We previously had the benchmark on activation custom ops against C++/CUDA kernel, pure python, pure python with tf.function, and pure python with XLA.
The results that C++ kernel on CPU is much slower than others are quite surprising to me. However, seems that we can achieve some optimization by compiler flags. While compiling cc files, the flags we use now are listed down below. It shows that we miss the basic/most important optimization -march=native, which enables most of optimizations of SIMD on CPU ISA.
/usr/bin/gcc -U_FORTIFY_SOURCE -fstack-protector -Wall -Wunused-but-set-parameter -Wno-free-nonheap-object -fno-omit-frame-pointer -g0 -O2 '-D_F
ORTIFY_SOURCE=1' -DNDEBUG -ffunction-sections -fdata-sections '-std=c++0x' -MD -MF bazel-out/k8-opt/bin/tensorflow_addons/custom_ops/image/_objs/_
image_ops.so/image_projective_transform_op.pic.d '-frandom-seed=bazel-out/k8-opt/bin/tensorflow_addons/custom_ops/image/_objs/_image_ops.so/image_
projective_transform_op.pic.o' -fPIC -iquote . -iquote bazel-out/k8-opt/bin -iquote external/local_config_tf -iquote bazel-out/k8-opt/bin/external
/local_config_tf -iquote external/bazel_tools -iquote bazel-out/k8-opt/bin/external/bazel_tools -isystem external/local_config_tf/include -isystem
bazel-out/k8-opt/bin/external/local_config_tf/include -pthread '-std=c++11' '-D_GLIBCXX_USE_CXX11_ABI=0' -fno-canonical-system-headers -Wno-built
in-macro-redefined '-D__DATE__="redacted"' '-D__TIMESTAMP__="redacted"' '-D__TIME__="redacted"' -c tensorflow_addons/custom_ops/image/cc/kernels/i
mage_projective_transform_op.cc -o bazel-out/k8-opt/bin/tensorflow_addons/custom_ops/image/_objs/_image_ops.so/image_projective_transform_op.pic.o
The comparison between pure python with XLA and C++ kernel on CPU is shown in the following table and in the link:
Without -march=native
| | gelu | hardshrink | lisht | mish | softshrink | tanhshrink |
| --- | --- | --- | --- | --- | --- | --- |
| forward | XLA | XLA | XLA | XLA | XLA | XLA |
| backward | C++ | XLA | XLA | XLA | C++ | C++ |
With -march=native
| | gelu | hardshrink | lisht | mish | softshrink | tanhshrink |
| --- | --- | --- | --- | --- | --- | --- |
| forward | C++ | XLA | C++ | XLA | XLA | Tie |
| backward | C++ (8X) | XLA | C++ | XLA | C++ | C++ |
For those C++ kernels that are still very slow, I doubt Eigen has less optimization on complicated expression tree (for mish), or the logical OR op (for hardshrink and softshrink).
Note that this flag is used for --config=opt for tensorflow release.
https://github.com/tensorflow/tensorflow/blob/master/configure.py#L530
https://github.com/tensorflow/tensorflow/blob/master/tensorflow/tools/ci_build/release/ubuntu_16/cpu_py36_full/pip.sh
 WindQAQ
WindQAQ
All 26 comments
Probably related to #1148.
WindQAQ
on 24 Apr 2020
I think that we will have performance improvements on CPU if we use MKL (Intel CPU), OPENBLAS (Multiarch).
See:
https://github.com/xianyi/OpenBLAS/issues/2133#issuecomment-492200909
https://github.com/tensorflow/tensorflow/issues/18457
 bhack
on 24 Apr 2020
bhack
on 24 Apr 2020
Results with intel-tensorflow==2.1.0
bhack
on 24 Apr 2020
I have some doubt about what this package is using:
From the official comment at https://github.com/oneapi-src/oneDNN/issues/652#issuecomment-587589870 seems that it is just MKL-DNN and not Eigen with MKL.
bhack
on 24 Apr 2020
@WindQAQ we had a discussion some time ago that the custom cuda kernels can be tricky when it comes to TPU. So, should we have a switch corresponding to the device on which the op is going to run or should we just stick with pure python + XLA because we know that it would work everywhere?
cc: @seanpmorgan @gabrieldemarmiesse
 AakashKumarNain
on 24 Apr 2020
AakashKumarNain
on 24 Apr 2020
I'd be in favor of running benchmarks on real world models (training loop with model.fit), like vgg16, reset50, mobilenet replacing all relu activations by one of our activations.
