Almanac.httparchive.org: SEO 2020
Part II Chapter 7: SEO
Content team
| Authors | Reviewers | Analysts | Draft | Queries | Results |
| ------- | --------- | -------- | ----- | ------- | ------- |
| @aleyda @ipullrank @fellowhuman1101 | @clarkeclark @natedame @catalinred @aysunakarsu @ashleyish @dsottimano @dwsmart @en3r0 @Gathea @rachellcostello @ibnesayeed | @max-ostapenko @Tiggerito @antoineeripret | Doc | *.sql | Sheet |
Content team lead: @aleyda
Welcome chapter contributors! You'll be using this issue throughout the chapter lifecycle to coordinate on the content planning, analysis, and writing stages.
The content team is made up of the following contributors:
New contributors: If you're interested in joining the content team for this chapter, just leave a comment below and the content team lead will loop you in.
_Note: To ensure that you get notifications when tagged, you must be "watching" this repository._
Milestones
0. Form the content team
- [x] Jul 6th: Project owners have selected an author to be the content team lead
- [x] Jul 13th: The content team has at least one author, reviewer, and analyst (minimally viable team formed)
1. Plan content
- [x] Jul 20th: The content team has completed the chapter outline in the draft doc
- [x] Jul 27th: Analysts have triaged the feasibility of all proposed metrics
2. Gather data
- [x] Jul 27th: Analysts have added all necessary custom metrics and drafted a PR to track query progress
- Aug 1 - 31: August crawl
- [x] Sep 7th: Analysts have queried all metrics and saved the output to the results sheet
3. Validate results
- [x] Sep 14th: The content team has reviewed the results sheet
4. Draft content
- [x] Nov 12th: Authors have completed the first draft in the doc
- [x] Nov 26th: The content team has prototyped all data visualizations
5. Publication
- [ ] Nov 26th: The content team has reviewed the final draft, converted to markdown, and filed a PR to add it to the 2020 content directory
- Dec 9th: Target launch date
 obto
obto
All 208 comments
Sounds great :) Count me in!
 aleyda
on 27 Jun 2020
aleyda
on 27 Jun 2020
I'd like to nominate Nate Dame as well.
Really looking forward to how this chapter turns out with how much enthusiasm there is for it 😄
obto
on 29 Jun 2020
I'd like to participate as an analyst in this chapter.
 max-ostapenko
on 29 Jun 2020
max-ostapenko
on 29 Jun 2020
I'm happy to be a reviewer again this year for the SEO chapter.
 clarkeclark
on 30 Jun 2020
clarkeclark
on 30 Jun 2020
I'd love to join! Since this would be my first year I'd like to be a reviewer if possible.
 natedame
on 30 Jun 2020
natedame
on 30 Jun 2020
I'd love to help in any way.
 catalinred
on 30 Jun 2020
catalinred
on 30 Jun 2020
I'd still like to help - but, there are quite a few participants.
I'd like to gently recommend that folks make room for anyone that is underrepresented or new to putting themselves out there.
Though it'd be good to find at least a balance in gender, I'm good to give my spot up to anyone that is new to the scene. Or act as mentor. <3
 ashleyish
on 1 Jul 2020
ashleyish
on 1 Jul 2020
Still happy to help as I was when @AVGP kindly nominated over on the other thread, but hyper conscious I think the team should be a diverse one, so happy to bow out to help that happen
 dwsmart
on 1 Jul 2020
dwsmart
on 1 Jul 2020
Thank you @ashleyish and @dwsmart! I love to see it.
@obto and I will be reaching out to our picks for the content team lead for each chapter, and once that person is confirmed for SEO they can choose their coauthor(s) as needed. SEO is an especially complex topic so I would expect this to have ~3 coauthors like last year. And for anyone else still interested in contributing, there is no limit on the number of technical reviewers so we'd welcome your help!
@catalinred were you interested in contributing as a reviewer or analyst?
 rviscomi
on 1 Jul 2020
rviscomi
on 1 Jul 2020
@catalinred were you interested in contributing as a reviewer or analyst?
@rviscomi I don't have the right skills for analyst so I was thinking about contributing as a reviewer maybe.
But I am happy to take a step back and looking forward to seeing the content team lead pick.
catalinred
on 1 Jul 2020
Ok I've added you as a reviewer for now and you can reevaluate as needed.
rviscomi
on 1 Jul 2020
I will be happy to contribute.
 aysunakarsu
on 2 Jul 2020
aysunakarsu
on 2 Jul 2020
I'd be happy to help. I work in technical SEO and I've made a few BigQuery/archive queries to extract data from pages. Then ran out of money! Example.

 Tiggerito
on 3 Jul 2020
Tiggerito
on 3 Jul 2020
Happy to contribute as per the nomination on the main post but equally happy to act as a mentor as @ashleyish suggested and find a few new faces.
 dsottimano
on 3 Jul 2020
dsottimano
on 3 Jul 2020
@aleyda thank you for agreeing to be the lead author for the SEO chapter! As the lead, you'll be responsible for driving the content planning and writing phases in collaboration with your content team, which will consist of yourself as lead, any coauthors you choose as needed, peer reviewers, and data analysts.
The immediate next steps for this chapter are:
- Establish the rest of your content team. Several other people were interested or nominated (see below), so that's a great place to start. The larger the scope of the chapter, the more people you'll want to have on board.
- Start sketching out ideas in your draft doc.
- Catch up on last year's chapter and the project methodology to get a sense for what's possible.
There's a ton of info in the top comment, so check that out and feel free to ping myself or @rviscomi with any questions!
@en3r0 @ipullrank we'd still love to have you contribute as a peer reviewer or coauthor as needed. Let us know if you're still interested!
@aysunakarsu @ashleyish @dsottimano @dwsmart @natedame I've put you down as reviewers for now, and will leave it to @aleyda to reassign at their discretion
obto
on 3 Jul 2020
@Tiggerito would you like to contribute as an analyst for the chapter?
obto
on 3 Jul 2020
@Tiggerito would you like to contribute as an analyst for the chapter?
Happy to do that.
Tiggerito
on 3 Jul 2020
I can contribute as an analyst too if there is still need at that part. Thanks.
aysunakarsu
on 3 Jul 2020
I'd be happy to help as an analyst. If there is enough analysts for this chapter, happy to help with another one as well :)
 antoineeripret
on 3 Jul 2020
antoineeripret
on 3 Jul 2020
Thank you @obto ! Excited to be able to contribute as the lead author :) I'll catch up going through last year edition again and the methodology used.
I definitely think that due to the scope of the chapter it would be great to have a couple of more authors and a couple of more analysts, like this we can have 3 authors (as last year), 3-4 reviewers, 3-4 analysts.
@aysunakarsu @ashleyish @dsottimano @dwsmart @natedame Hello everybody! Very looking forward to contribute together :) I see some of you had expressed interest on contributing as analysts instead of reviewers... please let me know below if you would still like to contribute as analysts or if you prefer the writing side of things, the possibility to contribute as authors instead too.
@ipullrank Would love to have you as a co-author!
aleyda
on 3 Jul 2020
@aleyda I'm in!
 ipullrank
on 3 Jul 2020
ipullrank
on 3 Jul 2020
@aleyda happy to contribute as a peer reviewer or coauthor as needed!
 en3r0
on 3 Jul 2020
en3r0
on 3 Jul 2020
I would be happy to to be a reviewer if possible ! It’s the first year for me
 Gathea
on 4 Jul 2020
Gathea
on 4 Jul 2020
@aleyda I've sent you an invite to join the 2020 Authors team on GitHub. Can you visit https://github.com/HTTPArchive/ to accept the invite? This will ensure you get notifications about important chapter milestones.
rviscomi
on 8 Jul 2020
@rviscomi thank you! I just accepted :)
aleyda
on 8 Jul 2020
Hey @aleyda, just checking in:
- How is the the chapter coming along? We're tying to have the outline and metrics settled on by the end of the week so we have time to configure the Web Crawler to track everything you need.
- Can you remind your team to properly add and credit themselves in your chapter's Google Doc?
- Anything you need from me to keep things moving forward?
obto
on 13 Jul 2020
Thanks for the follow-up @obto ! I'll make sure the outline are completed by the end of the week :) The metrics are also expected this week or by July 27? Can you please confirm to coordinate/prioritize accordingly?
Also, I just requested access to the document. Could you please give access to the rest of the team or do you prefer that I give it to them? Just let me know the best way to proceed.
@ipullrank Let's start with the outline :) I'll try to leave a first draft ready today, max tomorrow - I'll be following up in the following hours!
@aysunakarsu @ashleyish @dsottimano @dwsmart @natedame Hi everybody, this is a reminder that I'm waiting for your answer on my question above: In case you want to be an analyst instead of a reviewer, so you can also be added as such in the Google Docs too... and we can start with the initial tasks :) Looking forward to collaborate together!
At this moment:
@clarkeclark @natedame @catalinred @aysunakarsu @ashleyish @dsottimano @dwsmart @en3r0 @Gathea - are reviewers.
@max-ostapenko @Tiggerito are analysts.
As next steps:
Next couple of days: Authors (@ipullrank & yours truly) will leave the outline ready by Thursday 16 and proposed metrics. (Specified deadline: July 20)
On Thursday: I'll ping the confirmed reviewers so you can verify if there's something additional/different that could be added/changed from the outline. This should be a fast validation, so we can leave a couple of days for it.
On Monday: I will ping all the confirmed analysts so you can start verifying the feasibility of the metrics, proposed better/different ones. (Specified deadline: July 27)
Thanks again :)
aleyda
on 14 Jul 2020
I think @fellowhuman1101 would also be up to help here! 🙌
 AVGP
on 14 Jul 2020
AVGP
on 14 Jul 2020
Amazing! Thanks @AVGP :) @fellowhuman1101 I look forward to your confirmation! Do you want to be a co-author, reviewer, analyst? Just let me know! Would love to have you too! ❤️
aleyda
on 14 Jul 2020
Hello @AVGP
I was actually thinking about your angle of things. You know we can run JavaScript to get data, so do you have any insights on things to test?
Canonicals/robots meta changed via JS?
One idea I had was to see how much Structured Data was being added/changed/removed via JavaScript.
This is currently based on a theory that I can create a query to compare raw html with rendered. Joining two 20TB datasets may break the bank!
Downside to all this is, I found out we can only analyse home pages :-(
Tiggerito
on 14 Jul 2020
Hey @aleyda, I'm happy with the reviewer role, I'm not massively familiar with the dataset, but more than happy to jump over to that side if there's a shortage and I can be helpful.
dwsmart
on 14 Jul 2020
@aleyda
The metrics are also expected this week?
Yes we need the list of metrics you'd like us to research by the end of this week. This is because we need time to configure the Web Crawler which starts on August 1st, and give your analysts time to look over the metrics and make any necessary adjustments together with you
Could you please give access to the rest of the team or do you prefer that I give it to them?
If you have the emails of everyone on your team, please do invite them! Otherwise, please do have them request access themselves :)
obto
on 14 Jul 2020
Thanks for your confirmation @dwsmart , no problem at all :) it will be awesome to have you as a reviewer!
@obto thanks for the clarification, got it :) I'll make sure to have it end of week.
aleyda
on 14 Jul 2020
@aleyda reporting for duty!
 fellowhuman1101
on 14 Jul 2020
fellowhuman1101
on 14 Jul 2020
@aleyda also reporting (again?) for duty! :) In response to your question, I don't think my skillset would make a good analyst. Happy to review when the time comes!
natedame
on 15 Jul 2020
So I'm incredibly late to the 2020 Web Almanac party and am just catching up on everything _(don't link GitHub to your work email and then change jobs...)_ but it looks like you've pulled together an excellent team for this year's SEO chapter!!
I've offered to be an editor this time round, but as one of last year's SEO chapter co-authors, if there's anything I can do to help then let me know @aleyda :)
Looks like you've got a bunch of people on board already though, so if I'm not needed then I can't wait to read it when it's finished!
 rachellcostello
on 15 Jul 2020
rachellcostello
on 15 Jul 2020
Amazing @fellowhuman1101 - added you as a co-author!
@natedame - perfect :) You stay then as a reviewer!
@rachellcostello - Amazing, it's great to have you Rachel! Adding you as a reviewer then :)
aleyda
on 15 Jul 2020
I've been trying to get my head around the data available to us. This is my summary:
The data source is based on the mobile and desktop home pages for over 5 million domains sourced from Crux. The data is acquired monthly and includes:
- Requests (requests_*, json format, request url, headers, response status, headers timings)
- Summary Requests (summary_requests_*, table format summary of the Requests data)
- Pages (pages_*, json format, page processing timings)
- Summary Pages (summary_pages_*, table format of Pages including timings, resource sizes, cdn, adult site...)
- Bodies (response_bodies_*, content of home pages, regex searchable)
- Rendered Content Info (almanac.js, injected javascript to gather information)
- Lighthouse (lighthouse_*, json based, can do json queries)
- Technologies (technologies_*, cms, programing language, server….)
Historical monthly data is also available.
Edit: Chrome-UX data is also available including all the Web Vitals
Tiggerito
on 16 Jul 2020
Thanks for starting verifying the available data to validate also the viable metrics @Tiggerito, this is great !
I have a question regarding the rendered content info: Would it be possible to verify for example the content relying on client side JS to be rendered? I have been revising what was included in last year chapter to define this year outline (in progress here), and I don't see that information included, but it would be great to have!
aleyda
on 16 Jul 2020
Hi @aleyda,
I'm not sure when the almanac.js script is run. If it's late in the rendering process we should be able to pick up client side rendered info. I'll ask around.
Tiggerito
on 16 Jul 2020
@Tiggerito Thank you! :)
aleyda
on 16 Jul 2020
@Tiggerito Sounds like you've got a pretty good grasp on things! @bazzadp just made a post with some extra information you might find helpful as well https://github.com/HTTPArchive/almanac.httparchive.org/issues/914#issuecomment-659205330
And don't forget to join the #web-almanac slack so @paulcalvano can invite you to the Analysts channel where you can ask any questions you may have.
