Amplify-cli: Which resources are needed for batch mutations
* Which Category is your question related to? *
API (Custom resolvers)
* What AWS Services are you utilizing? *
AppSync, Cognito
* Provide additional details e.g. code snippets *
I'm building a React app using AWS Amplify. I use Cognito User Pools for authentication and a GraphQL AppSync API for my backend. (amplify add auth, amplify add api).
I want to add a mutation to batch create items:
type Todo @model @auth(rules: [{ allow: owner }]) {
id: ID!
title: String!
description: String
completed: Boolean
}
input CreateTodoInput {
id: ID
title: String!
description: String
completed: Boolean
}
type Mutation {
batchAddTodos(todos: [CreateTodoInput]): [Todo]
}
In order for this custom mutation to work, I have to add the used Resources in CustomResources.json:
// Left everything as it was
"Resources": {
"EmptyResource": {
"Type": "Custom::EmptyResource",
"Condition": "AlwaysFalse"
},
"BatchAddTodosResolver": {
"Type": "AWS::AppSync::Resolver",
"Properties": {
"ApiId": {
"Ref": "AppSyncApiId"
},
"DataSourceName": "TodoTable",
"TypeName": "Mutation",
"FieldName": "batchAddTodos",
"RequestMappingTemplateS3Location": {
"Fn::Sub": [
"s3://${S3DeploymentBucket}/${S3DeploymentRootKey}/resolvers/Mutation.batchAddTodos.req.vtl",
{
"S3DeploymentBucket": {
"Ref": "S3DeploymentBucket"
},
"S3DeploymentRootKey": {
"Ref": "S3DeploymentRootKey"
}
}
]
},
"ResponseMappingTemplateS3Location": {
"Fn::Sub": [
"s3://${S3DeploymentBucket}/${S3DeploymentRootKey}/resolvers/Mutation.batchAddTodos.res.vtl",
{
"S3DeploymentBucket": {
"Ref": "S3DeploymentBucket"
},
"S3DeploymentRootKey": {
"Ref": "S3DeploymentRootKey"
}
}
]
}
}
}
},
// ... more code that I didn't touch
I assume there are permissions that I'm missing in these resources because of the error that I get. I will describe it further below.
I also wrote a custom resolver mapping for the requests (Mutation.batchAddTodos.req.vtl):
#foreach($item in ${ctx.args.todos})
## [Start] Owner Authorization Checks **
#set( $isOwnerAuthorized = false )
## Authorization rule: { allow: "owner", ownerField: "owner", identityField: "cognito:username" } **
#set( $allowedOwners0 = $util.defaultIfNull($item.owner, null) )
#set( $identityValue = $util.defaultIfNull($ctx.identity.claims.get("username"),
$util.defaultIfNull($ctx.identity.claims.get("cognito:username"), "___xamznone____")) )
#if( $util.isList($allowedOwners0) )
#foreach( $allowedOwner in $allowedOwners0 )
#if( $allowedOwner == $identityValue )
#set( $isOwnerAuthorized = true )
#end
#end
#end
#if( $util.isString($allowedOwners0) )
#if( $allowedOwners0 == $identityValue )
#set( $isOwnerAuthorized = true )
#end
#end
#if( $util.isNull($allowedOwners0) && (! $item.containsKey("owner")) )
$util.qr($item.put("owner", $identityValue))
#set( $isOwnerAuthorized = true )
#end
## [End] Owner Authorization Checks **
## [Start] Throw if unauthorized **
#if( !($isStaticGroupAuthorized == true || $isDynamicGroupAuthorized == true || $isOwnerAuthorized
== true) )
$util.unauthorized()
#end
## [End] Throw if unauthorized **
#end
#set($todosdata = [])
#foreach($item in ${ctx.args.todos})
$util.qr($item.put("createdAt", $util.time.nowISO8601()))
$util.qr($item.put("updatedAt", $util.time.nowISO8601()))
$util.qr($item.put("__typename", "Todo"))
$util.qr($item.put("id", $util.defaultIfNullOrBlank($item.id, $util.autoId())))
$util.qr($todosdata.add($util.dynamodb.toMapValues($item)))
#end
{
"version": "2018-05-29",
"operation": "BatchPutItem",
"tables": {
"TodoTable": $utils.toJson($todosdata)
}
}
and for the response:
#if ($ctx.error)
$util.appendError($ctx.error.message, $ctx.error.type, null, $ctx.result.data.unprocessedKeys)
#end
$util.toJson($ctx.result.data)
In the former, I faced an error where It would say that BatchPutItem is an unknown operation, which I fixed by using "2018-05-29" instead of "2017-02-28".
