Alertmanager: "dropping messages because too many are queued" error in a single-node cluster
It appears that AlertManager in a single-node setup will try to broadcast silences and notification logs to itself. The messages are queued forever, leading to the aforementioned error message when it reaches the max queue size. A workaround is to start AlertManager with --cluster.listen-address="" which disables clustering altogether.
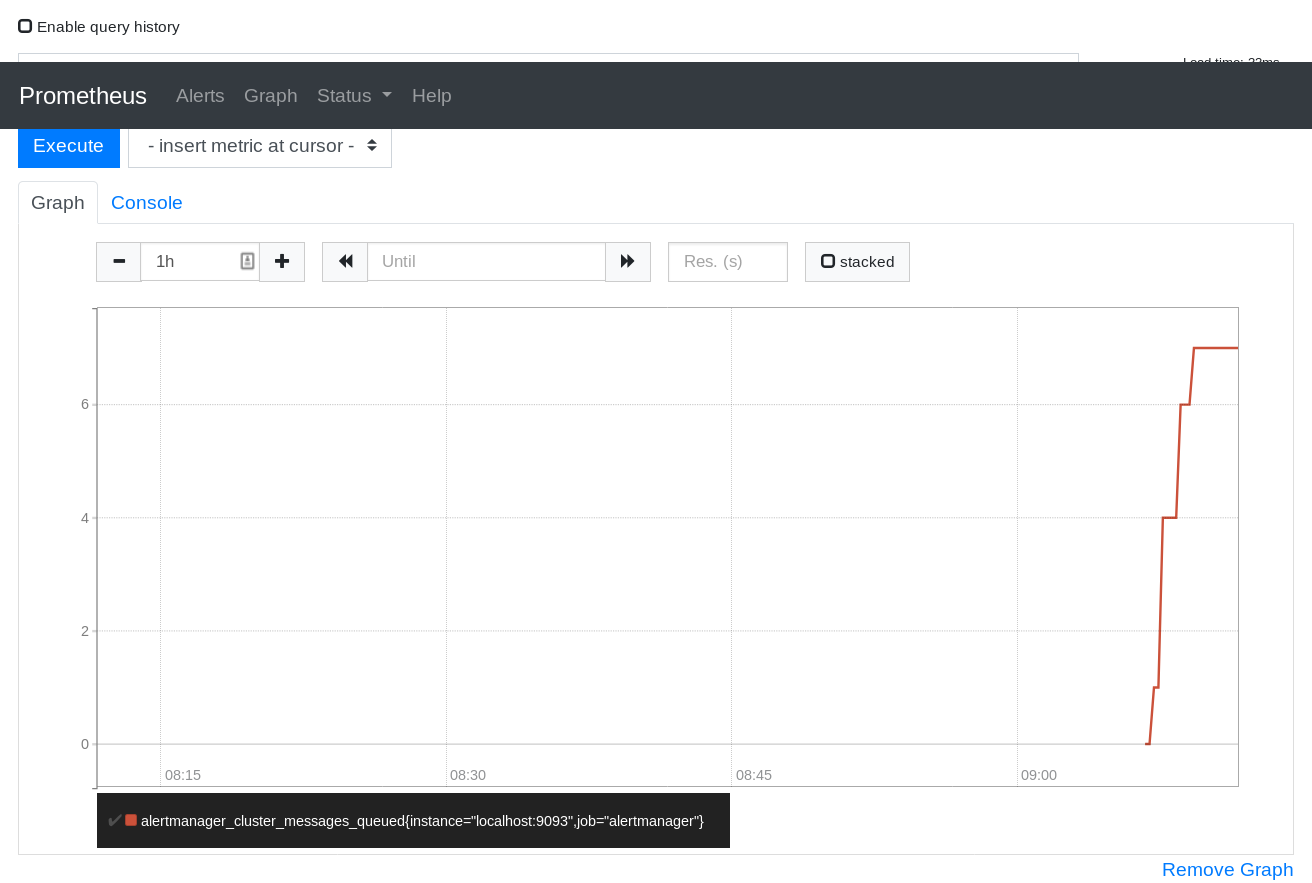
Reported by @sylr on IRC and reproduced on master.
 simonpasquier
simonpasquier
All 12 comments
Hm, I'm curious why this only happens in a single node context. I guess I would have to look at memberlist again. This is something handled within memberlist, since it selects peers to send to based on its current list.
 stuartnelson3
on 27 Mar 2019
stuartnelson3
on 27 Mar 2019
I've not tested in a multi-node setup but I've assumed that you didn't notice the problem at SC ;-)
simonpasquier
on 27 Mar 2019
yeah, checking our alertmanager dashboard, we don't have any queued messages in our 3-node setup.
stuartnelson3
on 27 Mar 2019
it will not let "" in 0.17
only list is accepted
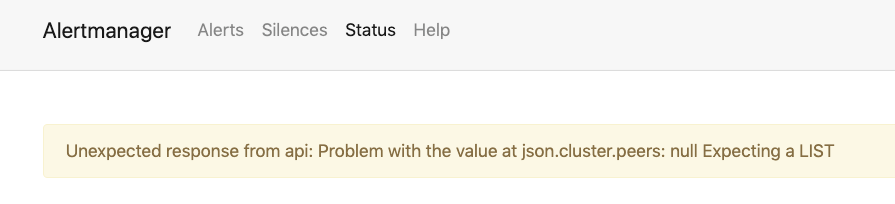
 yosefy
on 3 Jun 2019
yosefy
on 3 Jun 2019
@yosefy I've tested with 0.17.0 and it works fine for me. This has been fixed by https://github.com/prometheus/alertmanager/pull/1732 which is part of 0.16.1.
simonpasquier
on 4 Jun 2019
I've also investigated a bit the issue and I think it works as expected. We have no way to determine that the cluster size won't increase in the future as a remote node may connect at a any time. In which case the queue will be emptied. And we already prune the messages to avoid unbounded queues:
We should probably still document this in the AlertManager's documentation.
simonpasquier
on 4 Jun 2019
In the case that we alert on such instances, what would be the recommended resolution steps?
 aditya-konarde
on 26 Jun 2019
aditya-konarde
on 26 Jun 2019
If you're running in HA mode, try to troubleshoot why your nodes aren't able to send gossip messages. If you're running a single instance, you can turn off HA mode.
stuartnelson3
on 26 Jun 2019
I have very silly question, but how to turn off HA mode?
We set only those flags, but still we have spam of warnings like in this issuse, for gossip queue.
"--log.level": "info",
"--config.file": path.Join(alertmanagerConfigVolumeMount, alertmanagerConfigFile),
"--storage.path": alertmanagerDataVolumeMount,
"--data.retention": "120h",
We run v0.17+
 bwplotka
on 23 Jul 2019
bwplotka
on 23 Jul 2019
@bwplotka the trick is to set --cluster.listen-address="".
simonpasquier
on 23 Jul 2019
Awesome, thanks for the quick response.
I would make it a bit more explicit as proposed here: https://github.com/prometheus/alertmanager/pull/1971 and close this issue (:
bwplotka
on 23 Jul 2019
For those who might end up here, I found out that in kubernetes --cluster.listen-address="" does not work, but --cluster.listen-address= does.
 sylr
on 3 Aug 2020
sylr
on 3 Aug 2020
Related issues
stuartnelson3
·
5Comments
 svenmueller
·
5Comments
svenmueller
·
5Comments
 MaT1g3R
·
5Comments
MaT1g3R
·
5Comments
 pborzenkov
·
5Comments
pborzenkov
·
5Comments
 fchiorascu
·
5Comments
fchiorascu
·
5Comments