Edit: Looks like you've already joined! :tada:
obto
on 16 Jul 2020
I've done some reverse engineering of all last years queries and made some basic notes.
SQL
10_01 - pulls almanac.js for structured data, counts if contains a type from the Google Gallery. Reports percent containing split by device. * list probably needs updating
10_02 - reports on lang values used from body * only pulls first 2 characters
10_03 - pulls almanac.js link tags for amphtml and reports percent. e.g. percent of home pages using amp
10_04a - hreflang use percent by device
10_04b - popular hreflang values by device
10_05 - pulls almanac.js to report schema types used by device
10_06 - lighthouse mobile data for is crawlable and is canonical. * is crawlable also seems to check robots meta tag noindex!
10_07a - lighthouse mobile data on title and meta description presence
10_07b - title lengths based on percentiles by device 10, 25, 50, 75, 90 good example of how to do quantiles/percentiles
10_07c - meta description lengths based on percentiles by device. data aquired from almanac.js
10_08 - status codes by percent
10_09a - words and heading word counts by percentile from almanac.js
10_09b - lighthouse mobile image alt percent score of 1 (all are set)
10_10 - percentiles for external, internal and anchor links from almanac.js
10_11 - SPAs ('React', 'Angular', 'Vue.js') using navigational hash links from almanac.js * example of a JOIN with the technologies table
10_12 - lighthouse mobile robots.txt with no validation errors
10_13 - % of desktop pages that include a stylesheet with a breakpoint under 600px. usses parsed_css table
10_14 - lighthouse mobile data percent link-text score is 1. It means no failing links which are links using block words like "more info"
10_15a - % of websites classified as fast/avg/slow ** from the chrome-ux-report - has our Web Vital Scores :-)
10_15b - % of websites classified as fast/avg/slow by device (form factor)
10_16 - h1 length by percentile and device
10_17 - percent https by device
10_18 - percent without headers or even words, by device
10_19 - no external, external, hash links, by device
almanac.js
looks for json-ld and microdata. Returns an object listing all types found. Goes 5 levels in for json-ld
count of links: external, internal (same hostname), hash/navigateHash/earlyHash (same page with #, navigate if no jump to anchor, early = first 2)
h1 to h4 count and total word count
word count from all text nodes in body
meta tags
link tags
Tiggerito
on 17 Jul 2020
Hi @aleyda, I've just done some testing. The JavaScript we can run is processed via webpagetest.org and they state the script is run after the normal test has finished. The tool does a long test which make me think we have quite a reliably rendered DOM to work with.
On my own test it picked up Structured Data added via JavaScript as well as iframes added by Disqus.
I think we need to get things added to the script by the end of the month so the extra data is extracted when they crawl.
Tiggerito
on 17 Jul 2020
Hi @aleyda @Tiggerito
For eCommerce chapter 2020, I was considering to pull a custom metric to find out how many social channels sites are using on average and publishing this information via Schema.org. I was planning to do this using a custom metric (Thanks to @savsav)
[numberOfSocialChannels]
let seoScripts = Array.from(document.querySelectorAll('script[type = "application/ld+json"]'))
.map(script => JSON.parse(script.innerText))
.filter(obj => obj.hasOwnProperty("sameAs"));
if (seoScripts.length == 0) {
return;
}
return seoScripts[0].sameAs.length;
Example usage from https://direct.asda.com/george/clothing/10,default,sc.html
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Organization",
"name" : "GeorgeAtAsda",
"url": "https://direct.asda.com",
"logo": "https://direct.asda.com/on/demandware.static/-/Library-Sites-ASDAShared/default/dw4998f70c/logos/grg_header_logo_comp.jpg",
"contactPoint" : [{
"@type" : "ContactPoint",
"telephone" : "+44-800-952-0101",
"contactType" : "customer service"
}],
"sameAs" : [
"https://www.facebook.com/GeorgeatAsdaOfficial",
"https://uk.pinterest.com/georgeatasda/",
"https://twitter.com/Georgeatasda",
"https://instagram.com/georgeatasda",
"https://www.youtube.com/user/georgedressforless"
]
}
Here is a test - https://www.webpagetest.org/result/200717_3J_d1226f7d51175b862b866aa12f2b85ca/1/details/#waterfall_view_step1
But I think it will be better to add this as generic information in SEO chapter also and may be I can reference eCommerce specific stats in eCommerce chapter. What do you think?
We may need to tweak the code to cover few more use cases.
@rviscomi @jrharalson @drewzboto @loewengart
 rockeynebhwani
on 17 Jul 2020
rockeynebhwani
on 17 Jul 2020
Hi @max-ostapenko :) I wanted to get in touch since we're already leaving the outline ready and start specifying the expected metrics in the chapter's Google Docs here, @Tiggerito is already in there checking what we're adding and we're assessing with them already the viability of the metrics for the sections we're adding, and it would be great if you can also participate in the process as an analyst too. What's the best email to add you as a Google Doc editor too? Just let me know to add you so you can also participate in the process.
Thanks!
aleyda
on 17 Jul 2020
Hi @rockeynebhwani, Thanks for getting in touch!
We're adding a Structured Data sub-section in the chapter under the content area, the goal so far is to specify:
- The Format used (microdata, json-ld, microformat)
- The types used (Organization, Breadcrumb, FAQ, How-To, etc.)
- The usage of JS to implement structured data
To confirm: You're particularly interested to provide the information of social presence information via the Organization Schema right? If so I don't think there should be an issue digging further to obtain the usage of specific properties ... it would be great if @Tiggerito or @max-ostapenko could confirm.
On the other hand, from a scope perspective, it would be to see with @fellowhuman1101 and @ipullrank how far we want to go regarding providing info on specific properties used across the different Schema types ... as there are so many of them. Last year in the SEO chapter Structured Data section here, the information provided was the information about the most used structured data types, highlighting those that have a more prominent impact in search results. So on that regard the "social presence" specification might not necessarily be one of the top ones... but let's see what they think too :)
aleyda
on 17 Jul 2020
@aleyda - Thanks for your thoughts. I believe Google uses this section to build knowledge graph. You can see in below screenshot and hence I thought it will be relevant for SEO chapter and this can easily be gathered from HomePage

rockeynebhwani
on 17 Jul 2020
@aleyda - Another interesting structured data which we can surface and it's used by Google to show search box next to result.. (For this, we will have to look for potentialAction with type 'SearchAction'.. See example below)


Not sure adoption of this on certain platform like Shopfiy etc. If platforms have this as out of the box feature, we will possibly see higher adoption ..
rockeynebhwani
on 17 Jul 2020
Hi @rockeynebhwani, in the past that structured data information regarding the social presence was taken into consideration for the knowledge panel of a business, but not anymore -at least not directly-, and Google updated their guidelines/specification for it, now it takes into consideration the logo but for the social presence the process is for the business to claim their presence in the Knowledge Panel and updating the information, as specified here: https://developers.google.com/search/docs/guides/enhance-site
Then about the "search action" yes, that's is something that was added last year and I expect we continue adding too, due to its visibility/impact.
So on one hand: we will definitely make sure to add general structured data information and then on the other, highlight further those that trigger prominent search features that from our experience has a higher impact: FAQ, How-Tos, Reviews, etc. although we will need to see up to which point again we want to specify every single one... but I also think we won't know for sure until we write that section and agree/validate between authors though.. I think that maybe the best way to move forward here is that we make sure to collect all the structured data information as much as it is available, and then, once we write this SD section for SEO you see what we're highlighting further based on their search importance, and if you think you would like to expand/dig further something that could be potentially more important from an ecommerce perspective that we're not covering as much due to our different scope, you can include it in the ecommerce chapter? I'm trying to see the best way to coordinate, leave it as much open at this still very early stage where we are and then also, that we don't lack the data in case you need it (and we don't).
Thanks again :)
aleyda
on 17 Jul 2020
@rockeynebhwani btw, I actually think we should be good already and didn't realized when writing my previous response somehow (!!) :D Based on what you were asking: We expect to collect all structured data following info...
- All The Format used and their split (microdata, json-ld, microformat)
- All The types used (Organization, Breadcrumb, FAQ, How-To, etc.)
- The usage of JS to implement structured data
So, we expect to gather all this information on one hand (which at this point is the most important aspect).
Then another matter is if we decide to highlight something further or not (we definitely want to give an overview of all) in the SEO chapter due to its Search prominence (that we will decide later on in the process) and we can share with you when we are at that point of the writing process, and if you see is not enough from an ecommerce perspective, and you would like to show something more/different, then you will still have the data to access and feature it in the ecommerce chapter? :) I think this will be the easiest process.
Thanks again!
aleyda
on 17 Jul 2020
sounds good @aleyda .. @rviscomi pointed me to https://github.com/HTTPArchive/almanac.httparchive.org/blob/main/sql/2019/10_SEO/10_05.sql
Most likely, this data is already being gathered. Should be matter of just querying
rockeynebhwani
on 17 Jul 2020
Amazing! That's great to know. Thanks @rockeynebhwani :)
aleyda
on 17 Jul 2020
Correction. I did a run with all almanac custom metric but this information about social channels is not being gathered currently. Sample run (Look for '10.5') - https://www.webpagetest.org/custom_metrics.php?test=200717_WK_030e8ad4e4b08550d361cd871b9db617&run=1&cached=0
It will be good if somebody in team here can pick PR to almanac.js (https://github.com/HTTPArchive/legacy.httparchive.org/blob/master/custom_metrics/almanac.js) to add this custom metric
rockeynebhwani
on 17 Jul 2020
@rockeynebhwani @aleyda
A good idea to collaborate on this.
I agree that sameAs was dropped by Google so less significant now.
searchAction is still supported and I think the SD is used a lot. However, to get a search box is independent to adding the markup and very few sites get them. The markup is there to tell Google how to directly use the sites internal search system. A thought I had was to verify that the searchAction matches how the sites search actually works, but that may be difficult.
Logo is also a limited value markup, only used if the site has a knowledge panel entry.
Something important to mention is this analysis is on home pages only. Which is very limiting with SD as most types are only of value on internal pages (Product, Review, Recipe etc). Outside the above features you will likely never see a rich result on a home page. So if we do detect other entity types, it's probably a mistake, of no value, or an attempt to manipulate the system. Currently we use JS to identify all entity types present on a page (no properties yet, just the types used) and there is a report that checks that list against the ones used in the Google Gallery.
I agree that reporting on the different formats and maybe vocabularies used would be of value. I also think I can determine if SD was added via JavaScript (or that it changed).
I could probably pull out some specifics from the SD, like the search action URL and the logo. That could be used to verify things. I.e. is the logo on the page.
Tiggerito
on 18 Jul 2020
I see that this is a chapter with a handful of reviewers already, but crawlability of a site is an indicator of its archivability (which is my field of expertise), so I would be interested in reviewing this.
 ibnesayeed
on 18 Jul 2020
ibnesayeed
on 18 Jul 2020
A quick suggestion, this chapter may also want to analyze soft-404s, which are an indication of poor application design and may hurt SEO. These can be hilarious at times.
ibnesayeed
on 18 Jul 2020
A quick suggestion, this chapter may also want to analyze soft-404s, which are an indication of poor application design and may hurt SEO. These can be hilarious at times.
I like the idea. Unfortunately we can only analyse home pages which are probably not candidates for soft 404 status.
It would be interesting to know how we could determine if a page may be classed as a soft 404? Google probably uses a few signals like heading, lack of content and redirects to work them out.
Tiggerito
on 18 Jul 2020
It would be interesting to know how we could determine if a page may be classed as a soft 404? Google probably uses a few signals like heading, lack of content and redirects to work them out.
In the web science community there are two very well known approaches to identify soft-404s and both have their pros and cons:
- Train a simple text-based classifier using page title and body text (all the markup removed, and ideally boilerplate template removed as well) from legitimate 200 and 404 pages as training sets and then use it to classify unknown 200 responses. This relies of the idea that there will be some common phrases in the main content area that will suggest that the item/page/resource/product is not available.
- Pro: Works offline on crawled datasets without many any extra requests to the live site.
- Con: Needs annotated gold data set for training in each language.
- Nudge the last segment (usually the last path segment, but in some cases it can be a query parameter as well) of a URL and make another request to the new URL (e.g., if one wants to know whether
example.com/foo/baris a soft-404, make another request to something likeexample.com/foo/blah) to observe whether the two responses are exactly/almost the same, this would likely be a soft-404 or some other error page, even if the response is 200 in both the cases.
- Pro: Works across languages without any prior knowledge or classifier model.
- Con: Increases the number of requests made to a server, hence it is suitable for big-scale crawlers who are already checking many URLs of a site and can compare their contents.
Note: There are implementations available for both techniques and some tools that are built on the first technique already come with pre-trained model (but allow training new models) to work out of the box, especially on English language web pages. I once worked on a small project with people who archived pages in Arabic language and they wanted to classify soft-404s, but the training sets were not available and they were analyzing archived data, so the sites might not be available live to try the second approach. I suggested them to use machine translation on Arabic pages to translate them in English and then use classifier models built for English language. I am not aware of any research work done on this "translate then classify" approach for soft-404 detection, but I did not have enough time to explore that further and publish a paper if it was indeed a novel work.
ibnesayeed
on 18 Jul 2020
I like the idea. Unfortunately we can only analyse home pages which are probably not candidates for soft 404 status.
Yes, you are right, home pages are less likely to be soft-404s.
ibnesayeed
on 18 Jul 2020
That's me done for the day 🍷
I've created SQL to work out Core Web Vitals per device. This is actual data for last month. Should be simple to do one per country:

I've also been playing with processing the raw html. These are how many JSON_LD script tags are added (sample 10k data). The site with 50 is marking up every image in a separate script tag:

And you might like this. I managed to parse the JSON_LD scripts from the raw html to see if they were valid json. 6 failed. I was pleasantly surprised.

Many more ideas. Need to work on microdata etc. As well as gathering the same info from the rendered pages. Finally, a comparison of numbers between raw and rendered would be a good clue that they are altering SD via JS.