With this set up I tried running the following code in my React app:
import API, { graphqlOperation } from '@aws-amplify/api';
// ... later
async function handleClick() {
const todoFixtures = [
{ id: 1, title: 'Get groceries', description: '', completed: false },
{ id: 2, title: 'Go to the gym', description: 'Leg Day', completed: true }
];
try {
const input = { todos: prepareTodos(todoFixtures) };
const res = await API.graphql(graphqlOperation(batchAddTodos, input));
console.log(res);
} catch (err) {
console.log('error ', err);
}
}
But it didn't work (error message further below). So I thought, I try it out from the AppSync console:
mutation add {
batchAddTodos(todos: [
{title: "Hello", description: "Test", completed: false}
]) {
id title
}
}
Both attempts resulted in the error:
{
"data": {
"batchAddTodos": null
},
"errors": [
{
"path": [
"batchAddTodos"
],
"data": null,
"errorType": "DynamoDB:AmazonDynamoDBException",
"errorInfo": null,
"locations": [
{
"line": 32,
"column": 3,
"sourceName": null
}
],
"message": "User: arn:aws:sts::655817346595:assumed-role/Todo-role-naona7ytt5drxazwmtp7a2uccy-batch/APPSYNC_ASSUME_ROLE is not authorized to perform: dynamodb:BatchWriteItem on resource: arn:aws:dynamodb:eu-central-1:655817346595:table/TodoTable (Service: AmazonDynamoDBv2; Status Code: 400; Error Code: AccessDeniedException; Request ID: EP48SJPVMB9G9M69HPR0BO8SKJVV4KQNSO5AEMVJF66Q9ASUAAJG)"
},
{
"path": [
"batchAddTodos"
],
"locations": null,
"message": "Can't resolve value (/batchAddTodos) : type mismatch error, expected type LIST"
}
]
}
Now I'm stuck. I spent hours trying to figure out what is wrong, but can't find a solution. type mismatch error, expected type LIST might mean that the value for todos is wrong, but I do give an array as my input and not an object. And APPSYNC_ASSUME_ROLE is not authorized to perform: dynamodb:BatchWriteItem makes me suspect, that I'm missing a key about authentication in the CustomResources.json file. I could'nt find anything helpful in neither the AWS Amplify docs, nor the AWS AppSync docs.
Any help about what's wrong here would be much appreciated 🤗
This issue is kind of a follow up on this issue.
 janhesters
janhesters
All 25 comments
@janhesters I'll migrate this issue to the cli repo (same as #2896).
 manueliglesias
on 20 Mar 2019
manueliglesias
on 20 Mar 2019
@janhesters The IAM policy is created by the @model directive and should be providing access to the BatchWriteItem operation in DynamoDB. To be sure can you double check your TodoStack.json file in the build/ directory? There should be a resource with the logical id "TodoIAMRole" that includes a policy with all of the actions seen below. You should also see a AssumeRolePolicyDocument that gives assume role access to appsync.amazonaws.com. https://github.com/aws-amplify/amplify-cli/blob/767f3a6edce9f8c4109e18afacf648c6d4c7be56/packages/graphql-dynamodb-transformer/src/resources.ts#L257-L266. The AppSync data source will assume this role every time it wants to talk to a table in your account.
The error type mismatch error, expected type LIST is referring to the value returned by the response mapping template, not the input you are passing. You can "log" while debugging by appending an error:
$util.appendError($util.toJson($ctx.result.data))
 mikeparisstuff
on 20 Mar 2019
mikeparisstuff
on 20 Mar 2019
@mikeparisstuff It is!
