wrote them. However if e.g. 1 person wrote 500 of the messages, if you get user data with each message you will receive 500 times the same user info.
Now, of course you can request JUST the user id, and AFTER the initial query, make additional one requesting the details.
However, I'm asking if there is a way to do it using just a single query, so that ALL the details for the user will be present the first time that user data is encountered (the first comment in the query results), but not the following times (in the following comments, it would include just the user id).
I read somewhere in the Apollo Client documentation somewhere that it will handle that kind of query result nicely using its data normalization.
Also, there are libraries like https://github.com/gajus/graphql-deduplicator , which are supposed to do that, removing the duplicated data from the resulting query. However it would be better if there is a way/option that the duplicated data isn't included in the query result in the first place.
tgjorgoski
on 3 Oct 2019
@tgjorgoski
I don't believe this is possible with a getChat query at least not out of the box.
Another thing to consider would be adding a one-to-many @connection between a User and Message.
SwaySway
on 7 Oct 2019
Thanks @SwaySway . I haven't looked into the possibility of building custom appsync pipelines, but wonder if something like this could be done by adding a lambda function and runing that deduplicator library before returning the response.
And I wonder another thing, do the default AppSync resolvers which connect to DynamoDB make multiple requests in this kind of case (when the same 'foreign key' userid appears for multiple comments), or is each requested user cached internally, so there is smaller number of queries? Not that it would help knowing this, but certainly it might affect the number of queries done against DynamoDB, and how much is spent for such query.
tgjorgoski
on 7 Oct 2019
@tgjorgoski The requests will not be cached internally in the resolvers. Feel free to reopen/comment if you have further questions.
 nikhname
on 14 Oct 2019
nikhname
on 14 Oct 2019
@SwaySway , I'm affraid you didn't understand the question.
I want to get the chat messages including WHO wrote them. However if e.g. 1 person wrote 500 of the messages, if you get user data with each message you will receive 500 times the same user info.
Now, of course you can request JUST the user id, and AFTER the initial query, make additional one requesting the details.
However, I'm asking if there is a way to do it using just a single query, so that ALL the details for the user will be present the first time that user data is encountered (the first comment in the query results), but not the following times (in the following comments, it would include just the user id)....Exactly, that is one of the things that I find annoying about graphQL. SQL does not duplicate data like this, and has aggregation and the DISTINCT keyword to further reduce duplicates.
 Slowly
on 14 Jan 2020
Slowly
on 14 Jan 2020
Related issues
 YikSanChan
·
3Comments
YikSanChan
·
3Comments
 gabriel-wilkes
·
3Comments
gabriel-wilkes
·
3Comments
 onlybakam
·
3Comments
onlybakam
·
3Comments
 rehos
·
3Comments
rehos
·
3Comments
 kstro21
·
3Comments
kstro21
·
3Comments