Tiggerito
on 18 Jul 2020
I see that this is a chapter with a handful of reviewers already, but crawlability of a site is an indicator of its archivability (which is my field of expertise), so I would be interested in reviewing this.
Hi @ibnesayeed , there are many already but I will definitely add you since in the "pings" I sent above to them asking if they wanted to keep as reviewers or switch to analyst many didn't answered at the end, so I'm a bit concern about the availability of all who had initially registered :D If at the end we see everybody answers and collaborates we can even split areas/topics, but if not, it would be great to have more available people! Thanks :)
aleyda
on 18 Jul 2020
@Tiggerito This is amazing! Regarding the Core Web Vitals: would it be possible also to add "tablet" as part of the devices or is it possible only to get it for mobile and desktop?
About the Json-LD parsing: This is great! We can then specify how many of the Websites implementing their SD with this method have "basic" script configuration issues.
and then: " a comparison of numbers between raw and rendered would be a good clue that they are altering SD via JS." - this would be amazing, and also very well worthy to do with meta robots and metadata configurations: the difference between the raw vs. rendered HTML!
aleyda
on 18 Jul 2020
I'd be happy to help as an analyst. If there is enough analysts for this chapter, happy to help with another one as well :)
Hi @antoineeripret - I just saw this message you had sent and I had overlooked (sorry) and hadn't replied. I think an additional analyst would be amazing since @Tiggerito has started going through the data and we're looking to have a data rich chapter (we already started to define the topics here) - let me know if you're still interested to be an analyst of the chapter and then I can add you too, so you can start also seeing the viability of the metrics connected with the topics we're proposing to include in the chapter with @Tiggerito :) Looking forward to your response - thanks again!
aleyda
on 18 Jul 2020
I can contribute as an analyst too if there is still need at that part. Thanks.
Hi @aysunakarsu ! Would you still available as an analyst too? Let me know and if so I will add you as one (instead of a reviewer) as I think we will need more people there and we have already many reviewers! @Tiggerito has started to go through the data of the chapter topics we're leaving specified here. Let me know please if you're still interested, and if so, your email to add you to the Google Docs to contribute too :) Thanks again!
aleyda
on 18 Jul 2020
@aysunakarsu @antoineeripret I'd love backup on this. I'm not an analyst, I just play one on TV.
Tiggerito
on 18 Jul 2020
@aysunakarsu @antoineeripret I'd love backup on this. I'm not an analyst, I just play one on TV.
@antoineeripret has just confirmed me directly, added him to Google Docs and our private conversation too! He'll be able to start digging in tomorrow :) Looking forward to @aysunakarsu response to see if she's interested and then @max-ostapenko who had confirmed already as an analysts to get him involved too! Thanks for all your effort, @Tiggerito :D
aleyda
on 18 Jul 2020
Hi @obto @rviscomi,
One question: When going through some of the information we want to show in the outline & metrics, like the percentage of sites implementing certain configurations with @Tiggerito , we saw that it could be useful to instead of sharing only the % of the total sites that are implementing something in X or Y way, in certain cases to provide a comparison of the usage with the top X / highest traffic sites from the Web, to give a perspective of the usage in "most important" sites. We could grab this "top websites" data from third-party tools like SEMrush or SimilarWeb, although I don't know if it's ok to refer to third-party tools as "sources" for this type of information. If not, would there be another way to do it that complies with best practices of the Web Almanac, taking into consideration what we want to achieve?
Thanks for your feedback :)
aleyda
on 19 Jul 2020
@aleyda Should be possible. We can import data from the Majestic million and segment various metrics based on the websites ranking 👍
obto
on 20 Jul 2020
@obto Majestic Million is paid.. isn't it ?
rockeynebhwani
on 20 Jul 2020
@rockeynebhwani nope. The download of all the sites rankings is available right on the homepage of their site i linked
obto
on 20 Jul 2020
Analystis @max-ostapenko @antoineeripret
I'm finishing early today (it's noon here) and want to get things out there so others can play. Where I'm at:
I've created a draft pull request where we can add all our new database queries. You should be able to see them here, and hopefully contribute. This is my first time using GitHub with others, so I'm not sure of the dynamics.
At the moment it is mostly last years scripts that have been renamed. The pull request is where I'm chatting with Rick and learning how to do this. He's already provided some change suggestions like updating the main comment and changing the file names.
I've also created a fork to edit the almanac.js file (data from the rendered page). I've added some starter properties and may do a pull soon so we can get feedback from the bosses.
I've been testing it with this simple page. Open the developer console, refresh and you should see an object which is what will be used. You could copy and edit the file to test different things. Or copy the whole script section into the console of any page. I just did it with twitter. 😎

I think it would be worth working out a console script to speed up testing using WebPageTest which powers the real crawl. Instructions to use that are here.
Note that we have to get this script completed and merged before the end of the month. So we need to tie down the metrics we will get from it.
Tiggerito
on 20 Jul 2020
@Tiggerito: Thank you for the update. That's great !
I will have a look at your updated almanac.js this afternoon and see, from the Google Docs document we have, if we are missing some metrics that @aleyda needs. I recall seeing yesterday that she wanted to compare h1 and title, for instance, therefore we need to get the data for her beforehand.
You should have a pull request on your fork by myself when you wake up tomorrow, with the work done today.
antoineeripret
on 20 Jul 2020
@aleyda Should be possible. We can import data from the Majestic million and segment various metrics based on the websites ranking 👍
This is great and will serve well for what we want to do, in this case the sites are ranked by the number of linking subnets but should be ok to give a sense of "most popular" sites too. Will now specify also in the metrics when we want this type of additional "top sites" segmentation. Thanks again!
aleyda
on 20 Jul 2020
Hi @rviscomi - Regarding the Rendering constrains: I see that @Tiggerito wanted to ask you something and then also saw today @ipullrank had some ideas about the rendering constraints, but seems that we can't tag you on the Google Docs comment here. - Could you please check it out? Thanks again for all your help on this :)
aleyda
on 20 Jul 2020
@Tiggerito This is amazing! Regarding the Core Web Vitals: would it be possible also to add "tablet" as part of the devices or is it possible only to get it for mobile and desktop?
I don't think I replied to this one (🍷 warning) the data does actually segment via tablet. I removed it because that's what they did before. I've added all devices back. They may have removed it as all other data sources only segment via mobile/desktop.
Tiggerito
on 20 Jul 2020
@Tiggerito thank you! Yes, if it's possible it would be great to have the tablet segment for the Core Web Vitals :)
aleyda
on 20 Jul 2020
Hi again @obto - when going through the video inclusion/optimization we were wondering about the best method to identify their usage as unlike the images, the video tag is not used in most cases as videos are inserted using third party embeds, like YouTube, Wistia, Vimeo, etc. Should we look for these scripts inclusions to verify the usage? We were wondering how is this done in the Media chapter when specifying Video usage? Thanks in advance!
cc @fellowhuman1101 @ipullrank @Tiggerito @antoineeripret
aleyda
on 20 Jul 2020
@aleyda Should be possible. We can import data from the Majestic million and segment various metrics based on the websites ranking 👍
Hi @obto, another question for you: can we define where (in your BQ dataset) this data will be imported? Just to know how to access this information and include it in our queries with @Tiggerito.
Thanks.
antoineeripret
on 20 Jul 2020
@antoineeripret I'm in talks with Rick and Paul about adding it, and if we should use Majestic Million or Cisco's Umbrella Million. The data would live somewhere like httparchive.almanac.majestic_million though.
Does that help?
obto
on 20 Jul 2020
@aleyda If i recall correctly, we did not detect videos from the HTML precisely for this reason. Instead we analyzed the requests the browser made and checked if the mime type of the file was for a known video format. Here's a link to the Media chapter's queries
obto
on 20 Jul 2020
@aleyda If i recall correctly, we did not detect videos from the HTML precisely for this reason. Instead we analyzed the requests the browser made and checked if the mime type of the file was for a known video format. Here's a link to the Media chapter's queries
Thanks @obto! This is interesting indeed, @antoineeripret @Tiggerito could you please see if we could do the same for validating the the existence of videos? And then besides this it would be to check the usage of the VideoObject structured data :)
aleyda
on 20 Jul 2020
Thanks for the ping. I've replied to the rendering thread. I already get notifications for all comments so that might be why you couldn't @ me in the doc.
Regarding Majestic Millions and other ranked datasets, I want to urge caution that new datasets added to the methodology should be reviewed first. We've avoided approximating site popularity in the past due to incompatibilities with the HTTP Archive's sample set, which is based on real-user data in the unranked Chrome UX Report. It's worth investigating Majestic's efficacy by seeing how many HTTP Archive URLs are covered. There's also a question of compatibility because HTTP Archive tests the home pages of full origins, but some site ranking datasets may only provide domain-level data like google.com as opposed to the full origin like https://maps.google.com. Given all that, I'd encourage you to assume that the data will be unranked. In parallel we can evaluate the efficacy of the ranked datasets.
rviscomi
on 20 Jul 2020
@aleyda If i recall correctly, we did not detect videos from the HTML precisely for this reason. Instead we analyzed the requests the browser made and checked if the mime type of the file was for a known video format. Here's a link to the Media chapter's queries
Thanks @obto! This is interesting indeed, @antoineeripret @Tiggerito could you please see if we could do the same for validating the the existence of videos? And then besides this it would be to check the usage of the VideoObject structured data :)
Looks likes they collected a video count from lighthouse data (04_01) as @obto said via mime types. I could duplicate that.
Tiggerito
on 21 Jul 2020
For eCommerce chapter 2020, I was considering to pull a custom metric to find out how many social channels sites are using on average and publishing this information via Schema.org. I was planning to do this using a custom metric (Thanks to @savsav)
Hi @rviscomi,
How far did you get with this? I've just submitted a pull request with a new structured-data property. At the moment it just counts json-ld scripts and parses them for error. But my plan is to dig in a bit more as well as gather data from other formats like microdata.
I know a bit about SD and processing it with JavaScript (my tool), so could probably pull together something more reliable on anything you want. e.g. your example code assumed sameAs would be in the top object. That would fail for Yoast that uses a graph to define all entities.
With the limited resources we can't include a full blown structured data parser/validator. We will have to fudge things. e.g. as a simple solution I could parse the whole object tree (already done) and create an array of all sameAs properties in it. You won't know the context for them, but you could assume that a sameAs for a social website is related to that old Google feature. And it would be easy to pull in all microdata based sameAs at the same time.
I'm personally interested in pulling in the few properties that Google currently supports in their guidelines for home page based structured data: logo, site link search box and maybe local business properties like address and hours. Again, it will be quite dumb. The presence of the property will assume it is in the right place for what Google requires. I may include some very basic validation where it is easy.
Maybe the pull request is a good place to continue the conversation?
Tiggerito
on 22 Jul 2020
@Tiggerito where did that quote come from, and was it from me? 😅
rviscomi
on 22 Jul 2020
@Tiggerito where did that quote come from, and was it from me? 😅
@rviscomi I tagged the wrong name. It was from @rockeynebhwani 🤦♂️
@rockeynebhwani could your read this post...
https://github.com/HTTPArchive/almanac.httparchive.org/issues/908#issuecomment-662211100
Tiggerito
on 22 Jul 2020
FYI. I just volunteered to be the analyst for the Markup chapter 🤦♂️. There's a lot of overlap in the metrics, so it makes sense to add what they need to what we already get. It may also make me aware of other things of interest to us.
Tiggerito
on 22 Jul 2020
So far I have added a lot of code to gather the metrics asked for. I'm not sure how we are going to review/test it to make sure it covers the requirements and fully works. There's a lot of logic and chosen data based on my own understanding of things. 7 days to go 😲
The pull request now indicates what's implemented and what I think I need to do:
https://github.com/HTTPArchive/legacy.httparchive.org/pull/171
Tiggerito
on 23 Jul 2020
HTTPS pages commonly suffer from a problem called mixed content, where subresources on the page are loaded insecurely over http://.
https://blog.chromium.org/2019/10/no-more-mixed-messages-about-https.html
Would mixed content be a good addition to this chapter?
I made a quick search of the doc and wasn't able to find anything related. We know that Chrome blocks mixed content so this can affect UX, CTR, and therefore SEO. Oh, and we have this Reddit answer from John Mueller.
Nevertheless, I'd still want to see how many HTTPS pages suffer from mixed content?
What do you think?
Afaik, this is provided by Lighthouse's Best Practices, within the "Uses HTTPS" section so this might be easy to get stats for.
cc @Tiggerito
catalinred
on 23 Jul 2020
This is a great call @catalinred - and something I thought I had added along the HTTPS Usage but at the end didn't! Thanks for pointing out. Let's see what @Tiggerito and @antoineeripret say about viability to get this data and if it's possible, add it too :)
aleyda
on 23 Jul 2020
Was measured in Security chapter last year: https://almanac.httparchive.org/en/2019/security#mixed-content so definitely viable.
Probably still belongs there more so than this chapter IMHO as, AFAIK, there is no direct SEO impact of mixed content per se.
Fine to have it in both chapters if important to both but, at the same time, do want to concentrate on what’s really important in each chapter’s topic if it’s only partially relevant — and also to avoid duplicating lots of content.
On the other hand if you do feel it belongs then don’t let me hold you back! Query will likely be written for Security chapter and, if not, then have last year’s query as a basis so should be easy to get the data.
 bazzadp
on 23 Jul 2020
bazzadp
on 23 Jul 2020
Thanks @bazzadp - Really appreciate your feedback!
What do you think about this @ipullrank @fellowhuman1101 @Tiggerito @antoineeripret?
aleyda
on 23 Jul 2020
I'm happy to let the Security guys work it out 😉
Tiggerito
on 23 Jul 2020
I'm trying to test a few things. Can anyone provide example URLs for the following:
Using canonical link in the http header
Using x-robots-tag in the http header
Using googlebot specific x-robots-tag in the http header
Using googlebot specific robots meta tag
etc. Especially complex examples of robots and canonical use.
