Is your feature request related to a problem? Please describe.
I would like to create an NER ensemble with other NER solutions.
For this, I need to feed in sentence- and word-tokenized sentences myself and I do not want the NER solutions to use their own tokenizers. Otherwise, this will result in inconsistent outputs.
Describe the solution you'd like
Is there a way to switch off any Allan NLP internal tokenization? I would just like to feed in a sentence-tokenized string where tokens have been separated by an empty space.
Describe alternatives you've considered
[Do not see any]
Additional context
[None]
 pwichmann
pwichmann
All 13 comments
I presume you're getting a Predictor for the NER model? If you've got one of those, you can just do:
predictor._tokenizer = JustSpacesWordSplitter() # only run this line once
json_output = predictor.predict(' '.join(tokens)) # then get your predictions like this for each instance
 matt-gardner
on 28 Aug 2018
matt-gardner
on 28 Aug 2018
Thank you!
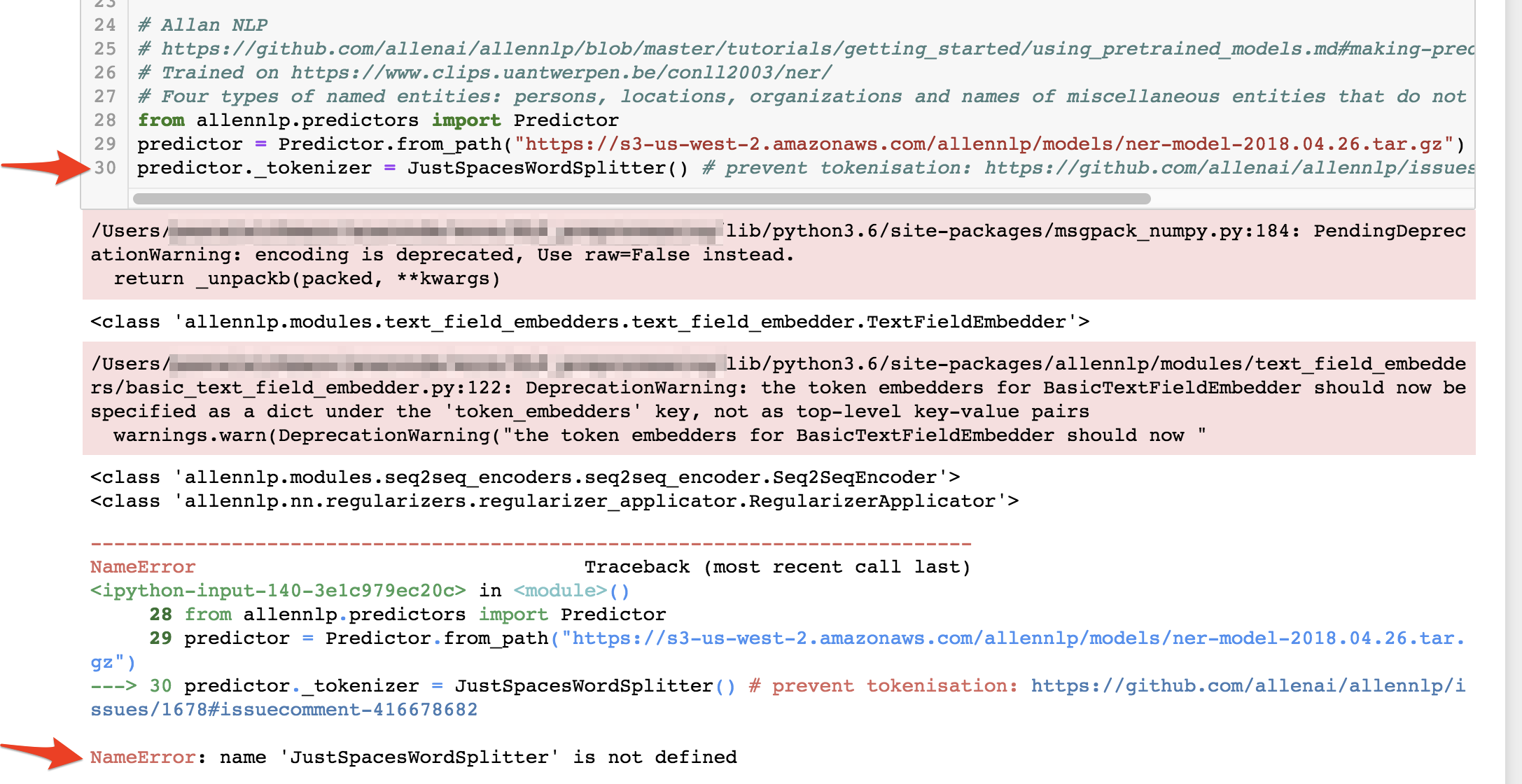
I ran into this issue. Am I doing this correctly?
pwichmann
on 28 Aug 2018
Oh, maybe I misunderstood. You suggested to plug in my own tokenizer for JustSpacesWordSplitter(), correct?
The error message may still say that it must be defined in token_embedders?
pwichmann
on 28 Aug 2018
You're going to have to import that word splitter first.
matt-gardner
on 28 Aug 2018
Sorry for consuming your time and my earlier mistake.
I corrected it - but I am running into new issues :(

pwichmann
on 28 Aug 2018
Something is wrong, because your line predictor._tokenizer = JustSpacesWordSplitter(word_tokenised_sentence_as_string) should be crashing. When I run that line, I get TypeError: object() takes no parameters.
matt-gardner
on 28 Aug 2018
When you declare the function JustSpacesWordSplitter(), what exactly do you define it to do?
I thought I would just re-use my own tokenizer and rename it JustSpacesWordSplitter(raw_sentence), so that it outputs the tokenised sentence as a single string.