"TodoIAMRole": {
"Type": "AWS::IAM::Role",
"Properties": {
"RoleName": {
"Fn::If": [
"HasEnvironmentParameter",
{
"Fn::Join": [
"-",
[
"Todo",
"role",
{
"Ref": "GetAttGraphQLAPIApiId"
},
{
"Ref": "env"
}
]
]
},
{
"Fn::Join": [
"-",
[
"Todo",
"role",
{
"Ref": "GetAttGraphQLAPIApiId"
}
]
]
}
]
},
"AssumeRolePolicyDocument": {
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "appsync.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
},
"Policies": [
{
"PolicyName": "DynamoDBAccess",
"PolicyDocument": {
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"dynamodb:BatchGetItem",
"dynamodb:BatchWriteItem",
"dynamodb:PutItem",
"dynamodb:DeleteItem",
"dynamodb:GetItem",
"dynamodb:Scan",
"dynamodb:Query",
"dynamodb:UpdateItem"
],
"Resource": [
{
"Fn::Sub": [
"arn:aws:dynamodb:${AWS::Region}:${AWS::AccountId}:table/${tablename}",
{
"tablename": {
"Fn::If": [
"HasEnvironmentParameter",
{
"Fn::Join": [
"-",
[
"Todo",
{
"Ref": "GetAttGraphQLAPIApiId"
},
{
"Ref": "env"
}
]
]
},
{
"Fn::Join": [
"-",
[
"Todo",
{
"Ref": "GetAttGraphQLAPIApiId"
}
]
]
}
]
}
}
]
},
{
"Fn::Sub": [
"arn:aws:dynamodb:${AWS::Region}:${AWS::AccountId}:table/${tablename}/*",
{
"tablename": {
"Fn::If": [
"HasEnvironmentParameter",
{
"Fn::Join": [
"-",
[
"Todo",
{
"Ref": "GetAttGraphQLAPIApiId"
},
{
"Ref": "env"
}
]
]
},
{
"Fn::Join": [
"-",
[
"Todo",
{
"Ref": "GetAttGraphQLAPIApiId"
}
]
]
}
]
}
}
]
}
]
}
]
}
}
]
}
},
which makes it extra weird that the auth error is thrown. I can provide you with detailed steps on what I did. Maybe one has to somehow add this to the CustomResources.json file?
janhesters
on 20 Mar 2019
@mikeparisstuff The assumerole policy is there, too:
"AssumeRolePolicyDocument": {
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "appsync.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
},
The error type mismatch error, expected type LIST is referring to the value returned by the response mapping template, not the input you are passing. You can "log" while debugging by appending an error:
$util.appendError($util.toJson($ctx.result.data))
So you mean in Mutation.batchAddTodos.res.vtl I should write:
#if ($ctx.error)
$util.appendError($util.toJson($ctx.result.data))
#end
$util.toJson($ctx.result.data)
Instead of:
#if ($ctx.error)
$util.appendError($ctx.error.message, $ctx.error.type, null, $ctx.result.data.unprocessedKeys)
#end
$util.toJson($ctx.result.data)
@yuth I did respond 😉
janhesters
on 21 Mar 2019
@mikeparisstuff I attached the $util.appendError($util.toJson($ctx.result.data)) command and it says in it's message:
// There is no strikethrought for code, but please ignore this...
{
"path": [
"batchAddTodos"
],
"data": null,
"errorType": null,
"errorInfo": null,
"locations": [
{
"line": 40,
"column": 3,
"sourceName": null
}
],
"message": "{\"TodoTable\":[null]}"
},
Update: Okay, thanks to your debugging, I got rid of the type mismatch error. The mistake was writing:
$util.toJson($ctx.result.data)
Instead of
$util.toJson($ctx.result.data.TodoTable)
The only thing that's missing from this working now is the permission error.
janhesters
on 21 Mar 2019
@mikeparisstuff @yuth Okay, update / summary of the remaining issue.