Tiggerito
on 24 Jul 2020
Just popping in to say that you all are doing an amazing job on this chapter! Really looking forward to seeing the first draft! 🚀
rviscomi
on 24 Jul 2020
And hreflang in the header.
Tiggerito
on 24 Jul 2020
@Tiggerito : You can have a look at https://www.simonelectric.com/ for canonical & hreflang in the HTTP Header. I'm asking around for the other cases because I'm not aware of any.
antoineeripret
on 24 Jul 2020
@antoineeripret that's a great example. Helped me test quite a few things.
I now have what I think is a complete script. But I need help in validating it and double checking it's the data we need.
Here's the zipped up json output for https://www.simonelectric.com/
Some things about it:
We managed to work out how to get the raw html without needing to access the expensive table. I get it injected into the script 😎 Not only that, but I also have access to the headers. 🤯
In the file you will see references to raw/rendered/headers versions of the data.
This is the data everyone gets, so there will be stuff we don't care about.
I can add logic to make it easier to extract information. e.g. I added a canonical_missmatch bool to tell us if there were two different canonical values specified via headers/raw or rendered content. Tell me if there is anything you want.
Maybe we add a new status to the almanac.js column of the metric tables to indicate the data source has been tested and verified?
I can run tests, and teach others how to do it. There is a lot of logic going on here and less than a week to perfect it. There's a good chance some of the data ends up being wrong, but we have a lot of it to work from.
There will be other changes in the structure as I have to fold this in with the main script. But those changes should only add information.
I'm ready for a 🍷 😁
Tiggerito
on 24 Jul 2020
Wow @Tiggerito, that's pretty impressive!! Amazing work you did !!
Maybe we add a new status to the almanac.js column of the metric tables to indicate the data source has been tested and verified?
100%, or use a color code, as you prefer :) We can start building SQL queries as the data source is defined and tested!
antoineeripret
on 24 Jul 2020
Wow @Tiggerito, that's pretty impressive!! Amazing work you did !!
Maybe we add a new status to the almanac.js column of the metric tables to indicate the data source has been tested and verified?
100%, or use a color code, as you prefer :) We can start building SQL queries as the data source is defined and tested!
Cheers,
It would be great if you could take a look and see if the data format would work well for the sort of SQL queries we will make. I was not sure at times what structure would work best. i.e. object properties or arrays.
Tiggerito
on 24 Jul 2020
It would be great if you could take a look and see if the data format would work well for the sort of SQL queries we will make. I was not sure at times what structure would work best. i.e. object properties or arrays.
The way you did it seems perfect because we will be able to use code like the following one (extracted from https://github.com/HTTPArchive/almanac.httparchive.org/blob/main/sql/2019/10_SEO/10_01.sql) accessing the data we need using JSON.parse. In fact, as you already included some logic in your code, the SQL/JS query will be even simpler than that!
CREATE TEMPORARY FUNCTION hasEligibleType(payload STRING)
RETURNS BOOLEAN LANGUAGE js AS '''
try {
var $ = JSON.parse(payload);
var almanac = JSON.parse($._almanac);
var found = almanac['10.5'].findIndex(type => {
if(type.match(/(Breadcrumb|SearchAction|Offer|AggregateRating|Event|Review|Rating|SoftwareApplication|ContactPoint|NewsArticle|Book|Recipe|Course|EmployerAggregateRating|ClaimReview|Question|HowTo|JobPosting|LocalBusiness|Organization|Product|SpeakableSpecification|VideoObject)/i)) {
return true;
}
});
return found >= 0 ? true : false;
} catch (e) {
return false;
}
''';
antoineeripret
on 24 Jul 2020
I'm trying to come up with terminology for types of links. At the moment I'm thinking of following the GSC terminology:
same_page - e.g. a # to a location on the page
same_site - same hostname, same sub domain, internal
same_property - e.g. cross sub domain. this would include a link from www to non www
other_property - to a different domain, external
I was also trying to work out types of links. I think it's too complex to come to conclusions, but maybe gathering info may help.
Gary nicely confirmed that they only crawl httt(s) and ftp based URLs. And Martin has said a few times they only crawl real anchor tags. From that I can assume a link is crawlable if it contains an href that uses an http, https or ftp protocol.
A slight modification to that is if the link is to the same page. Not really crawlable, but it is recorded for creating jump to links. Last year included a clever check to see if a same page link had a named anchor. which splits same_page to:
same_page_jump_to -Googles term. aka anchor link
same_page_other - navigation link was last years term for this and was the source of the report on JS frameworks with issues
Where it gets complicated is in analysing the rest of the links (and same_page_other). And I think this is something of interest in identifying JS framework mistakes.
Lighthouse has a report that tries to identify them, but it only returns a pass/fail and I don't trust the logic. It identifies a few known scenarios like an onclick with commonly known code to change the address. A fail is if it identifies a known/simple mistake. fyi, it checks the role/onclick attribute, protocols, and presence of onclick listeners.
One idea would be to eliminate more links as not being "smart". e.g. simple named anchors, downloads, emails, phone. Maybe we could ignore any of the remaining links without onclick, javascript protocol, or an event listener.
same_page_jumpto - as before
same_page_dynamic - onclick attribute/listener, javascript protocol
same_page_other - downloads, click to call/email etc
same_page_dynamic are suspect mistakes, but many anchor links are for actions, not to change page. This is where lighthouse tries to segment further by identifying code snippets and role attribute values (role means probably an action).
Have I already gone too deep!
Maybe one extra step:
same_page_dynamic_codelink - identified code that indicates it is a link
same_page_dynamic_hasrole - role attribute present
same_page_dynamic_other - still no idea
Or one more. If we are still in other and the link contains a hash.
same_page_dynamic_hashlink - presume code uses the hash to do something
Writing this has helped me get a handle on this. Would love feedback. Summary, links will be categorised:
- same_page
- same_page_jumpto - # with a known named anchor
- same_page_dynamic - onclick attribute/listener, javascript protocol,
- same_page_dynamic_codelink - identified code that indicates it is a link
- same_page_dynamic_hasrole - role attribute present
- same_page_dynamic_hashlink - presume code uses the hash to do something - last years navigational links
- same_page_dynamic_other - still no idea
- same_page_other - named anchor, downloads, click to call/email etc. not of interest
- same_site - same hostname, same sub domain, internal
- same_property - e.g. cross sub domain. this would include a link from www to non www
- other_property - to a different domain, external
Tiggerito
on 25 Jul 2020
I just found a tweet of mine from a query I did on the http archive in 2018. Was quite popular:
https://twitter.com/TonyMcCreath/status/1043850071408697344
Maybe title length should be a formal part of the report 🤪
On that subject.
It could be worth checking for mistakes like the title containing "home page"
I added checks for links containing dofollow and follow 🤷♂️
Any other fun metrics to track?
Tiggerito
on 25 Jul 2020
@Tiggerito - If you are looking for fun metrics, try finding out what % of sites are using 'nositelinkssearchbox' META tag. (For example Amazon uses this) - and what may be their motivation behind this.
I also saw that some analysis on META tag is available here - https://www.similartech.com/technologies/nositelinkssearchbox and https://www.similartech.com/categories/meta-tags
rockeynebhwani
on 25 Jul 2020
I'm trying to come up with terminology for types of links. At the moment I'm thinking of following the GSC terminology:
same_page - e.g. a # to a location on the page
same_site - same hostname, same sub domain, internal
same_property - e.g. cross sub domain. this would include a link from www to non www
other_property - to a different domain, externalI was also trying to work out types of links. I think it's too complex to come to conclusions, but maybe gathering info may help.
Gary nicely confirmed that they only crawl httt(s) and ftp based URLs. And Martin has said a few times they only crawl real anchor tags. From that I can assume a link is crawlable if it contains an href that uses an http, https or ftp protocol.
A slight modification to that is if the link is to the same page. Not really crawlable, but it is recorded for creating jump to links. Last year included a clever check to see if a same page link had a named anchor. which splits same_page to:
same_page_jump_to -Googles term. aka anchor link
same_page_other - navigation link was last years term for this and was the source of the report on JS frameworks with issuesWhere it gets complicated is in analysing the rest of the links (and same_page_other). And I think this is something of interest in identifying JS framework mistakes.
Lighthouse has a report that tries to identify them, but it only returns a pass/fail and I don't trust the logic. It identifies a few known scenarios like an onclick with commonly known code to change the address. A fail is if it identifies a known/simple mistake. fyi, it checks the role/onclick attribute, protocols, and presence of onclick listeners.
One idea would be to eliminate more links as not being "smart". e.g. simple named anchors, downloads, emails, phone. Maybe we could ignore any of the remaining links without onclick, javascript protocol, or an event listener.
same_page_jumpto - as before
same_page_dynamic - onclick attribute/listener, javascript protocol
same_page_other - downloads, click to call/email etcsame_page_dynamic are suspect mistakes, but many anchor links are for actions, not to change page. This is where lighthouse tries to segment further by identifying code snippets and role attribute values (role means probably an action).
Have I already gone too deep!
Maybe one extra step:
same_page_dynamic_codelink - identified code that indicates it is a link
same_page_dynamic_hasrole - role attribute present
same_page_dynamic_other - still no ideaOr one more. If we are still in other and the link contains a hash.
same_page_dynamic_hashlink - presume code uses the hash to do something
Writing this has helped me get a handle on this. Would love feedback. Summary, links will be categorised:
* same_page * same_page_jumpto - # with a known named anchor * same_page_dynamic - onclick attribute/listener, javascript protocol, * same_page_dynamic_codelink - identified code that indicates it is a link * same_page_dynamic_hasrole - role attribute present * same_page_dynamic_hashlink - presume code uses the hash to do something - last years navigational links * same_page_dynamic_other - still no idea * same_page_other - named anchor, downloads, click to call/email etc. not of interest * same_site - same hostname, same sub domain, internal * same_property - e.g. cross sub domain. this would include a link from www to non www * other_property - to a different domain, external
I think the depth of information needed here depends on what @aleyda and her co-authors will want to add in their analysis. I think it is pretty complete but they may need less.
Let's see what she replies :)
antoineeripret
on 26 Jul 2020
I think the depth of information needed here depends on what @aleyda and her co-authors will want to add in their analysis. I think it is pretty complete but they may need less.
Let's see what she replies :)
I've implemented it with a few changes. I'm not trusting some of the deeper numbers but have put effort in to try and make sure the asked for information is accurate.
I think some if this extra info may not be usable this year. There's not any time to review my logic. But it puts in place the concept for next year.
I've also updated the metrics table with the property names that contain the data required. That will help when coming to doing the queries. It also helped me double check that I had covered everything.
Tiggerito
on 27 Jul 2020
Here's the latest output from https://www.simonelectric.com/simon-100/io
And one from a client of mine that adds SD via JavaScript
And a little bonus. If approved, I've created another custom metrics to access the robots.txt file.
{
"redirected": false,
"status": 200,
"size": 522,
"allow_lines": 1,
"disallow_lines": 18,
"user_agents": [
"*",
"google-xrawler",
"*"
],
"sitemaps": []
}
I'd really like some example URLs that cover possible edge cases and the sorts of data we are gathering. We need to try and test this a little bit more 😲
Tiggerito
on 27 Jul 2020
@Tiggerito : you need a list of robots.txt file covering several scenarios like:
- Empty
- Disallow rule(s)
- Allow (rule(s)
- Generic UA rule(s)
- UA specific rule(s)
etc...
Right?
antoineeripret
on 27 Jul 2020
@Tiggerito : you need a list of robots.txt file covering several scenarios like:
- Empty
- Disallow rule(s)
- Allow (rule(s)
- Generic UA rule(s)
- UA specific rule(s)
etc...
Right?
This is what I'm gathering so far. Just some regex to identify line types. I think parsing and dissecting the file is beyond this years work. A relatively simple parse would be to do line by line and put counts under each UA. Not sure of the value of counting rules.
Reporting on the most popular UAs specified could be interesting. Who gets done the most.
And the presence of a sitemap. Don't ask me to crawl the sitemaps as well. I think that would really push the boundaries.
A flag for a completely empty file could easily be done.
Maybe a count of disallow all/none lines would be of interest?
I'm actually doing a javascript fetch inside the rendered page to get this (hopefully this technique will be approved). It means I can process the content with JavaScript.
This is the last week to get all the code tested, reviewed, approved and included in the main version. Not a code freeze yet, but let's focus on making sure what we have is working, accurate and useful.
Tiggerito
on 27 Jul 2020
@Tiggerito : you need a list of robots.txt file covering several scenarios like:
- Empty
- Disallow rule(s)
- Allow (rule(s)
- Generic UA rule(s)
- UA specific rule(s)
etc...
Right?This is what I'm gathering so far. Just some regex to identify line types. I think parsing and dissecting the file is beyond this years work. A relatively simple parse would be to do line by line and put counts under each UA. Not sure of the value of counting rules.
Reporting on the most popular UAs specified could be interesting. Who gets done the most.
And the presence of a sitemap. Don't ask me to crawl the sitemaps as well. I think that would really push the boundaries.
A flag for a completely empty file could easily be done.
Maybe a count of disallow all/none lines would be of interest?
I'm actually doing a javascript fetch inside the rendered page to get this (hopefully this technique will be approved). It means I can process the content with JavaScript.
This is the last week to get all the code tested, reviewed, approved and included in the main version. Not a code freeze yet, but let's focus on making sure what we have is working, accurate and useful.
I think @aleyda should weigh-in to see what really matters for the analysis then. If she can't, I'd that to keep it simple, like what you have + a flag for empty file and a line(s) for sitemap(s).
antoineeripret
on 27 Jul 2020
Hi all, I'm really wanting example URLs with the features you would like to gather data on.
We need the data gathering code I developed to be approved before Aug 1st, or we don't get any of the data. 😲
If what you want is not tested to work, you may not get it.
My testing does not count. I'm testing based on my understanding on what is needed. What I think may not be what you wanted.
Give me examples and the data you're interested in, and I can show you what you will get.
