Addons: Accuracy on CIFAR_10 by Condition Gradient only 10 %
System information
- OS Platform and Distribution (e.g., Linux Ubuntu 16.04):Windows
- TensorFlow version and how it was installed (source or binary):1.15.0
- TensorFlow-Addons version and how it was installed (source or binary):0.9.0.dev0
- Python version:3.7.5
- Is GPU used? (yes/no):no
Describe the bug
I watch this paper https://arxiv.org/pdf/1803.06453.pdf and I want to implement it,and I use the tensorflow-addon, I follow the rule and test it on tutorial here https://github.com/tensorflow/addons/blob/master/docs/tutorials/optimizers_conditionalgradient.ipynb
which is a MINIST dataset, and the accuracy is perfect. However, I want to implement on CIFAR-10
,and I always get the bad loss(100-500) and bad accuracy(0.09-0.1) so i want to ask if I have done wrong?
Code to reproduce the issue
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same',
input_shape=X_train.shape[1:]))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(10))
model.add(Activation('softmax'))
model.compile(optimizer=tfa.optimizers.ConditionalGradient(
learning_rate=0.1, lambda_=1000),
loss='categorical_crossentropy',
metrics=['accuracy'])
history_cg = model.fit(
X_train,
y_train,
batch_size=batch_size,
validation_data=(X_test, y_test),
epochs=epochs,)
here is my implement and model parameter and i want to know if there is anyone success run CIFAR-10 dataset with well accuracy? Thanks!
 johnnylin110
johnnylin110
All 5 comments
CC @pkan2
 seanpmorgan
on 4 Mar 2020
seanpmorgan
on 4 Mar 2020
CC @pkan2
do you mean paste the code instead of picture? I replace it
I still can't train it
Hope there is a answer .Thanks
johnnylin110
on 6 Mar 2020
Sorry I just meant to add the codeowner to take a look. @pkan2 do these result look as expected?
seanpmorgan
on 9 Mar 2020
@seanpmorgan @pkan2
Well, I found that when the learning rate set to 0.99999 can produce high accuracy.
but in the paper [https://arxiv.org/pdf/1803.06453.pdf],the learning rate is set to 0.0001,0.000001,0.000001. but if I use those learning rate it become worse just like I mention above
And I go to the optimizer\condition_gradient.py the update function is
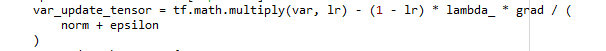
which is the same as this formula
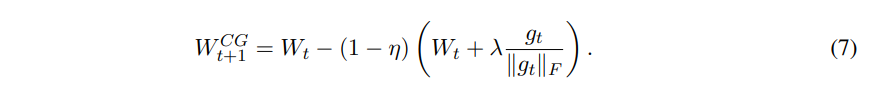
and if the formula is the same, how come the learning rate are different?
johnnylin110
on 9 Mar 2020
@johnnylin110 @pkan2 It is a typo in the paper.
It should be (1-\eta) \in {0.0001,0.000001,0.000001} in Fig 1. of https://arxiv.org/pdf/1803.06453.pdf
You can also check the code associated with the paper which is available here https://github.com/lokhande-vishnu/deepcg/tree/master/resnet-in-tensorflow
 lokhande-vishnu
on 11 Mar 2020
lokhande-vishnu
on 11 Mar 2020
Related issues
seanpmorgan
·
3Comments
seanpmorgan
·
4Comments
 shun-lin
·
4Comments
seanpmorgan
·
3Comments
seanpmorgan
·
4Comments
shun-lin
·
4Comments
seanpmorgan
·
3Comments
seanpmorgan
·
4Comments