I dug into the permissions. As I mentioned in an earlier comment, Todo.json in builds/stack/ includes
"Action": [
"dynamodb:BatchGetItem",
"dynamodb:BatchWriteItem",
"dynamodb:PutItem",
"dynamodb:DeleteItem",
"dynamodb:GetItem",
"dynamodb:Scan",
"dynamodb:Query",
"dynamodb:UpdateItem"
],
as well as:
"AssumeRolePolicyDocument": {
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "appsync.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
},
The error message claims that Todo-role-dqxfzxnspvd3pf5facjmlgtsui-batch does not have access to dynamodb:BatchWriteItem (The strings changed from my initial issue, because in the mean time I ran amplify remove api and amplify add api just to see if "turning it off and back on" works):
arn:aws:sts::655817346595:assumed-role/Todo-role-dqxfzxnspvd3pf5facjmlgtsui-batch/APPSYNC_ASSUME_ROLE is not authorized to perform: dynamodb:BatchWriteItem on resource: arn:aws:dynamodb:eu-central-1:655817346595:table/TodoTable
But, if I manually navigate to the role throuht IAM I see that the role DOES have these permissions. It also has appsync as a trusted entity.
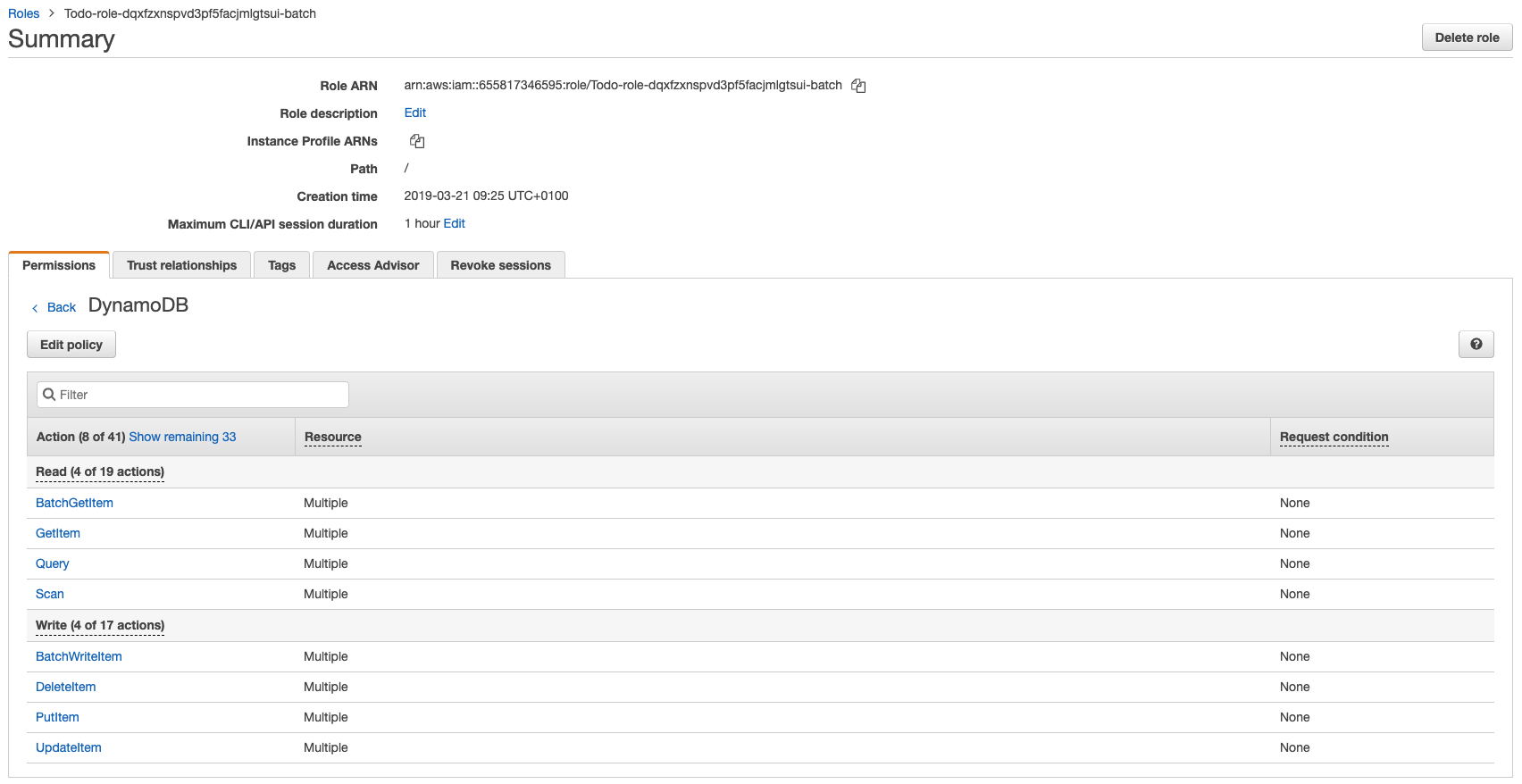

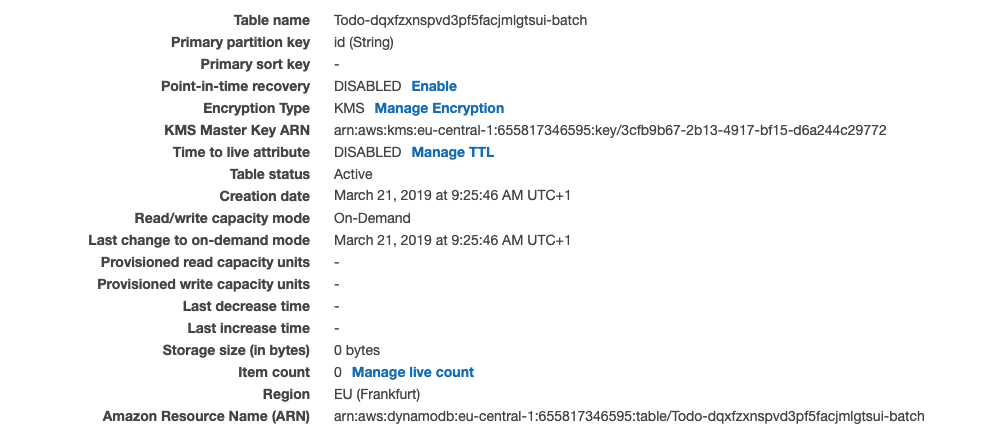
Is it because the table name is Todo-dqxfzxnspvd3pf5facjmlgtsui-batch instead of TodoTable?
Other than that, I have no idea right now, why the permission is still denied 🤷♂️
janhesters
on 21 Mar 2019
@mikeparisstuff @yuth Update #2 The cause WAS the table name 🤦♂️
My follow up questions would now be:
- Are the resolvers okay the way I wrote them? Meaning with the "table" value in the batch request. I simply followed this tutorial from the AppSync docs.
- If that is okay and it is in fact the best way to do this, isn't exposing the table name like that potentially dangerous in production?
- Lastly, is there a way change the name of the table?
Thank you guys for your help 🙏🏻
janhesters
on 21 Mar 2019
@janhesters Ah that makes sense! Glad you go this working. The reason for the table name in there is that batch operations can technically operate on multiple tables as long as your data source role is configured to allow it. I will make a note of this because its worth thinking about whether we could pass info through the resolver context that would allow you to prevent hard coding the table name.
mikeparisstuff
on 21 Mar 2019
@mikeparisstuff Thank you! 👍 👌 And sorry for the walls of texts and comments. As you can see I was working for two days on this 😅
But judging from you closing comment, the answers to my questions are
- This is the right way.
- There is no danger involved.
- There is no way to change the way of the table through the Amplify CLI / the files generated by Amplify.
Is that correct?
janhesters
on 22 Mar 2019
@mikeparisstuff PS: If you solved it so that you don't have to hardcode the value, that would be great. Just stumbled upon a problem when using multiple environments with different tables.
janhesters
on 22 Mar 2019
facing the same issue. Why do we need to hard code table names?