Tiggerito
on 27 Jul 2020
I've run a bunch of tests on URLs the Markup chapter gave me and a core set of URLs that get test. All seemed to work 🥳
The code is frozen bar bug fixes. It's now 🤞 that it gets reviewed, approved and added before the 1st deadline. If not, we get the same data as last year 😒
Some entertainment while testing:
And from ahrefs...
Tiggerito
on 28 Jul 2020
Good news, All the code to gather the data has been merged and will be run in next months crawl. 🥳
If all goes to plan we should be getting my selected data from rendered and raw content, http headers, and the robots.txt file.
And I have a day to spare. I'm taking the afternoon off.
Tiggerito
on 30 Jul 2020
@Tiggerito You have been an absolute powerhouse! Hope you enjoyed the afternoon off.
dwsmart
on 30 Jul 2020
@aleyda @max-ostapenko @Tiggerito @antoineeripret for the two milestones overdue on July 27 could you check the boxes if:
- the outline has been reviewed and all feasible metrics have been identified
- any necessary custom metrics have been created and you've created a draft PR to track which feasible metrics have had their queries implemented (we've updated the milestone description to clarify this)
Keeping the milestone checklist up to date helps us to see at a glance how all of the chapters are progressing. Thanks for helping us to stay on schedule!
obto
on 30 Jul 2020
Thanks for the heads up @obto - I'll make sure to follow-up with @ipullrank @aleyda @fellowhuman1101 in the next couple of days to make sure the outline is 100% final now (it should be but just in case) and with @Tiggerito @antoineeripret to make sure the metrics are also done.
Thanks again!
aleyda
on 30 Jul 2020
We can tick of the 27th milestone. The custom metrics are in and I have created a PR for the queries.
After having a breather we need to review what we ended up with and work out what queries are needed, and what will make it into the chapter.
Tiggerito
on 31 Jul 2020
I've updated the tables with the new mappings to the custom metrics. I've also documented what I think covers all the data we will be using:
https://docs.google.com/document/d/1c5x_IskO6NOzUQqdbbMLWPr_iteGzAFwIyk2ffJtzdg/edit?usp=sharing
Tiggerito
on 1 Aug 2020
Good news. I've had a chance to see some initial data from what I think was some test crawls, and it looks like everything is working 🥳
Tiggerito
on 3 Aug 2020
Thanks for your awesome work @Tiggerito and @antoineeripret ! Checked the 27th milestone already :D Great to hear also about the initial test crawls being successful, ... if you need anything from me just let us know!
I see that the next milestone is on September 7 to have all the metrics queried so we can start reviewing the results sheet which should be done by September 14... which would give us a month for the next one which is to have completed the first draft in the doc on October 12.
cc @ipullrank @fellowhuman1101
aleyda
on 4 Aug 2020
Interesting insights on HTTP codes (mostly 404) on this post by Matt Hobbs (@Nooshu), maybe it can help for queries and comments: "Why you should be testing your 404 pages web performance".
 borisschapira
on 26 Aug 2020
borisschapira
on 26 Aug 2020
@antoineeripret and I have been beavering away over the last month and now have all sql queries worked out bar a few in negotiation.
I've updated the table in the guide to reference the relevant queries and fields.
So far testing is on old or made up data. We should get the real data soon!
Tiggerito
on 1 Sep 2020
I've updated the chapter metadata at the top of this issue to link to the public spreadsheet that will be used for this chapter's query results. The sheet serves 3 purposes:
- Enable authors/reviewers to analyze the results for each metric without running the queries themselves
- Generate data visualizations to be embedded in the chapter
- Serve as a public audit trail of this chapter's data collection/analysis, linked from the chapter footer
obto
on 1 Sep 2020
I've now updated all queries to point to the latest data and ran the biggest one to test things. Some initial results are in the sheet:
https://docs.google.com/spreadsheets/d/1ram47FshAjzvbQVJbAQPgxZN7PPOPCKIK67VJZCo92c/edit#gid=337739550
Once the queries have been reviewed I can continue to populate the sheet.
I did spot one issue. It seems some css querySelectors are case sensitive, in particular the name text for a meta tag, and I did not pick up on that. This means I've only picked up lower case names for description and robots. Unfortunately this is in the custom metrics code which is part of the crawl, which has now been completed. We may have money left in the end to do the expensive raw html query to gather anything like this via regex.
Tiggerito
on 5 Sep 2020
Hi @Tiggerito - can you please confirm when the content team can start reviewing the data -it had been set for this week in the schedule so want to make sure we are on time and to leave enough time to start writing afterwards-. I've checked the sheet above and in column C & D I see percentages of usages and would like to make sure these are the "final" values and if these have been already obtained from all the required metrics? Thanks!
aleyda
on 10 Sep 2020
Hi @Tiggerito - can you please confirm when the content team can start reviewing the data -it had been set for this week in the schedule so want to make sure we are on time and to leave enough time to start writing afterwards-. I've checked the sheet above and in column C & D I see percentages of usages and would like to make sure these are the "final" values and if these have been already obtained from all the required metrics? Thanks!
I'm waiting on the queries to be reviewed and accepted (merged) before I run them all and push all the data into the sheet. The allocated reviewers are currently being nagged by the system. I'm not expecting any changes in the data, but the reviewers may find some flaws in my queries that are best fixed before we spend the money to get the data.
The existing data is real/final and taken from last months crawl. So that can be reviewed by the content team.
In a short period we wrote a lot of custom metrics code and sql queries to get this data. While reviewing please cast a critical eye, and flag anything that looks dodgy. I can then re-review the full sequence of how the data was gathered and we can decide if it is accurate or not. Also, please ask if the meaning of a value is not clear, and I can provide more details. I will be trying to document them all as I pull in the data.
I already spotted a flaw in the way meta descriptions were gathered. If they write DESCRIPTION the code would not pick it up. It only likes lowercase. This will probably only mean a small percent of results are lost, but we probably should mention it in the chapter. I've already submitted a fix, but it will not be used until the October crawl.
And a reminder that this data only relates to the home pages of sites.
And you are all free to edit and enhance the sheet. In fact I encourage it 😀 Check out the data viz tab which provides the standard charts we should base our reports on.
Tiggerito
on 10 Sep 2020
Thanks @Tiggerito ! Really appreciate it. We will do that :) Could you please let us know when the data is ready, and from where we can grab, it so we can start with the writing? Also, regarding the graphs: is this something that analysts will provide or do we need to generate them? Let us know to coordinate!
@ipullrank and @fellowhuman1101 - please take a look at the table I've added to the Google Doc to distribute the topics :)
aleyda
on 14 Sep 2020
Thanks @Tiggerito ! Really appreciate it. We will do that :) Could you please let us know when the data is ready, and from where we can grab, it so we can start with the writing? Also, regarding the graphs: is this something that analysts will provide or do we need to generate them? Let us know to coordinate!
@ipullrank and @fellowhuman1101 - please take a look at the table I've added to the Google Doc to distribute the topics :)
I'm still waiting on the sql to be approved. They have a lot of chapters to review and it's taking them time. I don't think they took this into account on the deadlines. My stuff has had an initial review and I'm waiting on a second pass. I'll work on pulling the data in as soon as I can.
It would be great to get some support in processing the results and creating the graphs. My boss (me) will kill me for all the time I've already spent on this. And we need more critical eyes on the data. At the moment all trust is on the fact that I get everything right. Highly unlikely.
All real data, and only real data goes into the official sheet:
https://docs.google.com/spreadsheets/d/1ram47FshAjzvbQVJbAQPgxZN7PPOPCKIK67VJZCo92c/edit#gid=2077755325
Tiggerito
on 14 Sep 2020
p.s. bad day, Spent over 12 hours trying to resolve a hosting issue, with no progress. Anyone know of a reliable Asp.Net hosting service?
Tiggerito
on 14 Sep 2020
@Tiggerito, have you tried Azure?
dwsmart
on 14 Sep 2020
@Tiggerito, have you tried Azure?
Just created an account with them. Looks complex and more expensive than my current hosting. But I guess with that you get control and power. I need an IT department!
Tiggerito
on 15 Sep 2020
Thanks @Tiggerito ! Really appreciate it. We will do that :) Could you please let us know when the data is ready, and from where we can grab, it so we can start with the writing? Also, regarding the graphs: is this something that analysts will provide or do we need to generate them? Let us know to coordinate!
@ipullrank and @fellowhuman1101 - please take a look at the table I've added to the Google Doc to distribute the topics :)I'm still waiting on the sql to be approved. They have a lot of chapters to review and it's taking them time. I don't think they took this into account on the deadlines. My stuff has had an initial review and I'm waiting on a second pass. I'll work on pulling the data in as soon as I can.
It would be great to get some support in processing the results and creating the graphs. My boss (me) will kill me for all the time I've already spent on this. And we need more critical eyes on the data. At the moment all trust is on the fact that I get everything right. Highly unlikely.
All real data, and only real data goes into the official sheet:
https://docs.google.com/spreadsheets/d/1ram47FshAjzvbQVJbAQPgxZN7PPOPCKIK67VJZCo92c/edit#gid=2077755325
Table updated. Ready to divide and conquer 👍
fellowhuman1101
on 16 Sep 2020
Thank you @fellowhuman1101 - that's great :) @ipullrank - could you please check out the remaining ones in the table if these are good for you? If you would like to write any of these along others or which you wouldn't? Let us know to finish the split and start :) Thanks again!
aleyda
on 16 Sep 2020
Hi @Tiggerito , I want to confirm with you if we can start writing based on what has been included in this sheet? - is that the final data and is all complete? Thanks again!
@fellowhuman1101 @ipullrank The topics have been split now :) Thank you so much! As soon as @Tiggerito confirms we can start!
aleyda
on 18 Sep 2020
Hi @Tiggerito , I want to confirm with you if we can start writing based on what has been included in this sheet? - is that the final data and is all complete? Thanks again!
@fellowhuman1101 @ipullrank The topics have been split now :) Thank you so much! As soon as @Tiggerito confirms we can start!
Hopefully we will have the data complete soon. Any data in that sheet is real data. I've only pulled in a few queries so far as we do not have approval for them yet. 99.99% there though.
The documents SQL status column now indicates which SQL query was used to get the data and which fields are relevant. The sheet will have a tab per SQL query that will contain all the fields it gathered.
I've just worked out that you can link to a sheets tab. We'll make the SQL column link to the relevant data, and that would be an indication that the data is there.
Tiggerito
on 19 Sep 2020
Another analyst was asking about using a top 1k, top 10k ranking website list for their data. I know we were talking about this for Core Web Vitals using maybe Majestic Millions, but I can't find the the full conversation. Anyone remember where it is or what was decided?
Tiggerito
on 21 Sep 2020
Another analyst was asking about using a top 1k, top 10k ranking website list for their data. I know we were talking about this for Core Web Vitals using maybe Majestic Millions, but I can't find the the full conversation. Anyone remember where it is or what was decided?
Hi @Tiggerito here's @obto comment about it :) in this same thread from July 20.
aleyda
on 21 Sep 2020
Another analyst was asking about using a top 1k, top 10k ranking website list for their data. I know we were talking about this for Core Web Vitals using maybe Majestic Millions, but I can't find the the full conversation. Anyone remember where it is or what was decided?
Hi @Tiggerito here's @obto comment about it :) in this same thread from July 20.
Perfect.
Tiggerito
on 21 Sep 2020
Please also see my reply about ranking datasets: https://github.com/HTTPArchive/almanac.httparchive.org/issues/908#issuecomment-661246514
rviscomi
on 21 Sep 2020
FYI, @bazzadp just posted about a Lighthouse query to see percentage of sites passing their scores, like the SEO scores.
https://app.slack.com/client/T5ELN8H17/CGFLV2S06/thread/CGFLV2S06-1601119631.003300
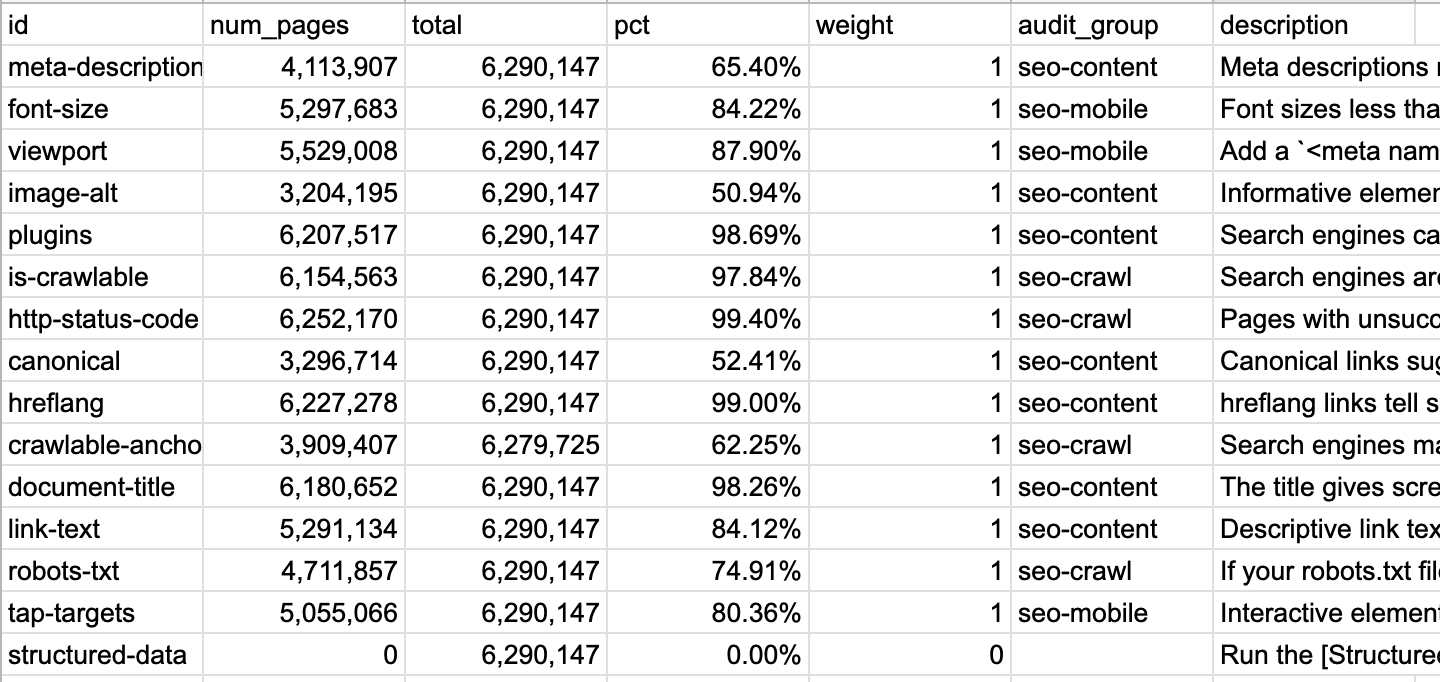
Tiggerito
on 28 Sep 2020
Also these are the overall Lighthouse SEO scores by percentile across our 6.2 million sites:
date|percentile|score
----|----|----
2020_08_01|10|69%
2020_08_01|25|79%
2020_08_01|50|86%
2020_08_01|75|92%
2020_08_01|90|98%
Quite high actually! Only 10% of sites score 69% or lower.