If we see that the speed increase of custom ops, cuda and c++ with --march=native is less than 5% compared to pure python, I'd be in favor of setting the flag TF_ADDONS_PY_OPS to True by default on all OS (because for the moment, this flag has only an effect on activations) and possibly drop the custom ops implementations of activations.
We gain a lot in compatibility, compiling time and maintenance, which I believe is more important than speed to a certain extent.
 gabrieldemarmiesse
on 24 Apr 2020
gabrieldemarmiesse
on 24 Apr 2020
Well, I am not going to say that C++ kernel is superior to python ops. Just want to point out we have some other optimization that we can do at least in current build. The numeric results are not used to convince the community that we should or we must use C++ kernels over python ops, but are used to show we miss the important compiler flags that can improve the performance a lot :-)
I am very free to drop C++ ops if they are less performance/hard to maintain. However, C++ kernels are still necessary in many ways (like our layers/image) when it comes to the fact that it's not easy or possible to express operations as a composition of existing ops; otherwise, there won't be C++ kernels anywhere in the TF or even pytorch.
Thank you.
WindQAQ
on 24 Apr 2020
Sure, I was referring to dropping custom ops of activations, I phased badly what I wanted to say, I edited my message. For sure we're not going to drop anything without giving our users a better alternative.
gabrieldemarmiesse
on 24 Apr 2020
@WindQAQ sorry if that sounded in bad way. Actually this was pointed out in a discussion with the model garden team. Just wanted to point that out
AakashKumarNain
on 24 Apr 2020
@WindQAQ My GELU forward is very different with Tensorf 2.2.0RC3 with tf.config.experimental.enable_mlir_bridge():
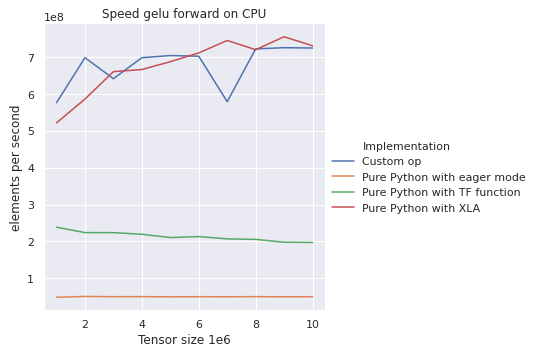
bhack
on 25 Apr 2020
Also thanshrink forward:
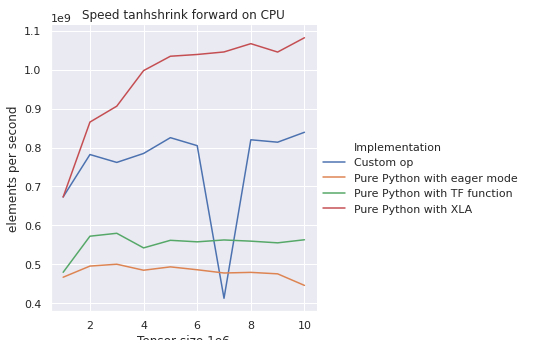
bhack
on 25 Apr 2020
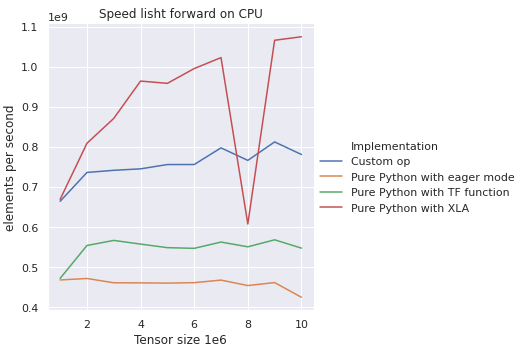
bhack
on 25 Apr 2020
@bhack Sounds great! XLA + MLIR seems to be the best combination for easily fused ops!
WindQAQ
on 25 Apr 2020
Mhhh I don't know if tf.config.experimental.enable_mlir_bridge() has any effect on CPU. I see that API is documented only for TPU.