 nagad814
on 23 Mar 2019
nagad814
on 23 Mar 2019
I managed to come up with a decent solution for this issue using a pipeline resolver. You can substitute in one or more table names into the initial request template in cloudformation and then do all the heavy lifting in file based templates like the other resolvers. Here's a code example that assumes you have a model named 'Item':
Cloudformation:
"Resources": {
"CreateBatchItemsFunction": {
"Type": "AWS::AppSync::FunctionConfiguration",
"Properties": {
"ApiId": {
"Ref": "AppSyncApiId"
},
"Name": {
"Fn::Join": [
"_",
[
"CreateBatchItems",
{
"Ref": "AppSyncApiId"
}
]
]
},
"DataSourceName": {
"Fn::ImportValue": {
"Fn::Join": [
":",
[
{
"Ref": "AppSyncApiId"
},
"GetAtt",
"ItemDataSource",
"Name"
]
]
}
},
"FunctionVersion": "2018-05-29",
"RequestMappingTemplateS3Location": {
"Fn::Sub": [
"s3://${S3DeploymentBucket}/${S3DeploymentRootKey}/resolvers/Mutation.createBatchItems.req.vtl",
{
"S3DeploymentBucket": {
"Ref": "S3DeploymentBucket"
},
"S3DeploymentRootKey": {
"Ref": "S3DeploymentRootKey"
}
}
]
},
"ResponseMappingTemplateS3Location": {
"Fn::Sub": [
"s3://${S3DeploymentBucket}/${S3DeploymentRootKey}/resolvers/Mutation.createBatchItems.res.vtl",
{
"S3DeploymentBucket": {
"Ref": "S3DeploymentBucket"
},
"S3DeploymentRootKey": {
"Ref": "S3DeploymentRootKey"
}
}
]
}
}
},
"CreateDealsWithSeriesResolver": {
"Type": "AWS::AppSync::Resolver",
"Properties": {
"ApiId": {
"Ref": "AppSyncApiId"
},
"TypeName": "Mutation",
"FieldName": "createBatchItems",
"Kind": "PIPELINE",
"PipelineConfig": {
"Functions": [
{
"Fn::GetAtt": ["CreateBatchItemsFunction", "FunctionId"]
}
]
},
"RequestMappingTemplate": {
"Fn::Join": [
"\n",
[
{
"Fn::Sub": [
"$util.qr($ctx.stash.put(\"itemTableName\", \"${itemTableName}\"))",
{
"itemTableName": {
"Fn::If": [
"HasEnvironmentParameter",
{
"Fn::Join": [
"-",
[
"Item",
{
"Ref": "AppSyncApiId"
},
{
"Ref": "env"
}
]
]
},
{
"Fn::Join": [
"-",
[
"Item",
{
"Ref": "AppSyncApiId"
}
]
]
}
]
}
}
]
},
"{}"
]
]
},
"ResponseMappingTemplate": "$util.toJson($ctx.result)"
}
}
}
Request template example (resolvers/Mutation.createBatchItems.req.vtl):
#set($itemsData = [])
#foreach($item in ${ctx.args.items})
$util.qr($item.put("createdAt", $util.time.nowISO8601()))
$util.qr($item.put("updatedAt", $util.time.nowISO8601()))
$util.qr($item.put("__typename", "Item"))
$util.qr($item.put("id", $util.defaultIfNullOrBlank($item.id, $util.autoId())))
$util.qr($itemsData.add($util.dynamodb.toMapValues($item)))
#end
{
"version": "2018-05-29",
"operation": "BatchPutItem",
"tables": {
"$ctx.stash.itemTableName": $utils.toJson($itemsData)
}
}
Response template example (resolvers/Mutation.createBatchItems.res.vtl):
#if($ctx.error)
$utils.error($ctx.error.message, $ctx.error.message)
#end
$util.toJson($ctx.result.data.get($ctx.stash.itemTableName))
The key part is having an inline template for the pipeline resolver's request template and using Fn::Sub to set the table name from cloudformation into the $context.stash object which is available in the rest of the functions in the pipeline.
The steps needed to get the table name in cloudformation are pretty verbose. I think we should lobby for having the table name exported from each model's stack.
 mhodgson
on 26 Mar 2019
mhodgson
on 26 Mar 2019
@mhodgson This looks neat, thank you for sharing 🤗
I think we should lobby for having the table name exported from each model's stack.
