Allennlp: token_character_encoder dies with a sentence with short tokens
Describe the bug
Hi. token_character_encoder results in "RuntimeError: size must be non-negative", when
it is passed a sentence which consists of only short words (less than 5 characters).
This seems to have to do with cnn_encoder wrapped inside.
$ allennlp predict results/simple_tagger/model.tar.gz input.json
...
File "/home/cl/masashi-y/.pyenv_elm13/versions/3.7.0/lib/python3.7/site-packages/allennlp/modules/text_field_embedders/basic_text_field_embedder.py", line 88, in forward
token_vectors = embedder(*tensors)
File "/home/cl/masashi-y/.pyenv_elm13/versions/3.7.0/lib/python3.7/site-packages/torch/nn/modules/module.py", line 477, in __call__
result = self.forward(*input, **kwargs)
File "/home/cl/masashi-y/.pyenv_elm13/versions/3.7.0/lib/python3.7/site-packages/allennlp/modules/token_embedders/token_characters_encoder.py", line 36, in forward
return self._dropout(self._encoder(self._embedding(token_characters), mask))
File "/home/cl/masashi-y/.pyenv_elm13/versions/3.7.0/lib/python3.7/site-packages/torch/nn/modules/module.py", line 477, in __call__
result = self.forward(*input, **kwargs)
File "/home/cl/masashi-y/.pyenv_elm13/versions/3.7.0/lib/python3.7/site-packages/allennlp/modules/time_distributed.py", line 35, in forward
reshaped_outputs = self._module(*reshaped_inputs)
File "/home/cl/masashi-y/.pyenv_elm13/versions/3.7.0/lib/python3.7/site-packages/torch/nn/modules/module.py", line 477, in __call__
result = self.forward(*input, **kwargs)
File "/home/cl/masashi-y/.pyenv_elm13/versions/3.7.0/lib/python3.7/site-packages/allennlp/modules/seq2vec_encoders/cnn_encoder.py", line 105, in forward
self._activation(convolution_layer(tokens)).max(dim=2)[0]
File "/home/cl/masashi-y/.pyenv_elm13/versions/3.7.0/lib/python3.7/site-packages/torch/nn/modules/module.py", line 477, in __call__
result = self.forward(*input, **kwargs)
File "/home/cl/masashi-y/.pyenv_elm13/versions/3.7.0/lib/python3.7/site-packages/torch/nn/modules/conv.py", line 176, in forward
self.padding, self.dilation, self.groups)
RuntimeError: sizes must be non-negative
To Reproduce
This can be reproduced with simple_tagger example found in the tutorial.
Steps to reproduce the behavior
$ allennlp train -s results/simple_tagger ~/allennlp/tutorials/getting_started/walk_through_allennlp/simple_tagger.json
$ cat input.json
{"sentence": "I got out in 1987 ."} # This is a sentence from wsj_23
$ allennlp predict results/simple_tagger/model.tar.gz input.json
$ cat input2.json
{"sentence": "I got around in 1987 ."} # This works
$ allennlp predict results/simple_tagger/model.tar.gz input2.json
Expected behavior
It should work as it does for other sentences.
System (please complete the following information):
- OS: Ubuntu
- Python version: 3.7.0
- AllenNLP version: v0.7.0 cloned from master a few days ago
- PyTorch version: 0.4.1
Additional context
Add any other context about the problem here.
 masashi-y
masashi-y
All 4 comments
I guess it's due to that the cnn encoder requires a minimum of token length larger than the window width.
You can append some padding chars to every token to make sure the token is long enough. like:
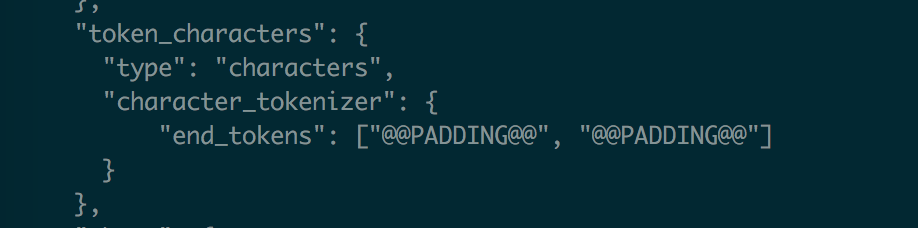
 qiuwei
on 12 Oct 2018
qiuwei
on 12 Oct 2018
Thanks @qiuwei. I'm closing this now, as that's the right solution here. @masashi-y, if you have more questions, feel free to re-open.
 matt-gardner
on 12 Oct 2018
matt-gardner
on 12 Oct 2018
@qiuwei Thank you for a nice workaround.
But I think this should be treated internally, or at least those config files using token_character_encoder be updated with that snippet.
Isn't that confusing that a user faces this error when she or he wants to evaluate a trained simple_tagger on PTB?
masashi-y
on 13 Oct 2018
It's a whole lot simpler in the code to have the user fix this in a config file, instead of trying to fix it after inputs have already been made into tensors. And it's pretty trivial to fix in the config file (more of a headache if you encounter it after you've already trained a model, but still not too bad - we do have the --overrides flag to most of our commands, or you can just modify the model archive).
Some of our config files have extra characters added, and some of them don't. If you want to submit a PR to modify them, that'd probably be fine.
matt-gardner
on 13 Oct 2018
Related issues
matt-gardner
·
3Comments
 onetonfoot
·
3Comments
onetonfoot
·
3Comments
 flyaway1217
·
4Comments
flyaway1217
·
4Comments
 lighteternal
·
4Comments
lighteternal
·
4Comments
 ghezalahmad
·
4Comments
ghezalahmad
·
4Comments
Most helpful comment
It's a whole lot simpler in the code to have the user fix this in a config file, instead of trying to fix it after inputs have already been made into tensors. And it's pretty trivial to fix in the config file (more of a headache if you encounter it after you've already trained a model, but still not too bad - we do have the
--overridesflag to most of our commands, or you can just modify the model archive).Some of our config files have extra characters added, and some of them don't. If you want to submit a PR to modify them, that'd probably be fine.