bhack
on 25 Apr 2020
Sorry there was something strange in the colab run. This is tf-nightly:
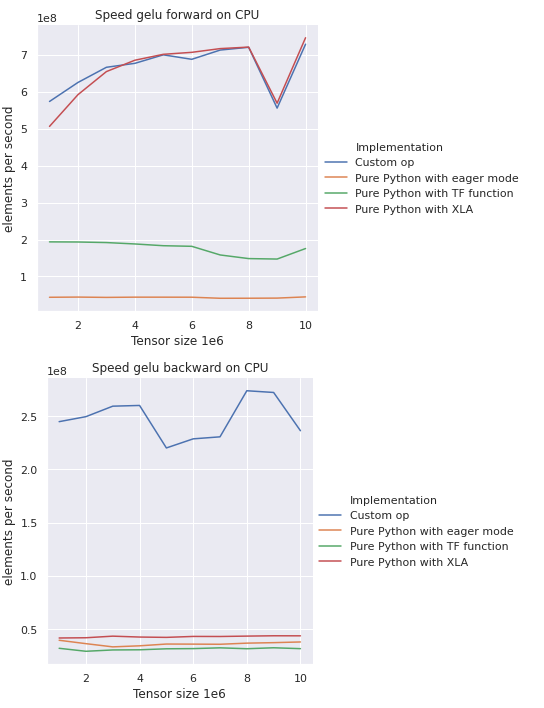
bhack
on 26 Apr 2020
@WindQAQ Are you sure the you test is ok with backward? Cause with ŧf.nightly all the XLA forward are faster and just one on par with custom op but seems to that there is instead a large gap with backwards.
bhack
on 26 Apr 2020
@WindQAQ Are you sure the you test is ok with
backward? Cause withŧf.nightlyall the XLA forward are faster and just one on par withcustom opbut seems to that there is instead a large gap withbackwards.
@bhack I guess it's because of the latest stable release tensorflow==2.1.0. Your benchmark is right with tf-nightly.
WindQAQ
on 26 Apr 2020
Yes but why all the XLA forwards are Faster then custom_ops and instead backwards are performing so bad?
bhack
on 26 Apr 2020
Yes but why all the XLA forwards are Faster then custom_ops and instead backwards are performing so bad?
The script is borrowed from the previous issue, and I think it's correct. IMO, this is because kernel fusion on the backward part is more complicated. Think about the simplest chain rule
f(g(x))' = f'(g(x)) g'(x)
Autodiff will compute gradient following this kind of rule, so the backward part will be decomposed into multiple ops g(x) f'(x) g'(x) for the simple composition of functions.
If one of the component is not fused, then there will be additional overhead of kernel launch and memory moving. Maybe XLA is good but not perfect enough (I do not validate the IR generated by XLA and custom ops though). Just my guess please correct me if it's wrong LOL.
WindQAQ
on 26 Apr 2020
Yeah, I think fusion can be one of the reasons. JAX relies on XLA for almost everything. Should we run a benchmark with JAX as well to see if it's really XLA or something else?
AakashKumarNain
on 26 Apr 2020
I was looking at the composite ops accepted RFC.
In the Appendix I see:
This proposal is concerned with optimiziging inference pass of composite ops . The motivation today is that the downstream tooling today rarely if ever deals with gradients, and when it does, it can rely on the provided implementation. However eventually this is likely to change, and we would like to keep the door open for extending this composite op framework to support optimization of both forward and backward passes. In this appendix we provide several options of how this could be potentially supported in the future, for the reference purposes.
bhack
on 26 Apr 2020
/cc @marksandler2
bhack
on 26 Apr 2020
@seanpmorgan What do you have extracted from https://github.com/tensorflow/tensorflow/pull/33945#issuecomment-617832325 and follow-up comments? Shall we to ask to contributors to write MLIR legalization passes for every compositional op?
bhack
on 26 Apr 2020
@seanpmorgan What do you have extracted from tensorflow/tensorflow#33945 (comment) and follow-up comments? Shall we to ask to contributors to write
MLIR legalization passesfor every compositional op?
So we should only need MLIR legalization passes for custom-ops not python compositional ops I believe. This is a moving target and hard for us to create requirements for. I'm in favor of not requiring all custom-ops support TPU/GPU/CPU since the procedure for doing so is not concrete.
 seanpmorgan
on 1 May 2020
seanpmorgan
on 1 May 2020
@seanpmorgan My quick impression is that writing a "MLIR legalization" pass probably it is super easy for the average developer involved in compilers stuffs but it could be really a barrier for early/average Addons contributors.
bhack
on 1 May 2020
In the monthly meeting, we agreed to drop the activation custom ops due to all the reasons cited above. See #1775 for the follow-up where the timeline is discussed. I'll leave this issue open as using compiler flags can be relevant for other custom ops.
gabrieldemarmiesse
on 2 May 2020
Related issues
 pikaliov
·
3Comments
pikaliov
·
3Comments
 iskorini
·
4Comments
iskorini
·
4Comments
 ididhmc
·
4Comments
seanpmorgan
·
3Comments
seanpmorgan
·
4Comments
ididhmc
·
4Comments
seanpmorgan
·
3Comments
seanpmorgan
·
4Comments