So I declared it as: def JustSpacesWordSplitter(raw_sentence):
Sorry that I am so slow to understand.
pwichmann
on 28 Aug 2018
from allennlp.data.tokenizers.word_splitter import JustSpacesWordSplitter
matt-gardner
on 28 Aug 2018
THANK YOU!
That was the missing piece in the puzzle that is my brain.
Can I buy you a coffee?
pwichmann
on 28 Aug 2018
Glad you got it working =). I'm closing this issue now, feel free to re-open it if you have more questions.
matt-gardner
on 28 Aug 2018
I got an email with a question; maybe you deleted your comment. But the answer to the question is this: if you have an already-tokenized sentence, the easiest thing to do is to just do ' '.join(tokens), then pass that in using our JustSpacesWordSplitter, which will literally just call sentence.split(' '), undoing the ' '.join(tokens) and giving you back the original list. There are other ways you could solve this problem (like by writing your own WordSplitter), but this is definitely the easiest.
matt-gardner
on 29 Aug 2018
Hi @matt-gardner, I deleted my comment because I noticed how dumb I am.
I realised that the simple whitespace-based tokenizer is just what I need since I can feed in the word-tokenization result.
Thank you for you tremendous help!
pwichmann
on 29 Aug 2018
I needed to return the output of NER using character indicies in the following format:
{'text': "The rock-star Democrat Beto O'Rourke, a candidate for president, once supported the bulldozing of a low-income neighborhood in his hometown of El Paso-a project spearheaded by his father-in-law.",
'labels': [(14, 22, 'U-MISC'),
(23, 27, 'B-PER'),
(28, 36, 'L-PER'),
(143, 145, 'B-LOC'),
(146, 150, 'L-LOC')]}
While doing this in spacy was pretty straight forward because they provide start_char/end_char and allow going over multiple sentences....
import spacy
spacy_nlp = spacy.load("en_core_web_lg")
def ner_spacy(text):
doc = spacy_nlp(text)
labels = [(ent.start_char, ent.end_char, ent.label_,) for ent in doc.ents]
return {"text": text, "labels": labels}
....I had a bit of trouble doing this with allennlp:
from allennlp.predictors.predictor import Predictor
from allennlp.data.tokenizers.whitespace_tokenizer import WhitespaceTokenizer
allennlp_models = "https://s3-us-west-2.amazonaws.com/allennlp/models/"
allennlp_ner_model = allennlp_models + "ner-model-2018.12.18.tar.gz"
allennlp_predictor = Predictor.from_path(allennlp_ner_model)
allennlp_predictor._tokenizer = WhitespaceTokenizer()
def ner_allennlp(text):
# Github Issue shows how to use external tokenized text
# https://github.com/allenai/allennlp/issues/1678
text = text.strip()
doc = spacy_nlp(text)
labels = []
index = 0
sents = list(doc.sents)
for sent in tqdm(sents):
# DEBUG
# print(len(sent.text_with_ws), repr(sent.text_with_ws))
tokens = list(sent)
# without the below check, I run into:
# RuntimeError: Calculated padded input size per channel: (1). Kernel size: (3). Kernel size can't be greater than actual input size
if all(x.is_space or x.is_punct for x in tokens):
index += len(sent.text_with_ws)
else:
sent_counter = 0
string_tokens = [str(x) for x in tokens]
obj = allennlp_predictor.predict(sentence=" ".join(string_tokens))
# hack to re-insert new line characters as individual tokens
# into the allennlp output if there is a newline character
# in the middle of a `sent`
new_line_indicies = [i for i, x in enumerate(string_tokens) if x.strip(' ') == "\n" or x.strip(' ') == '\xa0']
if len(string_tokens) != len(obj["words"]) and len(new_line_indicies) > 0:
for i in new_line_indicies:
obj["words"].insert(i, string_tokens[i])
obj["tags"].insert(i, "O")
# DEBUG:
# print(new_line_indicies)
# print(string_tokens)
# print(obj["words"])
for i, (tag, word, token) in enumerate(zip(obj["tags"], obj["words"], tokens)):
if word != str(token):
raise Exception(f"{word} != {token}")
if tag != "O":
label = (index, index + len(token), tag)
labels.append(label)
index += len(token.text_with_ws)
sent_counter += len(token.text_with_ws)
# DEBUG:
# print(text[label[0]:label[1]], label[2], repr(token.text_with_ws))
else:
# for some reason, the end punctuation of the sentence does not include
# the newline character in `token.text_with_ws` but the newline is included
# in the sent.text_with_ws. so we just add the remaining characters to
# increment the index to the next sentence
index += len(sent.text_with_ws) - sent_counter
return {"text": text, "original_labels": labels, "labels": labels}
Do you have any ideas on how to make this a little easier?
Basically I want to take a document and NER the entire thing giving me the character indicies in the original document for each entity.
 AlJohri
on 19 Dec 2019
AlJohri
on 19 Dec 2019
Related issues
 ghezalahmad
·
4Comments
ghezalahmad
·
4Comments
 Andy-jqa
·
3Comments
Andy-jqa
·
3Comments
 stefan-it
·
4Comments
stefan-it
·
4Comments
 shounakpaul95
·
4Comments
matt-gardner
·
3Comments
shounakpaul95
·
4Comments
matt-gardner
·
3Comments
Most helpful comment
I got an email with a question; maybe you deleted your comment. But the answer to the question is this: if you have an already-tokenized sentence, the easiest thing to do is to just do
' '.join(tokens), then pass that in using ourJustSpacesWordSplitter, which will literally just callsentence.split(' '), undoing the' '.join(tokens)and giving you back the original list. There are other ways you could solve this problem (like by writing your ownWordSplitter), but this is definitely the easiest.