+1 - I feel like both making custom resolvers easier to learn & write and having the CLI be able to generate more common use cases (batch create, batch update & batch delete, counting objects in the database, lamda functions for third party validation such as with Stripe, etc.) would help AWS Amplify snowball.
janhesters
on 26 Mar 2019
@janhesters FYI: https://github.com/aws-amplify/amplify-cli/issues/1145
mhodgson
on 29 Mar 2019
@mhodgson @janhesters AWS should hire all of us and make Amplify the snowball :D
 babu-upcomer
on 30 Jul 2019
babu-upcomer
on 30 Jul 2019
@babu-upcomer @mhodgson @janhesters In all seriousness, if you are interested in connecting more let me know :)
mikeparisstuff
on 31 Jul 2019
@mikeparisstuff I'm interested 😊I followed you on Twitter, so we can DM.
janhesters
on 31 Jul 2019
@mhodgson I'm getting Reason: No data source found named for the table name though the table exists with the exact name in the DynamoDB console. Does it ring any bell to you? Would be helpful to share if you had faced any issues like that and fixed along the way.
babu-upcomer
on 1 Aug 2019
@mikeparisstuff Do you know if this solved already? Is the solution by @mhodgson still applicable?
babu-upcomer
on 1 Aug 2019
This solution looks complicated is there a easier way to do batch updates or creates then to writing a customer resolver for every batch mutation seems a bit of over kill to me for one operation
 2advancesolutions
on 9 Oct 2019
2advancesolutions
on 9 Oct 2019
@2advancesolutions We have solved this by @function directive. Simply deploy a function implemented in your favourite language and use it's AWS SDK to connect to resources. This way you can write your business logic with more flexibility. We were able to solve our batch mutations easily using serverless lambda functions with Python37 and boto3 package.
In-fact my recommendation after all my experience with amplify is to go for function for all create mutations. In addition to the batching you can also implement your business logic validations very easily. I also use sentry for error reporting.
Update: Amplify will give you an impression that it greatly depends on the .vtl templates for CRUD operations. But never get misguided by the auto generated templates. For complex read and write operations function is the easy way out. Before using the function we were using DynamoDB streams to chain operations but we didn't see the consistency throughout at-least with our kind of dateset.
babu-upcomer
on 9 Oct 2019
@babu-upcomer Thank you for sharing your experience on using amplify properly, but aws team needs to add this to there documentation since this something common you do in your everyday development.
2advancesolutions
on 9 Oct 2019
In-fact my recommendation after all my experience with amplify is to go for function for all create mutations. In addition to the batching you can also implement your business logic validations very easily.
Isn't this the purpose of appsync to spare developers from the need of rolling their own API handlers for general use cases? I would personally go with having logic in VTL templates when logic is not complex. I would say many general use cases like batch update demonstrated above deserves to be done on appsync side. At this stage, I feel like for me personally, this seems like the most reasonable sequence:
- write custom resolvers with logic in VTL templates if I can understand it at a glace.
- if custom resolvers logic repeats, pack the custom resolvers and cloudformation templates into custom transformer and then use instead of 1 after https://github.com/aws-amplify/amplify-cli/pull/1396 lands.
- use lambdas for complex logic (which is often case specific and doesn't really to be generalized) and triggers.
@babu-upcomer: what do you think?
 ambientlight
on 11 Oct 2019
ambientlight
on 11 Oct 2019
@mhodgson Are you able to mock your API with your solution? https://github.com/aws-amplify/amplify-cli/issues/1079#issuecomment-476413201
 askurat
on 13 Oct 2020
askurat
on 13 Oct 2020
Related issues
 jexh
·
3Comments
jexh
·
3Comments
 amlcodes
·
3Comments
amlcodes
·
3Comments
 nicksmithr
·
3Comments
nicksmithr
·
3Comments
 gabriel-wilkes
·
3Comments
gabriel-wilkes
·
3Comments
 mwarger
·
3Comments
mwarger
·
3Comments
Most helpful comment
I managed to come up with a decent solution for this issue using a pipeline resolver. You can substitute in one or more table names into the initial request template in cloudformation and then do all the heavy lifting in file based templates like the other resolvers. Here's a code example that assumes you have a model named 'Item':
Cloudformation:
Request template example (
resolvers/Mutation.createBatchItems.req.vtl):Response template example (
resolvers/Mutation.createBatchItems.res.vtl):The key part is having an inline template for the pipeline resolver's request template and using
Fn::Subto set the table name from cloudformation into the$context.stashobject which is available in the rest of the functions in the pipeline.The steps needed to get the table name in cloudformation are pretty verbose. I think we should lobby for having the table name exported from each model's stack.