Maybe Lighthouse needs to get stricter about SEO scores and audit for more things?
Here's Performance as an example (for Sep as Aug run had an issue for Performance metrics) - notice how it is much more spread out:
date|percentile|score
----|----|----
2020_09_01|10|08%
2020_09_01|25|16%
2020_09_01|50|31%
2020_09_01|75|55%
2020_09_01|90|80%
And Accessibility, is similar to SEO:
date|percentile|score
----|----|----
2020_08_01|10|55%
2020_08_01|25|68%
2020_08_01|50|80%
2020_08_01|75|88%
2020_08_01|90|94%
As is Bess Practices:
date|percentile|score
----|----|----
2020_08_01|10|62%
2020_08_01|25|69%
2020_08_01|50|77%
2020_08_01|75|79%
2020_08_01|90|86%
PWA is more spread out but that would make sense as requires extra steps (service workers and manifests) that are still not common yet:
date|percentile|score
----|----|----
2020_08_01|10|18%
2020_08_01|25|29%
2020_08_01|50|32%
2020_08_01|75|46%
2020_08_01|90|54%
I've always maintained Performance is the toughest Lighthouse category (despite considering myself a bit of an expert in web performance), and guess this proves it!
bazzadp
on 28 Sep 2020
I've had a look at the lighthouse code for SEO and my opinion is that it is a bit crude. Here's how I think a few work:
meta-description - pass if the tag is present
hreflang - fail if an invalid tag is present. e.g. pass if no tags present.
canonical - pass if no tag present or one is present and is self canonicalised
robotstxt - this does validate status code and content syntax
link-text - fails if a link contains poor text, like 'click here'
is-crawlable - checks meta robots tag, x-robots and robots.txt so mixing up indexing and crawling
crawlable-anchors - fails if it detects an anchor that may behave like a link but is not crawlable. e.g. uses window.location, has a click hander or even href="javascript:void(0)". I think a lot of false fails.
Tiggerito
on 29 Sep 2020
Hi @bazzadp and @Tiggerito ,
Yes, the configurations checked by Lighthouse SEO section: https://web.dev/lighthouse-seo/ -which I see that are aligned to the ones of the gathered metrics above, in many cases just inform about the presence or not of elements without taking into consideration their configuration (which we will be doing across even more SEO related configurations) or the context (not having an hreflang annotation doesn't mean that is not well optimized, it's only intended for internationally targeted sites and even not needed if the site is already well geolocated), so we should take those scores with a grain of salt :)
aleyda
on 29 Sep 2020
Hey @aleyda / @Tiggerito of course automated checks are limited in what they can actually check. Though we need to be aware that counts for our own stats too - not discounting the huge job @Tiggerito did in getting many more stats (and more accurate stats too with the custom metrics!) for this year.
Saying that I wouldn't be so quick to discount the Lighthouse ones either. While I am sure they are not perfect and can only check certain things, they will have been worked on and improved over time - whereas some of our stats are the first time they have run. But we definitely do need careful reading of what they actually check!
@Tiggerito all those checks you listed look like good checks to me and don't think they are crude to be honest? Though of course we have the additional benefit of looking at Desktop and Mobile (Lighthouse in HTTPArchive is just Mobile for now) and slicing the data in other ways too. Also I don't think the last (crawlable-anchors) is that liable to false fails to be honest. At the very least the non-JavaScript version of googlebot will struggle with these (as will other crawlers).
@aleyda I think you've misunderstood the hreflang check. It is ONLY checked if one exists to see if it is valid. So not sending it, or sending a valid one passes, but sending an invalid one fails. That is why 99% of sites pass this check - trust me - 99% of sites definitely don't have an hreflang set! 😀
In general I find Lighthouse is pretty good at only including stats that are less likely to create noise - particularly for the ones that have a weighting and so contribute to the score (the ones with 0 weightings are usually WIP or advice which may be more liable to false positives/negatives).
Anyway, the stats are there as an additional source of data to mine if you want. You were already getting some Lighthouse stats, so this query just fills those out to grab ALL the stats that go into the SEO Lighthouse score. So might just be one or two more that give nuggets of interest. However if you think there's nothing of interest there, or that you have enough (and better!) stats of your own that's totally fine too.
At the very least they are nice to serve as a double check of our own stats: For example, Lighthouse says that 65% of site set a meta description which is non-empty. We have 68%. That's pretty close so think that's a good confirmation that our stats are roughly in line. If we were way off, then it might warrant some extra investigation. Though am still curious to know the 3% difference (are we looking at blank descriptions but Lighthouse is not? Is our definition of blank different?).
bazzadp
on 29 Sep 2020
Hi @bazzadp - thanks for the clarification about the hreflang, that makes much more sense :) and please, don't take my answer above as a message to "discount" them - we definitely won't, we will take them into consideration when doing the write up and give a broader view/validation of the data gathered. My comment was more to add some context to the comment of "Maybe Lighthouse needs to get stricter about SEO scores and audit for more things?" - which is yes :D Cheers!
aleyda
on 29 Sep 2020
Well if we come up with any stats out of our analysis, that we think would make good additional audits then we should raise an issue with the Lighthouse team. It's a great thing for the Web Almanac when we can contribute back to the community from our efforts and improve things going forward beyond our little project!
bazzadp
on 29 Sep 2020
@bazzadp oh I didn't know we could do that :) that's a great idea, thanks! This is something we could definitely do with those metrics we see are highly helpful and we've been able to gather/show important configurations for and could be beneficial and not hard to add there... @Tiggerito @antoineeripret @ipullrank @fellowhuman1101 let's do this when we finish the chapter!
aleyda
on 29 Sep 2020
I was planning on providing feedback and maybe even contributing to Lighthouse when I recover from all this 😵
I'm about to pull in all the data. Hopefully my remaining cash will cover it all.
Tiggerito
on 30 Sep 2020
I've gathered all the data and added links in the docs tables to the appropriate tabs in the data sheet.
Tiggerito
on 30 Sep 2020
Thanks SO much @Tiggerito ! I'm going through the sheet and all looks great :D I just have a question regarding the graphics @obto - should we generate them ourselves when writing the content? should we follow certain standards? :) I was looking for information mentioned before but couldn't find it - thanks in advance! cc @fellowhuman1101 @ipullrank
aleyda
on 30 Sep 2020
If I can butt in again, I wrote a wiki on this, which should answer your questions: https://github.com/HTTPArchive/almanac.httparchive.org/wiki/Figures-Guide. Let me know if that doesn't answer any questions - or you should have edit access to that yourself if you spot any typos or useful information to add.
bazzadp
on 30 Sep 2020
This is amazing! Thanks so much @bazzadp :) Let's follow these best practices/guidelines for figures @ipullrank @fellowhuman1101 as well as what's described here in the author's guide. 🙌
aleyda
on 30 Sep 2020
I played a little with creating charts:
https://docs.google.com/spreadsheets/d/1ram47FshAjzvbQVJbAQPgxZN7PPOPCKIK67VJZCo92c/edit#gid=337739550
https://docs.google.com/spreadsheets/d/1ram47FshAjzvbQVJbAQPgxZN7PPOPCKIK67VJZCo92c/edit#gid=1317352222
Please ask if you want clarification on how a metric was determined.
Tiggerito
on 30 Sep 2020
Thanks @Tiggerito ! You rock :)
aleyda
on 1 Oct 2020
Hi @clarkeclark @natedame @catalinred @aysunakarsu @ashleyish @dsottimano @dwsmart @en3r0 @Gathea @rachellcostello @ibnesayeed,
I wanted to get in touch since we are now 90% ready with the SEO chapter - @fellowhuman1101, @ipullrank and yours truly are adding some last remaining data with the help of @Tiggerito and expect to finish with the conclusions at the start of next week; so this is a heads up that we will be in touch mid-next week so you can start the reviewing process. Could you please confirm your availability for the following couple of weeks for it? :)
Also, please refer to this document for the reviewers guide (see the resources at the bottom), so you can start taking a look at it and take into consideration when reviewing the chapter.
Thanks again!
aleyda
on 17 Oct 2020
Could you please confirm your availability for the following couple of weeks for it?
Yes, I am standing by! :-)
ibnesayeed
on 17 Oct 2020
Ready to go!
Nate Dame
CEO
Office: 312-470-6553
On Sat, Oct 17, 2020 at 7:54 AM Sawood Alam notifications@github.com
wrote:
Could you please confirm your availability for the following couple of
weeks for it?Yes, I am standing by! :-)
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/HTTPArchive/almanac.httparchive.org/issues/908#issuecomment-710919846,
or unsubscribe
https://github.com/notifications/unsubscribe-auth/AQDZ6GOEHQRESA5CVKNZBKTSLGHZ7ANCNFSM4OJ2CRXA
.
natedame
on 17 Oct 2020
I'm good to go, captains!
dwsmart
on 17 Oct 2020
All wings, report in!
rviscomi
on 17 Oct 2020
Yes, excited to review!
On Sat, Oct 17, 2020 at 12:41 PM Rick Viscomi notifications@github.com
wrote:
All wings, report in!
https://www.youtube.com/watch?v=eEeTWVru1qc
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/HTTPArchive/almanac.httparchive.org/issues/908#issuecomment-711042784,
or unsubscribe
https://github.com/notifications/unsubscribe-auth/ABV37MMRISHVEIRVLCO4CIDSLHCLPANCNFSM4OJ2CRXA
.
en3r0
on 18 Oct 2020
Count me in! :)
catalinred
on 18 Oct 2020
@aleyda in case you missed it, we've adjusted the milestones to push the launch date back from November 9 to December 9. This gives all chapters exactly 7 weeks from now to wrap up the analysis, write a draft, get it reviewed, and submit it for publication. So the next milestone will be to complete the first draft by November 12.
However if you're still on schedule to be done by the original November 9 launch date we want you to know that this change doesn't mean your hard work was wasted, and that you'll get the privilege of being part of our "Early Access" launch.
Please see the link above for more info and reach out to @rviscomi or me if you have any questions or concerns about the timeline. We hope this change gives you a bit more breathing room to finish the chapter comfortably and we're excited to see it go live!
obto
on 22 Oct 2020
Thanks @obto for the update, it's great to have the option of a few extra weeks for additional revisions/validations! @fellowhuman1101 @ipullrank - how do you feel about having the extra month (so we have up to Nov 12 to finalize the draft)?
aleyda
on 22 Oct 2020
Hi @clarkeclark @natedame @catalinred @aysunakarsu @ashleyish @dsottimano @dwsmart @en3r0 @Gathea @rachellcostello @ibnesayeed ... after a few last weeks of going through some last insights we wanted to confirm the SEO chapter Draft has been finished and is now ready for your revision :)
Please note:
- Here's the Reviewers' guide, so you can take a look before starting the review process and take it into consideration when revising the chapter.
- The SEO chapter draft starts in page 27 of the doc.
- Also in page 27 you have some notes in red that we took into consideration when writing the chapter, including links to the sheet with the SEO data/findings and graphs, as well as link to last year chapter we make reference to through the chapter too.
- If you have specific questions or requests, it might be easier if you take into consideration who was in charge of that section of the chapter so you can tag the person if possible since we (@fellowhuman1101, @ipullrank and yours truly) distributed the work across them. You can see who was in charge of each section in the table included at the start of the Outline, page 2 of the doc.
Thanks and looking forward to your revisions :)
Thanks @obto and @rviscomi for the extra time and input in the last weeks with the request of extra data and again to the amazing @Tiggerito for his continuous support!
aleyda
on 23 Nov 2020
@aleyda awesome!!! Forgive me if I'm just missing this, but.... Do you want us to "suggest changes" in the doc? I began on pages 27-28 and just want to be sure what I'm doing is what's expected.
natedame
on 23 Nov 2020
Thanks for the question @natedame and probably useful for the rest of reviewers too!
Yes, please make use of the "Suggestion" feature of Google docs to add suggestions and if you have questions/doubts, please leave them as comments and tag the person in charge of that topic so we can answer :) That's probably the easiest way to move forward and make it as collaborative as possible so all authors and reviewers can see the suggestions and comments too.
cc @clarkeclark @catalinred @aysunakarsu @ashleyish @dsottimano @dwsmart @en3r0 @Gathea @rachellcostello @ibnesayeed
aleyda
on 23 Nov 2020
Thanks Aleyda, and when is the deadline for our revisions?
On Mon, Nov 23, 2020, 11:36 AM Aleyda Solis notifications@github.com
wrote:
Thanks for the question @natedame https://github.com/natedame and
probably useful for the rest of reviewers too!Yes, please make use of the "Suggestion
https://support.google.com/docs/answer/6033474?hl=en" feature of Google
docs to add suggestions and if you have questions/doubts, please leave them
as comments and tag the person in charge of that topic so we can answer :)
That's probably the easiest way to move forward and make it as
collaborative as possible so all authors and reviewers can see the
suggestions and comments too.cc @clarkeclark https://github.com/clarkeclark @catalinred
https://github.com/catalinred @aysunakarsu
https://github.com/aysunakarsu @ashleyish https://github.com/ashleyish
@dsottimano https://github.com/dsottimano @dwsmart
https://github.com/dwsmart @en3r0 https://github.com/en3r0 @Gathea
https://github.com/Gathea @rachellcostello
https://github.com/rachellcostello @ibnesayeed
https://github.com/ibnesayeed—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/HTTPArchive/almanac.httparchive.org/issues/908#issuecomment-732277218,
or unsubscribe
https://github.com/notifications/unsubscribe-auth/ABV37MM3Y7MRW37O5BAX7LLSRKFR3ANCNFSM4OJ2CRXA
.
en3r0
on 24 Nov 2020
Thanks for the question @en3r0 and also think it will be useful for other reviewers so I copy them here: @clarkeclark @catalinred @aysunakarsu @ashleyish @dsottimano @dwsmart @Gathea @rachellcostello @ibnesayeed @natedame
From what I see the deadline to have the review ready is Nov. 26 which is in a couple of days already (!) and I know the target release date is on Dec 9, so it should be definitely revised and ready to be published a few days before that. ... so I would like to ask to @obto @rviscomi if it's possible to have until early next week for review? Possibly until Dec 1st to leave you a few days? We look forward to your feedback/input for the reviewers :)
Thanks again!
aleyda
on 24 Nov 2020
Just had a (very quick!) scroll through this and it looks fantastic! Well done all.
I made a few comments, mostly on general project level stuff.
And just to warn you, there will be a round of editing once you're finished, by someone on the Editing team to catch things like that, and have a different pair of eyes outside of the immediate content team. The level of editing often catches some Authors by surprise after they've spent so much effort on this, so just wanted to give you a heads up to avoid that shock hopefully. You all will be copied on the editing pull request when that happens so you can ensure you're happy with any proposed changes and also make sure we haven't introduced any inaccuracies.
But that's all ahead of us, so for the moment if you could spend the next few days reviewing and closing out any comments in the Google Doc, and then convert it to your markdown document including all the Figure data. At that point we can show you what it will look like on our site and then also edit it before launch on the 9th.
But looking great so far so! Coming close to the final stretch 🎉
bazzadp
on 24 Nov 2020
Thanks for your kind feedback and heads up @bazzadp - I'm already taking a look at your comments and started to edit accordingly.
I wasn't aware of the markdown document version we need to generate, I'll take a look at that to prepare accordingly cc @fellowhuman1101 @ipullrank check this out please too!
aleyda
on 24 Nov 2020
Doesn't look like I can leave suggestions on the doc, I'm guessing because my google account email is different to my github one? I requested access.
dwsmart
on 25 Nov 2020
Hi @dwsmart - I just gave you access with the tamethebots one :) can you please try?
aleyda
on 25 Nov 2020
Hey @aleyda, Rick was kind enough to let me in!
dwsmart
on 25 Nov 2020
Perfect @dwsmart - I see your comments there already :)
aleyda
on 25 Nov 2020
Just so I understand what's being referenced here
https://t.sidekickopen06.com/s1t/c/5/f18dQhb0S7lC8dVcQLW1BKgCc5_6WxgN3LyZZyq5gqBM63LG56Qwn7W2t4yPV2z6ptBf1-9Bn-02?te=W3R5hFj4cm2zwW3P28X24hCPvhW43T4Nl34n_bXW49JGyr4kCBw3W3ZYxGx3z8gWjW4fNSkh49JGyrW4kCBqB49Ldr_W3T03Vt2zY68yW49KwrL2C_GxsW3JyYYR43myvQW1GHbH345SzNfW3SYkW11GBcSWW1Gy-H_3zhs7RW3NB9bX3P78r32273&si=4864404790706176&pi=dbe8635c-eb22-436b-ab8b-6700c66e2a05.
We need to copy the charts as images rather than the live Google charts and
then export everything as markdown?
On Wed, Nov 25, 2020 at 10:08 AM Aleyda Solis notifications@github.com
wrote:
Perfect @dwsmart https://github.com/dwsmart - I see your comments there
already :)—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/HTTPArchive/almanac.httparchive.org/issues/908#issuecomment-733763585,
or unsubscribe
https://github.com/notifications/unsubscribe-auth/AAH6UV7KPB33KOE3SAZT4FTSRUMWXANCNFSM4OJ2CRXA
.
--
Michael KingFOUNDER/MANAGING DIRECTOR
2020 Search Engine Land Awards Search Marketer of the Year
[email protected]
(347) 391-4266
We are a better performance marketing agency.
Just need marketing advice? Request a call here
http://clarity.fm/ipullrank.
[image: Runtime_Resource_Header.jpg]
Watch Runtime, https://ipullrank.com/runtime/ an iPullRank film on
Technical SEO tips and techniques.
ipullrank
on 25 Nov 2020
We use both the images (mobile) and embedded Google sheets (desktop). We have a Markup Function to take in both the image filename (which should be added to Git) and the Sheets embed URL and it will display the appropriate image depending on device size and device capabilities.
You can see the 2019 SEO chapter makeup here (including examples of that figure markup): https://github.com/HTTPArchive/almanac.httparchive.org/blob/main/src/content/en/2019/seo.md and that is converted at build time to this page: https://almanac.httparchive.org/en/2019/seo
I think the Analysts should export the images, and create the figure markup as they know the Sheets, and SQL file for each sheet (we hope to link both from each figure soon to allow readers to explore the data) however I’d love the Authors (as the writers and experts!) to either come up with, or at least review, the alt text and descriptions. I’m sure this chapter even more than most appreciates the importance of those!
So @max-ostapenko , @Tiggerito and @antoineeripret do you want to start working on the exporting of the images and the Figure markup ?
In the meantime Authors can finish off the final edits and then start converting the current text to Markdown (to be honest the figures are the most difficult part of that!) and then slot in the figure markup when ready.
That sound like a plan?
Also, one more thing, you’ll see at the top of the 2019 SEO Markdown that we need some extra pieces of meta data including: a short bio for each of the authors (shown at bottom of the chapter), a quote and three stats and labels (used on the front page in featured quote). Note these meta data need to be in HTML and not Markdown:
Happy to help here so let me know if you have any questions!
bazzadp
on 25 Nov 2020
Thanks for the clarification Barry.
-Mike
On Wed, Nov 25, 2020 at 4:37 PM Barry Pollard notifications@github.com
wrote:
We use both the images (mobile) and embedded Google sheets (desktop). We
have a Markup Function to take in both the image filename (which should be
added to Git) and the Sheets embed URL and it will display the appropriate
image depending on device size and device capabilities.You can see the 2019 SEO chapter makeup here (including examples of that
figure markup):
https://github.com/HTTPArchive/almanac.httparchive.org/blob/main/src/content/en/2019/seo.md
and that is converted at build time to this page:
https://almanac.httparchive.org/en/2019/seoI think the Analysts should export the images, and create the figure
markup as they know the Sheets, and SQL file for each sheet (we hope to
link both from each figure soon to allow readers to explore the data)
however I’d love the Authors (as the writers and experts!) to either come
up with, or at least review, the alt text and descriptions. I’m sure this
chapter even more than most appreciates the importance of those!So @max-ostapenko https://github.com/max-ostapenko , @Tiggerito
https://github.com/Tiggerito and @antoineeripret
https://github.com/antoineeripret do you want to start working on the
exporting of the images and the Figure markup ?In the meantime Authors can finish off the final edits and then start
converting the current text to Markdown (to be honest the figures are the
most difficult part of that!) and then slot in the figure markup when ready.That sound like a plan?
Also, one more thing, you’ll see at the top of the 2019 SEO Markdown
https://github.com/HTTPArchive/almanac.httparchive.org/blob/main/src/content/en/2019/seo.md
that we need some extra pieces of meta data including: a short bio for each
of the authors (shown at bottom of the chapter), a quote and three stats
and labels (used on the front page in featured quote). Note these meta data
need to be in HTML and not Markdown:Happy to help here so let me know if you have any questions!
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/HTTPArchive/almanac.httparchive.org/issues/908#issuecomment-733957111,
or unsubscribe
https://github.com/notifications/unsubscribe-auth/AAH6UV25K7YFFCFW27UUYM3SRV2JBANCNFSM4OJ2CRXA
.
--
Michael KingFOUNDER/MANAGING DIRECTOR
2020 Search Engine Land Awards Search Marketer of the Year
[email protected]
(347) 391-4266
We are a better performance marketing agency.
Just need marketing advice? Request a call here
http://clarity.fm/ipullrank.
[image: Runtime_Resource_Header.jpg]
Watch Runtime, https://ipullrank.com/runtime/ an iPullRank film on
Technical SEO tips and techniques.
ipullrank
on 25 Nov 2020
Oh and one more thing, the 2020 SEO Markdown file, with the meta data (some of it with TODO placeholders that we need you to fill in), has already been created for you here: https://github.com/HTTPArchive/almanac.httparchive.org/blob/main/src/content/en/2020/seo.md
Authors should review the team make up, and the TODOs in this meta data:
- Have we credited all the Authors, Reviewers and Analysts or have we missed some?
- Have some Authors, Reviewers and Analysts not been able to contribute after all? In which case, they should be removed to be fair to those who did make a significant contribution.
- What bios do you each want? 2019 SEO chapter example.
- What do you think would make good featured quote and stats for the home page to attract readers into your chapter? The 2019 SEO featured quote is shown below as an example:
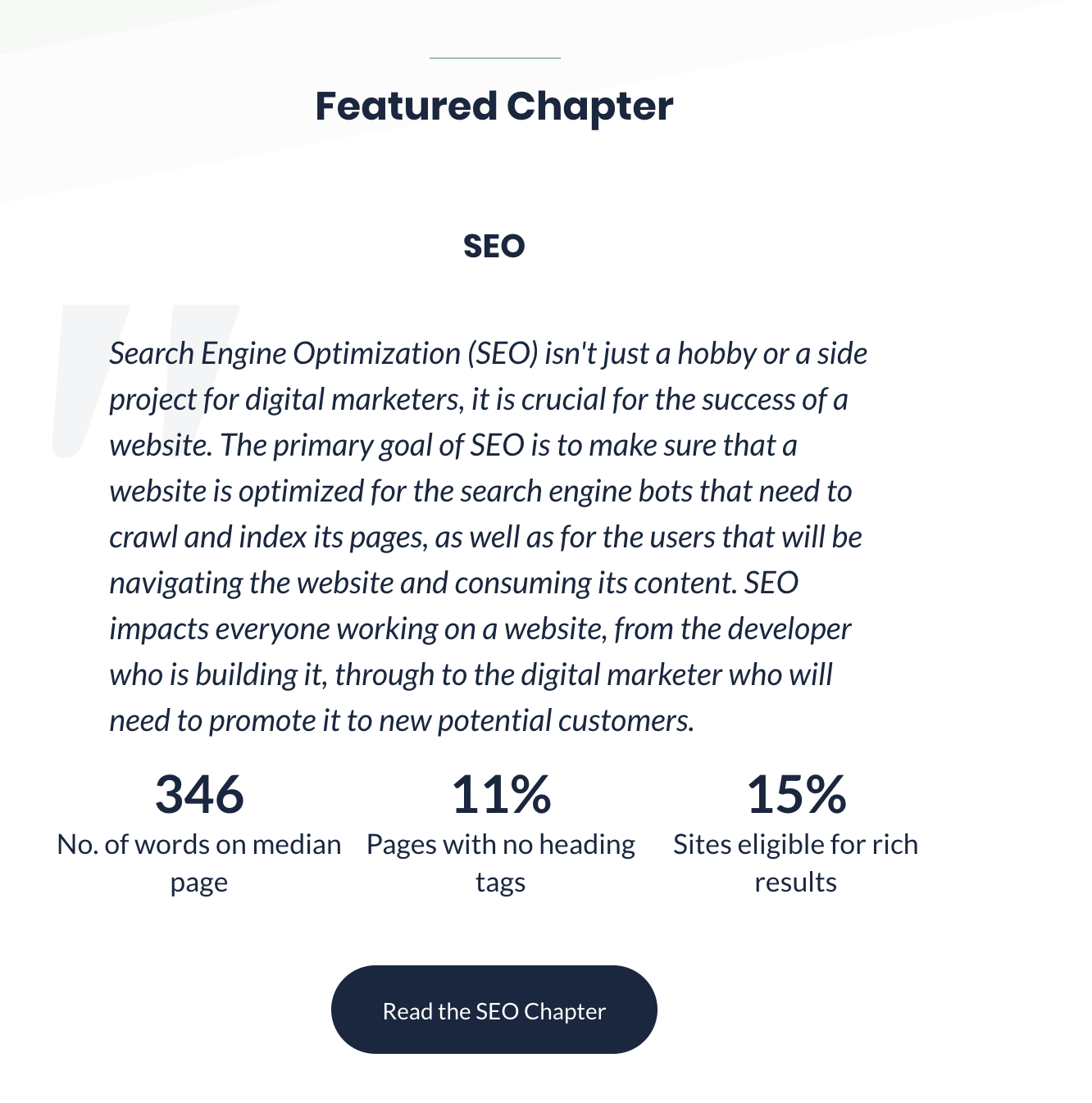
bazzadp
on 25 Nov 2020
Can I have suggest privilege in the document please? [email protected]
@Aleyda Solis aleydasolis@gmail.com
ᐧ
On Wed, Nov 25, 2020 at 9:50 AM Dave Smart notifications@github.com wrote:
Hey @aleyda https://github.com/aleyda, Rick was kind enough to let me
in!—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/HTTPArchive/almanac.httparchive.org/issues/908#issuecomment-733752834,
or unsubscribe
https://github.com/notifications/unsubscribe-auth/AA3WPDOISZ2QBV67XSFANUTSRUKTZANCNFSM4OJ2CRXA
.
--
David Sottimano
Independent Marketing Consultant
https://www.davidsottimano.com
[email protected]
dsottimano
on 26 Nov 2020
@dsottimano access granted :)
aleyda
on 26 Nov 2020
I have skimmed through the first few pages, suggested some changes, and provided some generic feedback. I would appreciate if @aleyda could revisit the rest of the document in the light of my primary comments so that I do not need to repeat the same ideas throughout. Here is a summary of common issues I noticed so far.
- Contractions were used frequently, which are often discouraged in technical writing
- Inconsistent use of Oxford commas
- Run-on sentences, often the whole paragraph consists of a single sentence
These [mostly stylistic] issues were limiting my reading speed. I will come back to again later when I have some time and will try to provide more substantial feedback beyond copy edits.
ibnesayeed
on 26 Nov 2020
Hi @ibnesayeed - I've been applying already what you have noted, I might have had a harder time on this since English is my third language, however as @rviscomi pointed out already in the document, the focus of the review should be rather in the technical side than the style since there will be editors later in the process reviewing that, so your time might be better spend on that :) Cheers!
aleyda
on 26 Nov 2020
@obto Please exclude me from the analysts on this chapter, as other guys did all the work here.
max-ostapenko
on 26 Nov 2020
I think the Analysts should export the images, and create the figure markup as they know the Sheets, and SQL file for each sheet (we hope to link both from each figure soon to allow readers to explore the data) however I’d love the Authors (as the writers and experts!) to either come up with, or at least review, the alt text and descriptions. I’m sure this chapter even more than most appreciates the importance of those!
So @max-ostapenko , @Tiggerito and @antoineeripret do you want to start working on the exporting of the images and the Figure markup ?
@bazzadp, several questions on that:
- How do you generate the chart_url argument included in last year chapter? I'm sure the answer is obvious but I'm not sure how the link is generated from the graph in Sheets.
- Regarding static images, where should we upload them? In the /src/static/images/2020 folder?
Thanks!
cc @Tiggerito
antoineeripret
on 26 Nov 2020
Unfortunately I was not involved in the markdown phase for the markup chapter. I think the authors did it all (phew!). So, at the moment I have no knowledge in this area 😢
The Markup chapter is mostly complete, so would be a good place to reference for best practices.
Tiggerito
on 26 Nov 2020
- How do you generate the chart_url argument included in last year chapter? I'm sure the answer is obvious but I'm not sure how the link is generated from the graph in Sheets.
In the top right hand corner of the chart in Sheets you should see three dots. Click on that and you get the option to Publish the chart:
On the next screen you want to click on Embed rather than Link. Click Publish, and you should be given an iFrame snippet including the src value that you are looking for.
- Regarding static images, where should we upload them? In the /src/static/images/2020 folder?
Correct, create a seo folder for this. Getting the highest resolution images here is a little tricky and I've detailed the recommended process here which does involve delving into dev tools if you're comfortable with that?
Unfortunately I was not involved in the markdown phase for the markup chapter. I think the authors did it all (phew!). So, at the moment I have no knowledge in this area 😢
Ah @Tiggerito for some reason I thought you did this for that chapter! OK I guess Authors did the work there. That explains why the SQL references were missing for that chapter (that you kindly added after I pointed this out!).
Well it's really up to yourselves as a chapter team how to handle this - Authors or Analysts. It seems to me, there's still some edits going on in the doc, and the conversion of that to Markdown will take a bit of effort for the Authors. So if @antoineeripret and @Tiggerito could take on the Figure markup part (including saving images to Git), then I'm sure that would be massively appreciated by the Authors and also make the whole thing quicker for the whole team. You can paste the relevant markdown code into the Google Doc after the graphs so Authors can review the Caption/Description/Alt text and then use that code when converting the chapter to Markdown.
bazzadp
on 27 Nov 2020
@bazzadp @Tiggerito: I'll take care of that between tomorrow and Sunday as today is a very busy day. There isn't that many images to generate so I don't think I'd spend that much time on that part.
That being said, @aleyda I may tag yourself and Mike / Jamie on the Google Docs to validate the captions / descriptions attributes I add for each of them, just to be sure you're confortable with the text I create :)
antoineeripret
on 27 Nov 2020
Perfect :) thanks @antoineeripret! Looking forward to your tags cc @ipullrank @fellowhuman1101
aleyda
on 27 Nov 2020
Hey Aleyda,
Sorry I am a bit late with my review with the US Holiday, I requested edit
access, but have not received it yet.
With the deadline past, I wanted to include my revisions here, but can also
edit the doc when access is given:
Original Line: Also, HTTPS is a requirement to capitalize on higher
performing protocols such as HTTP/2 and HTTP over QUIC aka HTTP/3.
Suggested Revision: Also, HTTPS is currently a requirement to capitalize
on higher performing protocols such as HTTP/2 and HTTP/3 (also known as
HTTP over QUIC).
Original Line: Images’ ALT attribute: This year, 53.855% of desktop and
51.22% of mobile home pages featured image alt attributes.
Suggested Revision: Images’ ALT attribute: This year, 53.86% of desktop and
51.22% of mobile home pages featured image alt attributes.
Overall, great work!
Thanks,
Dustin Montgomery
On Fri, Nov 27, 2020 at 4:25 AM Aleyda Solis notifications@github.com
wrote:
Perfect :) thanks @antoineeripret https://github.com/antoineeripret!
Looking forward to your tags cc @ipullrank https://github.com/ipullrank
@fellowhuman1101 https://github.com/fellowhuman1101—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/HTTPArchive/almanac.httparchive.org/issues/908#issuecomment-734736170,
or unsubscribe
https://github.com/notifications/unsubscribe-auth/ABV37MPSEGE6K5OVV5IELEDSR5WA5ANCNFSM4OJ2CRXA
.
en3r0
on 27 Nov 2020
Thanks @en3r0, really appreciate your feedback! I just applied your changes requests to the doc already. If you want I can give you access too, just let me know your email :)
aleyda
on 27 Nov 2020
I'm all done, left a few comments and sorry for being late. Great work folks!
dsottimano
on 28 Nov 2020
Thanks @dsottimano! Great input :) I've applied all your edits/requested. Regarding the Web Vitals metrics/explanations: please keep in mind the existence of the performance chapter, that will be the "main" source of information about this topic (so we should try to avoid overlaying too much) and to which we will refer/link to point out major concepts/metrics.
aleyda
on 28 Nov 2020
@aleyda, @bazzadp:
- Files added to a fork of the repository. Should I create a pull request to the main one?
- I added the markup code as a suggestion on the main Google Docs. You can review the content whenever you want. I mainly used extracts of the chapter - which was very descriptive - even though I sometimes rephrase it a little bit.
antoineeripret
on 28 Nov 2020
@antoineeripret spotted a few issues with the markup (my fault mostly for not telling you there are some differences from last year - sorry!). Made a comment against the first one but it applies to them all.
Could we create a branch in the main repo (called seo-chapter-2020 maybe?) and add these images and open a Draft PR? That way @aleyda could also add the markup to the same branch and then we can merge both together when all ready. If you use the main repo, rather than your fork, then you all will have edit rights to that branch so might be easier than trying to change permissions on your fork.
bazzadp
on 28 Nov 2020
@bazzadp: seen and understood! I'll apply the modifications later today and create the branch you just mentionned :)
antoineeripret
on 28 Nov 2020
@bazzadp:
- Draft PR created with the files (with better names as suggested)
- Markup code updated in the Google Docs following your instructions
@Tiggerito: I have not helped you at all on the Lighthouse metrics and I'm not sure that metrics displayed in our bar charts come from the lighthouse.sql query. Can you confirm that?
antoineeripret
on 28 Nov 2020
Good stuff @antoineeripret !
@aleyda is the chapter ready to move to Markdown yet or still want to change it in Google Docs? I can do a quick conversion tomorrow, add it to @antoineeripret ’s branch and pull request, then do a test release so you can get a feel for what it looks like. Then you can make any further edits in GitHub from then on until we’re happy to merge it.
bazzadp
on 28 Nov 2020
Thanks @antoineeripret :)
@bazzadp There are just a couple of comments/conversations pending at the moment: from @borisschapira that have been answered by @fellowhuman1101 - Could you please take a look Boris so we can move forward? Thanks a lot :)
aleyda
on 28 Nov 2020
@Tiggerito: I have not helped you at all on the Lighthouse metrics and I'm not sure that metrics displayed in our bar charts come from the lighthouse.sql query. Can you confirm that?
Those charts and associated data came from extra tabs added to the sheet. I think Jamie (@fellowhuman1101) added them.
Tiggerito
on 29 Nov 2020
@bazzadp There are just a couple of comments/conversations pending at the moment: from @borisschapira that have been answered by @fellowhuman1101 - Could you please take a look Boris so we can move forward? Thanks a lot :)
I think if that's the only thing we're waiting on we can move to Markdown. I've done that in #1589 and will pick up the conversation there.
bazzadp
on 29 Nov 2020
@bazzadp based on @borisschapira original feedback, I reworked the performance section to avoid duplication and focus relevancy to the SEO chapter audience.
cc: @rviscomi changes don't impact the markup
fellowhuman1101
on 30 Nov 2020
@Tiggerito: I have not helped you at all on the Lighthouse metrics and I'm not sure that metrics displayed in our bar charts come from the lighthouse.sql query. Can you confirm that?
Those charts and associated data came from extra tabs added to the sheet. I think Jamie (@fellowhuman1101) added them.
@Tiggerito they've been removed to avoid duplication of the performance chapter. (Were originally pulled from their workbook before the charts were revised to bar charts)
fellowhuman1101
on 30 Nov 2020
Have these changes been done in Google Docs or in the Markdown? If in Google docs could you copy your changes across to the Markdown version as that's the golden copy now?
bazzadp
on 30 Nov 2020
the Markdown version
Hi @bazzadp ! @fellowhuman1101 has just done these changes in the doc so I was going now to implement them in the markdown version... I'll do them now :)
aleyda
on 30 Nov 2020
Good stuff! I've just pushed a fix for some of the headings to that branch too so once you're done I'll generate another test version so we can see what it looks like now. Let me know when done.
bazzadp
on 30 Nov 2020
I just updated @fellowhuman1101 :) Can you please take a look at the markdown version? Thanks :D
cc @bazzadp it's done from my side - feel free to do additional updates :)
aleyda
on 30 Nov 2020
A background on the Structured Data data. I'll post it here because it's quite a bit of info. @ipullrank
In 2019:
Full data...
https://docs.google.com/spreadsheets/d/1uARtBWwz9nJOKqKPFinAMbtoDgu5aBtOhsBNmsCoTaA/edit#gid=1844385215
Microdata itemtype values were checked for.
JSON-LD @type values and an attempt to check @context to a max depth of 5
So no detection of untyped entities. For the results they just stripped out the context (I think most would have been missing) so the types could be for any vocabulary.
In 2020:
https://docs.google.com/spreadsheets/d/1ram47FshAjzvbQVJbAQPgxZN7PPOPCKIK67VJZCo92c/edit#gid=337739550
Contains basic comparison of raw and rendered
pct_has_raw_jsonld_or_microdata
pct_has_rendered_jsonld_or_microdata
pct_has_only_rendered_jsonld_or_microdata
pct_rendering_changes_structured_data
https://docs.google.com/spreadsheets/d/1ram47FshAjzvbQVJbAQPgxZN7PPOPCKIK67VJZCo92c/edit#gid=361660017
Formats used based on the rendered results. I also checked for rdfa and microformats2. Next time I think it would be worth checking of og/Facebook/Pinterest and twitter tags.
https://docs.google.com/spreadsheets/d/1ram47FshAjzvbQVJbAQPgxZN7PPOPCKIK67VJZCo92c/edit#gid=475182211
My version of the top entities based on the rendered results.
I implemented a more complex context builder so could reasonably accurately report on the vocabulary used. If my code could not work it out it would use http://complex-context.com/ or http://invalid-context.com/
I checked all entities and then looked for their type. Hence the -UnknownType- showing up. You may also see -ComplexType- (probably an array) or -InvalidType- (not a valid URI)
And a few other things which we may use in the future: id references and sameAs values
Notes
-UnknownType- is not bad. It gets treated as Thing in schema.org. A common scenario I see for this is for say an author where they only marked up the name. It can alos be legitimate if the site is using @id to merge information.
40% have JSON-LD or Mircodata. Between 1% and 2% are purely adding it via JavaScript. About 4.5% are altering it via JavaScript. JSON-LD is used more than Microdata.
WebSite and SearchAction should be at the top. They are used for the sitelink search box enhancement, I think the only rich snippet Google offers specifically for the home page, and few get it.
Most rich snippet features will not show on the home page. It looks like few are trying it on now (AggregateRating, Review).
Organization or any subtype makes sense on the home page. Google does check the logo, business hours, address etc.
data-vocabulary.org is going to be dropped in January. 0.37% Breadcrumbs were detected but who has a breadcrumb on the home page? Saying that almost 4% of home pages have schema.org breadcrumbs!
There's the odd typo, like incorrect case. I think Google lets you off.
I've the day off. I'll be around for a few hours before I have to go to the beach :-(
Tiggerito
on 1 Dec 2020
Related issues
ibnesayeed
·
5Comments
rviscomi
·
5Comments
 MSakamaki
·
6Comments
MSakamaki
·
6Comments
 AymenLoukil
·
4Comments
rviscomi
·
3Comments
AymenLoukil
·
4Comments
rviscomi
·
3Comments
Most helpful comment
Hi @clarkeclark @natedame @catalinred @aysunakarsu @ashleyish @dsottimano @dwsmart @en3r0 @Gathea @rachellcostello @ibnesayeed ... after a few last weeks of going through some last insights we wanted to confirm the SEO chapter Draft has been finished and is now ready for your revision :)
Please note:
Thanks and looking forward to your revisions :)
Thanks @obto and @rviscomi for the extra time and input in the last weeks with the request of extra data and again to the amazing @Tiggerito for his continuous support!